Abstract
sigmoid, hyperbolic tangent 함수보다 더 좋은 rectifying neuron에 대해 소개한다. 두 활성함수에 비해,
- multi-layer neural network에서도 학습이 잘 됨
- 생물학적 뉴런을 더 잘 표현한 모델
- sparse data에 대한 학습이 더 뛰어남
- supervised task에서의 성능이 더 높음 (unlabeled data로 unsupervised pre-training을 하지 않아도 뛰어난 성능을 보임)
1. Introduction
- machine learning 과 neuroscience 에서의 신경망 모델은 다르지만,
Rectifier activation function : 을 통해 두 분야를 연결할 수 있다.
- 포유류의 시각 피질의 process와 유사
-
각각의 요소들이 서로 다른 방식으로 이미지를 처리함
-
서로 다른 표현을 담당하며, 점차 복잡한 특성을 인식
-
edges, primitive shapes => more complex shapes
=> deep architecture가 학습하는 feature가 시각 피질에서 관찰되는 것과 닮아있음
-
Hyperbolic tangent, sigmoid 대신에 retifier activation function 을 사용할 것 을 제안하며, 추가적으로 L1 정규화를 적용함
2. Background
neuroscience models vs machine learning models
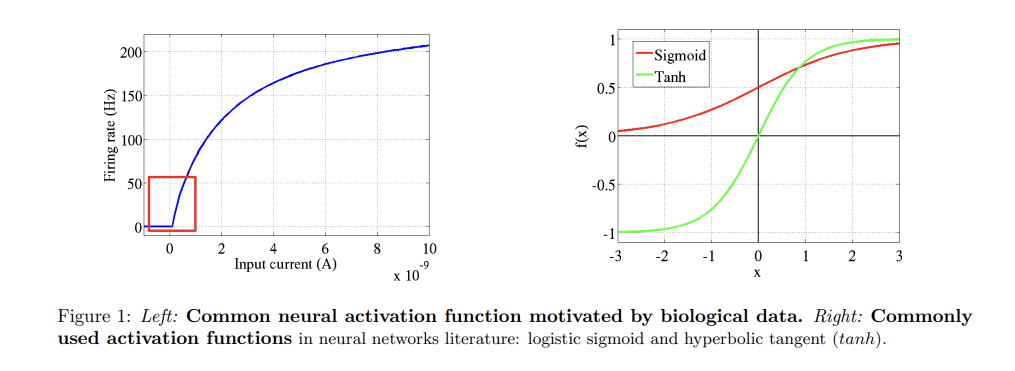
생물학에서의 뉴런의 특징을 언급하며 기존에 신경망에 사용하던 sigmoid, tanh와 뉴런을 비교하여 그 차이점을 제시하고 있다.
- sparsity
- 실제 뇌에서 활성화되는 뉴런은 1-4% 정도에 달함 (에너지 소모 vs 풍부한 표현의 tradeoff)
- 이런 sparsity를 신경망은 구현하지 못하므로, L1 정규화를 통해 추가적으로 구현
ex) sigmoid
초기 가중치가 작을 때에는 뉴런의 입력 값이 대부분 중간 영역(즉, 0에 가까운 값)으로 설정되기 때문에, 그 결과 시그모이드 함수의 출력 값이 1/2 근처에서 유지되고, 포화 상태가 됨 => 생물학적으로 불가능한 일이다
- 생물학의 활성함수 vs Tanh, Sigmoid
- 생물학의 활성함수는 비선형적
- Tanh는 반대칭성(antisymmetry) :
입력값이 양수일 때와 음수일 때 반대 방향의 출력을 준다.
=> 하지만 이러한 반대칭성은 생물학적 뉴런에서는 나타나지 않음. 실제 뉴런들은 입력에 따라 그저 활발하게 발화하거나 발화하지 않지만, 쌍곡선 탄젠트 함수처럼 입력 값의 부호에 따라 대칭적인 반응을 보이지 X
Advantages of Sparsity
Tanh, sigmoid는 0에서 1 또는 -1에서 1 사이의 값으로 매핑하기 때문에, 입력이 아주 작아도 뉴런들이 완전히 비활성화되지 않고, 작은 활성화 값을 유지한다. 따라서, 뉴런의 활성화 값이 완전한 0이 아닌 상태로 남아 있는 경우가 많은데, rectifier neuron은 실제 0의 값을 가지게 하며 따라서 sparse representation을 가능하게 한다.
장점1. 정보 분리
- sparse and robust representation 을 가지게 함.
- 모델의 중요한 요인들만을 강조하고, 특성들이 서로 독립적이게 되어 입력의 작은 변화가 있더라도 대체로 특징이 보존된다.
장점2. 다양한 크기의 표현에 효율적임
- 모든 입력이 같은 양의 정보를 가지고 있는 것은 아니다. 서로 다름.
- 활성 뉴런 수를 조절하여 다양한 크기의 입력들에 대해 차원과 정밀도를 조절할 수 있음.
(활성 뉴런 수가 많아질수록 더 복잡하고 정밀한, 높은 차원에서의 표현이 가능하다)
장점3. 선형 분리가 가능하다
- 희소표현은 선형적으로 분리될 가능성이 더 높다.
- 또한 정보가 고차원의 공간에 표현되기 때문에, 원시 데이터의 형식을 반영하기에 유리하다.
장점4. distributed but sparse
- 물론 dense distributed한 표현이 가장 정보가 풍부하지만, sparse한 표현의 효율성이 더 크다.
3. Deep Rectifier Networks
3.1 Rectifier Neurons
한쪽 방향만 활성화 되도록하여 대칭(symmetry)이나 반대칭(antisymmetry)를 방지. 그러나 두 개의 rectifier unit을 합성하여 symmetry,antisymmetry를 구현할 수도 있다.
장점
- sparse representation을 얻기 쉽다
대략 50%의 유닛의 출력값이 0이므로, 수학적으로도 효율적이며, 생물학적으로 유사해진다. - 부분적으로 선형적이다
비선형성이 path selection에서만 발생한다(각 뉴런들이 활성화 되는지/아닌지에 대한 비선형성). 입력은 모두 선형함수(x)를 통과하므로 선형적이다. 전체 모델은 파라미터를 공유하는 지수적인 갯수의 선형 모델이라고 볼 수 있다. - gradient vanishing 문제를 해결할 수 있다.
선형적이므로 미분시 기울기 소실 문제가 나타나지 않음. 계속 곱해도 변화율이 기하급수적으로 작아지지 않는다. - 계산 효율성이 높다.
활성함수 계산에서 지수함수 계산이 필요하지 않아 더 효율적이다.
문제점과 해결방안(+가설)
[ Problem1 : hard saturation ]
hard saturation이란 입력값이 0일때 출력이 항상 0이되어 해당 가중치의 업데이트가 이루어지지 않는 것이다.
solution : softplus
=> 그러나 실증적 결과에 의하면 오히려 hard zeros 가 지도학습에 큰 도움이 되었다
Hypothesis : 그래디언트가 전파가 될 수 있는 한, hard zero에 의한 비선형성이 문제되지 않는다. 또한 최적화가 용이하다.
[ Problem2 : unbounded behavior ]
rectifier는 입력이 무한히 클 때 출력도 무한히 커지는 특성을 가지고 있다. 이로 인해 계산에서 값이 너무 커질 수 있다.
solution : L1 regularization
[ Problem3 : ill-conditioning ]
ill-conditioned system은 작은 입력 변화에 대해 큰 출력을 초래하거나, 계산 결과가 불안정해지는 경우를 나타낸다. 매개변수의 스케일이 서로 다르거나, 특정 매개변수가 과도하게 크거나 작으면 모델이 최적화하는 데 어려움을 겪을 수 있다(가중치가 너무 클 경우 overflow, 너무 작을 경우 기울기 소실). rectifier network는 이에 취약하다.
solution : scaling bias and weights differently
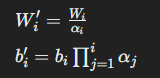
3.2 Unsupervised Pre-training
stacked denoising auto-encoders 에 rectifier 함수를 도입할 때 문제가 발생한다. reconstruction unit에서는 입력값을 최대한 정확히 복원해야 함. 만약 네트워크가 비제로 값을 재구성해야 하는데, hard saturation로 인해 0이 출력된다면, 이 유닛은 역전파를 통해 그래디언트를 전파할 수 없다. 학습이 안된다.
reconstruct function :
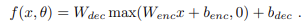
이를 해결하기 위해 두가지 실험을 했다.
1. softplus 사용
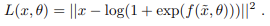
-
rectifier 에서의 출력 값을 0-1 사이의 값으로 스케일링 후, sigmoid 사용하고 cross entropy로 평가
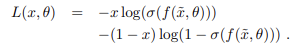
-
선형 활성화 함수 사용하고, 손실 계산에서 제곱 비용(quadratic cost)을 함께 적용
4.재구성 층에서 rectifier 를 사용하고, 손실 계산에서 제곱 비용(quadratic cost)을 함께 적용
=> 1번 : 이미지 데이터에 적합
=> 2번 : 텍스트 데이터에 적합
4. Experimental Study
- image
- text
4.1 Image Recognition
아래의 데이터셋을 이용해 실험 진행
=> MINIST, CIFAR10, NISTP, NORB
아래는 깊이가 3인 신경망에서의 test error 결과표이다.
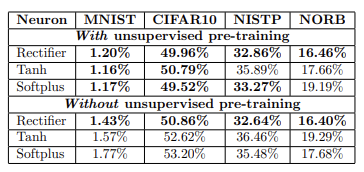
[사용된 모델]
NORB 데이터를 제외하고는 모두 stacked denoising auto-encoders 사용
[cost function]
tanh: cross-entropy
rectifier, softplus : quadratic cost
[optimizer]
SGD
[결과]
MNIST 데이터셋에서 다양한 L1 패널티를 사용해 200개의 깊은 리퀴파이어 네트워크를 훈련했으며, 85%의 실제 제로가 되기 전까지 희소성을 강제하는 것이 성능에 악영향을 미치지 않는다는 것을 보여줍니다
-
하드 임계값 문제:
rectifier 를 사용하여 훈련된 네트워크는 소프트플러스와 같은 부드러운 활성화 함수보다 동등하거나 더 높은 품질의 국소 최소값을 찾을 수 있음.
NORB 데이터셋에서 rescaled version의 softplus 사용.
=>rectifier가 더 유리 -
비지도 사전 학습:
rectifier를 사용할 경우 비지도 사전 훈련의 효과는 거의 없으며, 이는 tanh나 softplus를 사용할 때와 다르다.
=> 사전 훈련된 tanh나 softplus 모델과 비교해도 뒤쳐지지 않음. -
sparsity :
MNIST 데이터셋에서 숨겨진 층의 평균 정확한 희소성 비율이 83.4%. 이는 대부분의 유닛이 0이라는 것을 의미. CIFAR10, NISTP, NORB에서도 높게 나타남
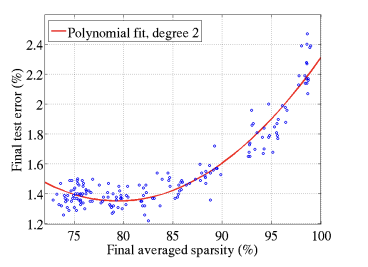
모델은 70%~85%의 real zero가 있는 경우에도 비슷한 성능을 냄을 알 수 있음, 이는 네트워크가 희소성에 대해 견고함.
- 라벨이 있는 데이터에서의 성능 :
stacked denoising auto-encoders과 다른 데이터셋을 사용하여 Nair와 Hinton의 모델보다 더 나은 성능을 보임
4.2 Sentiment Analysis
rectifier unit이 이미지 관련 작업에서 효율적임을 Nair and Hinton (2010)의 연구에서도 알 수 있었다. 감성분석에는 어떨지 적용해보자.
감정분석이란?
감정 분석은 특정 주제에 대한 작성자의 의견을 분류하는 작업. 기본적으로 리뷰의 긍정적 또는 부정적 경향성을 파악하거나 별점 평가를 예측하는 것이 주된 목표이다.
dataset / preprocessing
-
Dataset & evaluation :
레스토랑 리뷰 데이터셋( www.opentable.com. )을 사용하며 RMSE를 통해 성능을 평가하고자 한다. -
encoding :
bag of words , binary vector로 변환됨
5,000개의 빈도가 가장 높은 단어를 feature set으로 유지
=> 전처리된 데이터는 매우 sparse -
train :
- unsupervise pre-training: 레이블이 있는 리뷰와 레이블이 없는 리뷰 모두 사용
- supervised : 레이블이 있는 데이터에 대해 10번 교차 검증
model
-
모델 설정:
모델은 1개 또는 3개의 은닉층을 가진 stacked denoising auto-encoders. 각 은닉층은 5000개의 유닛을 가지고 있음. -
예측 방법:
예측된 평점은 multi-class 로지스틱 회귀(softmax)를 통해 계산된 확률을 기반으로 정의. (rectifier 네트워크의 경우, 새로운 층이 쌓일 때 이전 층의 활성화 값이 [0, 1] 범위로 스케일링되고, 시그모이드 복원층이 사용되며, 교차 엔트로피 비용이 적용) -
노이즈 추가:
이진 입력 데이터로 인해 첫 번째 층의 비지도 훈련에서는 "salt and pepper noise"를 사용하고, 이후 층에서는 0 마스킹이 적용됩니다. 노이즈 수준은 분류 성능에 따라 조정되며, 다른 하이퍼파라미터는 복원 오류에 따라 선택
result
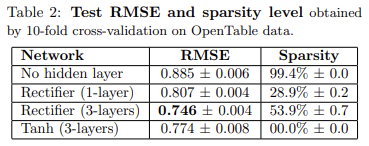
-
rectifier 신경망은 은닉층이 추가됨에 따라 RMSE가 현저히 감소합니다. 비지도 사전 훈련이 없다면 3 layer network은 0.833 이하의 RMSE를 달성할 수 X.
-
3 layer network은 50% 이상의 희소성을 달성할 수 있음.
-
같은 조건에서 tanh가 rectifier 보다 성능이 낮음. 이는 깊은 rectifier 네트워크가 희소한 원시 입력에 더 적합함을 알 수 있다.
- amazon dataset 과의 비교
OpenTable 데이터에 대한 결과가 발표된 적이 없으므로, Amazon의 감정 분석 벤치마크에 모델을 적용하여 성능을 비교. 이 데이터셋은 4종의 Amazon 제품에 대한 리뷰로, 긍정 또는 부정의 극성을 예측해야 함.
=> Zhou et al. (2010)의 연구에서는 최고의 모델이 평균 73.72%의 테스트 정확도를 기록했으나, 본 연구의 3 layer rectifier 네트워크는 더 우수한 성능을 보임 (78.95%)
5. Conclusion
리퀴파이어 유닛은 희소성과 선형 작동을 결합하여 생물학적으로 더 그럴듯한 딥 뉴럴 네트워크를 구현하는 데 도움을 준다. 이 유닛은 비지도 사전 훈련과의 간극을 메우고, 더 나은 최적화를 촉진할 수 있음을 보여준다. 연구 결과는 이미지 분류 작업에서 50%에서 80%의 희소성을 가지며, 텍스트 분석 작업에서도 유용한 가능성을 나타낸다. 이러한 결과는 rectifier 네트워크가 다양한 응용 분야에서 효과적일 수 있음을 나타낸다.
