Abstract
skipgram model(기존) + 각 단어가 n-gram의 합으로 표현(추가)
장점 1 ) 빠르다
장점 2 ) training data 에 없던 단어도 계산이 가능
1. Introduction
- 연속적인 단어들을 학습하는 연구의 역사
: co-occurence statistics 를 기반으로 시작 (단어들이 특정 문맥에서 함께 출현하는 빈도)
: distributional semantics -> two words on left/right -> simple log-bilinear models
- distinct vector로 표현되었다.
- distinct vector
distinct vector란 모든 단어들이 각자 고유한 벡터를 가지는 것.
vs subword embedding
ex. GPT, BERT
최근은 '단어'대신 'subword'단위로 임베딩한다. 예를 들어 playing을 하나의 distinct vector로 두는 것이 아니라 play + ing 로 분리하는 것.
- 그러나 형태소적으로 표현이 풍부한 언어나, training corpus에 자주 등장하지 않는 (혹은 없는) 단어들은 학습이 어렵다.
=> character level information 을 통해 벡터 표현 능력을 향상 시킬 수 있다
정리하자면,
- character n-gram
- 단어를 n-gram vector들의 합 으로 표현하는 방식
을 제안하였다. 이는 continuous skipgram 모델에 subword information 을 고려한 것으로, 논문에서는 해당 모델을 9개의 언어에 대해 평가한 과정을 보이고자 한다.
2. Related work
- Morphological word representations
- 형태소 정보를 단어 표현에 포함하는 방식의 연구들의 역사를 설명
factored neural language models -> different composition functions from morphemes-> .... - 이러한 연구들은 단어의 morphological decomposition에 의존하지만, 이 연구는 아님
- 유사한 최근 연구 : SVD를 통한 character 4-grams 와 그 합으로 단어를 표현한 연구, n-gram count vector를 통해 단어를 표현하는 연구
=> 그러나 이 연구들은 paraphrase pair를 기반으로 한 objective function이 사용되었다면, 우리의 모델은 어떤 text corpus 에도 훈련이 가능하다.
- Character level features for NLP
- character level 의 NLP 연구의 역사를 설명
3. Model
- subword unit : morphology를 고려
- word : character n-grams의 합
아래에서는 1. general model, 2. subword model, 3. character n-gram에 대한 사전을 어떻게 처리하는지 이 3가지에 대해 설명할 것이다.
3.1 General Model
기존의 continous skipgram model
-
target word를 기준으로 context word(주변 단어)를 예측
-
target word가 주어졌을 때, context word 가 나올 확률을 최대화 하는 방식으로 학습
크기가 인 사전이 주어지면, 단어 는 까지의 인덱스로 식별할 수 있다. (ex. 'happy'라는 단어가 22번째 인덱스에 있음)
Distributional Hypothesis(분포 가설)을 바탕으로,
: 주변 단어들과 함께 자주 등장할수록 의미적으로 밀접한 관계에 있다는 가정. ex) "cat"과 "dog"이라는 단어가 자주 비슷한 문맥에서 사용된다면, 이 두 단어는 의미적으로 유사할 가능성이 높다는 뜻
skipgram의 목적은 아래의 값을 최대화 하는 것이다.
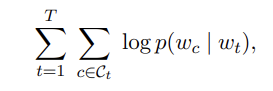
: 의 주변단어들의 인덱스 집합
scoring function s가 (word, context) 쌍을 매핑한다고 하면, 아래와 같이 context word의 probability를 계산할 수 있다.(softmax)
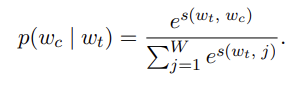
=> 그러나 이 모델은 단 하나의 context word를 예측하므로, 우리의 모델에 적합하지 않다.
=> 따라서 이를 독립적인 이진 분류 문제의 집합 으로 재구성하여 바라볼 수 있다. 즉, 각각의 단어가 중심 단어에 대해 context word인지, 아닌지를 판별하는 것이다.
위치 t에 있는 context words는 모두 positive라고 가정하고, 사전에서 랜덤하게 negative sample을 추출한다. 이때 특정 위치 c에 있는 단어를 binary logistic loss를 사용하여 아래와 같이 계산할 수 있다.
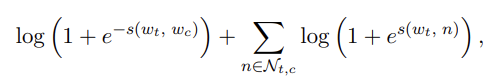
는 negative example의 집합이다. logistic loss function을 고려하여 아래와 같이 objective 함수를 쓸 수 있다.
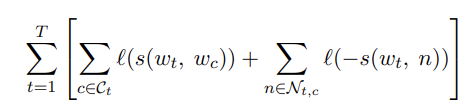
3.2 Subword model
distinct vector representation을 사용한 기존의 skipgram은 단어의 내부구조를 무시한다. 따라서 우리는 다른 scoring function 를 제안한다.
- 각 단어 는 앞서 계속 말했듯이, character n-gram의 집합으로 표현 된다(n-gram의 순서는 중요하지 않음). 즉, 단어를 여러개의 연속된 문자 단위로 나누고, 이 문자들의 조합을 사용하여 단어를 표현하는 방식이다.
예를 들어 , n=3이고 'where'이라는 단어를 character n-gram으로 표현하면 :
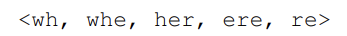
- <,> 도 경계 기호로 문자의 갯수에 포함된다. 따라서 위의 5개의 문자는 3-gram이 맞다.
이때 주의할 것은 'her'이라는 단어의 과 'where'의 her은 다르다는 것이다.
크기가 인 n-gram 사전이 주어졌다고 해보자.
우리는 단어를 n-gram의 합으로 표현하기로 했다. 따라서 score function은 아래와 같다.
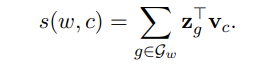
- : 벡터로 표현된 각각의 n-gram
- : 클래스 벡터
이는 단어들 사이에 표현을 공유하고, rare word에 대한 표현이 가능하게 한다.
추가적으로, 메모리 효율성을 위해 n-gram을 1~K사이의 숫자로 hashing을 하였다. (Fowler-Noll-Vo hashing function)
따라서 결과적으로 단어는
- 사전에서의 index (사전에서의 위치)
- 해시된 n-gram 집합
으로 표현된다.
4. Experimental setup
Baseline, optimization, implementation detail, datasets 에 대해 설명한다.
4.1 Baseline
skipgram 과 cbow model 사용 ( word2vec package : https://code.google.com/archive/p/word2vec/)
4.2 Optimization
-
SGD 사용
-
step size (학습률) : linear decay
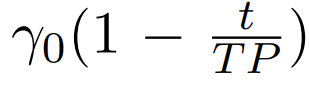
- 가 커질수록 step size는 선형적으로 감소
-T : 전체 단어 수, P : 데이터셋을 몇번 반복할지 - 학습 초기에는 빠르게 파라미터 값을 변경하고, 학습 후반으로 갈수록 천천히 업데이트 되게 함
- 가 커질수록 step size는 선형적으로 감소
-
병렬 최적화
- 학습을 최적화 하기 위해 여러 thread 사용
- 이때, 파라미터는 공유되며, asynchronous 하게 업데이트 됨
(따라서 파라미터 값이 덮어씌워지기도 함)
4.3 Implementation Details
- word vector 의 차원 : 300
- context window c: 1~5
- rejection threshold: 10^-4
- training set에서 5회 이상 등장하는 단어만 사전에 등록
- step size
- skipgram baseline: 0.025
- cbow baseline, our model : 0.05
4.4 Datasets
-
train set : Wikipedia dumps
-
9 languages : Arabic, Czech, German, English,Spanish, French, Italian, Romanian and Russian
-
normalize by MattMahoney’s pre-processing perl script
shuffled, 5 passes
5. Results
총 5가지의 실험을 통해 평가할 것이다.
1. 단어 유사성 평가 (word similarity)
2. 단어 유추 평가 (word analogies)
3. 최신 방법들과의 비교 (comparison to state-of-the-art methods)
4. 훈련 데이터 크기와 모델 성능의 관계 분석 (effect of training data size)
5. n-gram 크기와 모델 성능의 관계 분석 (effect of character n-gram size)
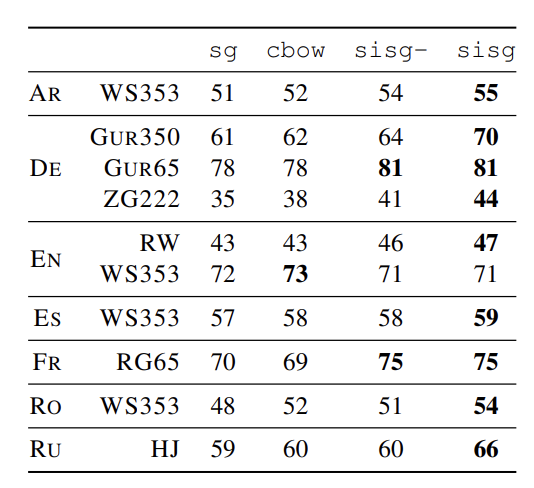
5.1 Human similarity judgement
- Spearman’s rank correlation coefficient 를 사용하여 성능 평가
- OOV 문제
- training data에 없는 단어 등장하였고, 아래와 같이 처리함
- cbow 와 skipgram : null vector로 처리
- 제시한 모델 : sum of its n-gram vectors
- (sisg-): null vector, (sisg): sum of its n-gram vectors
- training data에 없는 단어 등장하였고, 아래와 같이 처리함
- sisg 가 성능이 좋음을 알수 있음
- 그리고 자주 등장하지 않는 단어들에 대해서도 더욱 잘 처리함 (english dataset 제외)
5.2 Word analogy tasks
- 여기서는 training corpus 에 나타나지 않은 단어는 지웠다 (왜지..?)
- 아래의 결과를 보면, semantic question에는 별로 도움이 되지 않으나(심지어는 성능 저하도 나타남), syntactic tasks 에는 도움이 됨.
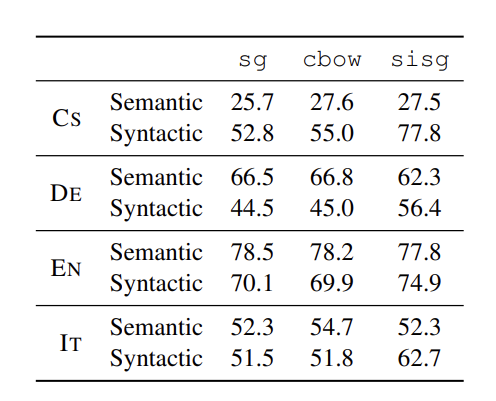
- 저자는 물론 최적의 n 값을 설정하면 semantic 부분의 성능 저하를 최소화할 수 있다고 말함.
5.3 Comparison with morphological representations
-
다른 형태소적 표현 methods 와의 비교 => 우수하다!
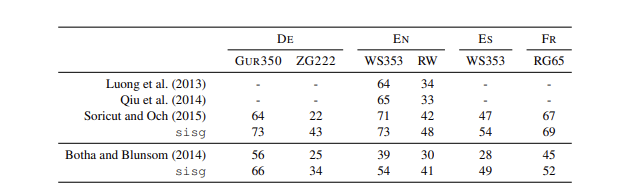
5.4 Effect of the size of the training data
- 제안된 모델(sisg)은 다양한 크기의 데이터셋에서 cbow 기준 모델보다 항상 더 나은 성능을 보임
- 소규모 훈련 데이터셋에서도 우수
ex) 5%의 데이터로 훈련된 모델이 전체 데이터로 훈련된 cbow보다 더 높은 성능을 나타내는 경우도 있음.
=> 제한된 크기의 데이터셋에서도 잘 작동하는 단어 벡터를 생성할 수 있음을 보임.
5.5 Effect of the size of n-grams
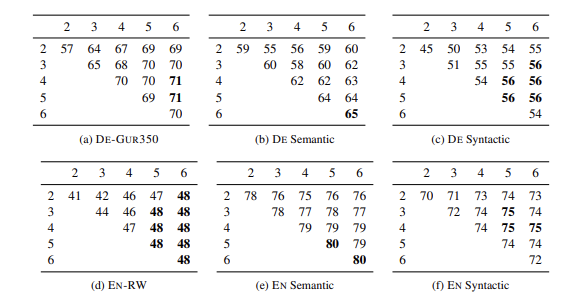
-
3~6자의 n-gram을 사용
-
길이는 짧은 접미사와 긴 어근을 모두 포함하여 다양한 정보를 포괄할 수 있도록 선택
-
실험 결과, 영어와 독일어에서 이 n-gram 범위가 만족스러운 성능을 제공하는 것으로 나타남.
-
하지만 최적의 n-gram 길이는 언어와 작업에 따라 달라지므로 적절히 조정해야 함.
- 특히 독일어의 경우, 많은 명사가 여러 구성 요소로 이루어져 있어 긴 n-gram이 필요. -
또한 n이 3 이상인 경우가 2 이상인 경우보다 더 나은 결과를 보여, 2-gram은 유용하지 않았음. 단어의 시작과 끝을 나타내기 위해 특수 위치 문자를 추가하여 n-gram을 계산하므로, 2-gram만으로는 접미사를 제대로 포착할 수 없음.
5.6 Language modeling
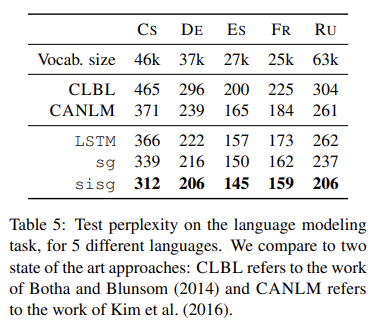
log-bilinear language model vs character aware language model
- 모델은 650개의 LSTM 유닛을 갖춘 순환 신경망
- Adagrad 사용
- 실험 결과, 사전 훈련된 단어 벡터로 초기화된 언어 모델이 기본 LSTM보다 더 나은 성능
- 특히 같은 형태소가 풍부한 언어에서 8% 및 13%의 perplexity 감소
=> 형태소 정보를 사용하는 것이 언어 모델링 작업에서 중요하다
6. Qualitative Analysis
6.1 Nearest Neighbors
제안된 모델과 skipgram baseline 모델을 사용하여 훈련된 벡터의 코사인 유사도를 기반으로 선택된 단어의 최근접 이웃을 보여준다.
=> 결과적으로, 복잡하고 기술적이며 드문 단어의 경우, 제안된 접근 방식이 기준 모델보다 더 나음
6.2 Character n-grams and Morphemes
단어의 가장 중요한 n-gram이 형태소와 관련이 있는지 평가하기 위해, n-gram의 합으로 구성된 단어 벡터를 사용.
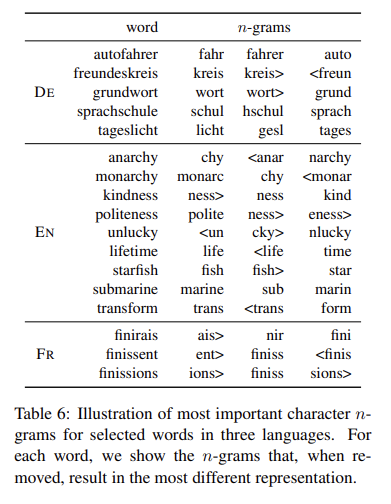
- 독일어에서는 합성 명사가 많아 주요 n-gram이 유효한 형태소에 해당하는 경우가 많음.
ex) "Autofahrer"는 "Auto"와 "Fahrer"가 가장 중요한 n-gram. - 영어는 "lifetime"과 "starfish" 같은 경우에 형태소로 분리되는 현상을 관찰
- "kindness"와 "unlucky"처럼 접미사가 있는 단어도 확인
- 프랑스어에서는 동사의 굴절이 중요한 n-gram으로 나타남
6.3 Word Similarity for OOV Words
모델은 훈련 세트에 나타나지 않는 단어에 대해서도 벡터를 생성할 수 있으며, 이는 n-gram의 평균으로 표현된다.
- OOV 단어의 품질을 평가
- 데이터셋에서 단어 쌍을 선택하고 코사인 유사도를 분석. 예를 들어, "microcircuit"와 "chip"의 경우 n-gram이 두 그룹으로 잘 매칭되며, "scarcity"와 "rarity"도 비슷한 결과.
=> 접두사와 접미사가 사전에서 찾을 수 없는 형태일 경우에도 강력한 단어 표현을 형성할 수 있음을 보여준다.
7. Conclusion
character n-grams를 skipgram model에 적용하였다. subword information을 고려하지 않는 모델에 비해 뛰어난 성능을 보였다.
