논문 리뷰하기에 앞서
"Attention Is All You Need"라는 논문은 어떤 혁신을 가져왔는가? 이 논문이 왜 모든 자연어처리의 기초 논문이 된 것일까 궁금해졌다.
RNN, LSTM과 같은 recurrent한 구조 없이도 시퀀스를 처리할 수 있다는 것을 보여주었기 때문이다.
그리고 이러한 transformer 구조의 특성상, 병렬 연산이 가능해지고, Long-Term dependency 문제를 해결할 수 있었기 때문에 엄청난 성능 향상 및 빠른 학습이 가능해진 것 !!
Abstract
그동안의 sequence transduction model들은 복잡한 RNN/CNN의 encoder-decoder 모델로 구성되어왔다.
이 논문은 오직 attention mechanism 만을 사용한 Transformer 라는 새로운 신경망을 제안한다.
두 개의 기계 번역 실험을 통해
- 기존의 모델들보다 번역 품질이 뛰어남
- 병렬 처리가 잘됨(계산 리소스를 더 효과적으로 사용가능)
- 훈련 시간 감소
됨을 보여준다. 또한, 다른 작업에도 generalize가 잘 되며, 제한된 / 많은 데이터들에서 둘 다 영어 구문 분석 능력이 뛰어났다.
1. Introduction
기존 RNN 모델들의 단점
그동안 RNN, LSTM, GRU 모델을 통해 sequence modeling 이나 transduction 문제를 해결하는 것이 일반적이었다. 그러나 이런 모델들은 각 입력을 시간에 따라 순차적으로 처리한다. 계산 방식을 보면, 각 요소에 대해 이전 hidden state의 값을 사용하여 현재의 hidden state값을 계산한다.
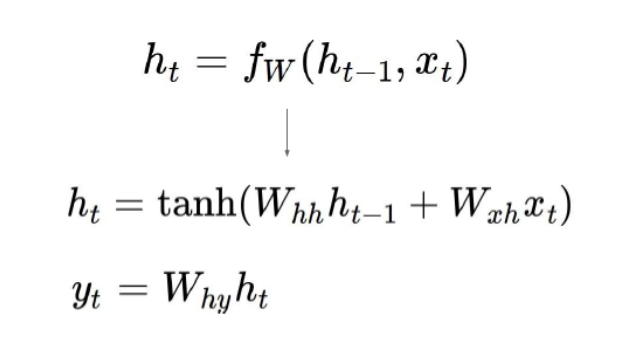
매 시점마다 이전 은닉 상태를 입력과 함께 사용하여 새로운 상태를 만든다.
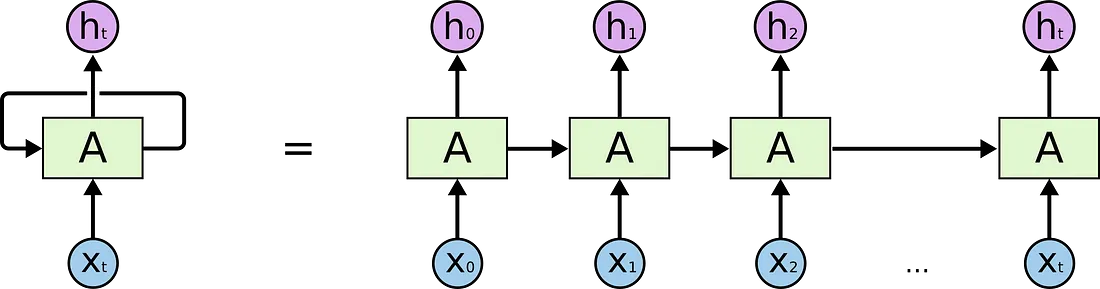
따라서 각 시점의 계산이 이전 시점의 값을 필요로 하기 때문에, 모든 시점을 동시에 계산하는 병렬 처리 가 불가능하다. LSTM은 gate를 활용하여 장거리 관계에서 학습이 안되는 문제를 완화하긴 하였지만, 그럼에도 연속된 많은 연산을 거치기 때문에 긴 시퀀스의 정보가 점차 소실되거나 폭발하므로 긴 시퀀스의 정보를 학습하기 어려웠다.
이후 연구들은 팩토리제이션 트릭과 조건부 계산을 통해 계산 효율성을 크게 향상시켰다. 이러한 기법들은 모델의 성능 향상에도 기여했으나, 본질적인 순차적 계산으로 인한 한계 는 해결하지 못했다.
그러나 Attention Mechanism은 sequence의 길이(거리)에 상관없이 의존성을 모델링 할 수 있다.
이전의 RNN이나 LSTM과 같은 모델은 각 단계에서 이전 결과를 기반으로 연속적으로 연산을 수행하므로, 계산이 순차적이고 속도가 느림. 반면 Transformer는 recurrence 모델을 완전히 없애고 attention만을 사용하면서 병렬 처리를 가능하게 함.
2. Background
RNN vs CNN vs Transformer
-
RNN:
입력 순서대로 하나씩 처리하기 때문에
→ 첫 단어와 마지막 단어의 관계를 계산하려면 전체 시퀀스를 따라가야 함
→ 연산 횟수: 시퀀스 길이만큼 (O(n)) -
CNN (ConvS2S, ByteNet):
컨볼루션은 병렬적으로 처리하지만 멀어질수록 의존성 학습이 어려워진다 는 단점을 아직 해결하지 못함
→ 먼 거리의 단어 간 관계를 보려면 여러 층(layer)을 거쳐야 함
→ 연산 횟수: 거리만큼 늘어남 (O(log n) 또는 O(n)) -
Transformer :
→ 연산 횟수가 상수 이다.
→ 단어 A와 단어 B 사이의 의존 관계를 파악하는 데 필요한 연산 수는 시퀀스 길이와 무관하게 일정 = O(1)
→ 대신 전체 시퀀스에 대해 모든 쌍의 관계를 계산하므로, 전체 연산량은 O(n²)
전체적으로 연산량은 많지만 빠른 이유는 병렬 연산이 가능하기 때문
그러나 Attention weights를 평균화하는 과정에서 해상도가 감소하는 문제가 발생. 이 과정에서 정보를 평균화하게 되어, 세밀한 위치 정보가 손실될 수 있음.
=> Multi-Head Attention 을 사용하여 해결(section 3.2)
3. Model Architecture
- Sequence-to-Sequence 모델
- Encoder-Decoder 구조
아래의 그림은 Transformer model의 전체 구조이다.
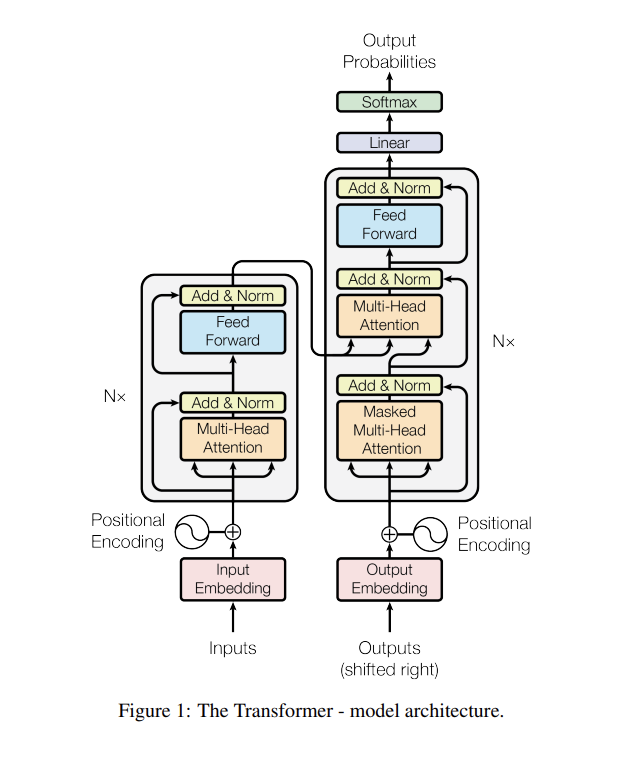
3.1 Encoder and Decoder Stacks
Encoder
- N=6 개의 동일한 레이어로 구성됨
- 각 레이어는 두개의 sub-layer
- multi-head self-attention mechanism- position wise fully connected feed-forward network
- 각 sub-layer는 residual connection을 수행 (정보 손실 줄임)
이전 레이어의 출력(현재 입력)과 출력 값을 더한 후 normalization.
✅Step
1. Input Embedding
2. positional encoding을 각 임베딩 벡터에 더함
3. 이 벡터들이 N개의 multi-head self-attention 과 FFN을 통과
Decoder
- 인코더와 똑같이 N=6 개의 동일한 레이어로 구성
- 3개의 sub-layer 존재
- masked multi-head attention
- multi-head attention layer - 인코더의 출력을 기반 으로 수행
- self-attention 시 이전에 생성된 토큰에만 의존하게 마스킹
*residual connection 과 normalization은 동일하게 적용
✅Step
1. Output: 지금까지 생성한 단어들의 sequence
2. Output Embedding + Positional encoding + masking(미래 정보 못 보게)
3. N개의 sub-layer 통과
4. 출력 벡터 → Softmax → 단어 예측
궁금한 점?
- 선형적으로 임베딩 벡터랑 위치 벡터를 더하면 임베딩 된 단어의 정보를 훼손하지는 않는가? 어떻게 위치 정보를 반영할 수 있지?
✅ 위치 정보는 상대적으로 작고 규칙적 (특히 사인/코사인 방식일 경우)
-
Transformer 원 논문에서 제안된 Sinusoidal Positional Encoding은 다음과 같이 구성됩니다:
-
이 값들은 단어 임베딩에 비해 작고 정규화된 패턴을 가지고 있어서:
- 전체 벡터의 방향성은 크게 바꾸지 않으면서
- 위치에 대한 힌트만 더해주는 역할을 합니다.
➡️ 즉, 완전히 덮어쓰는 게 아니라 **약간의 위치 편향(bias)**를 주는 식이에요.
2. Positional Encoding은 어떤 방식으로 진행되는가?
- 정해진 sin, cos 함수 이용
위치 인코딩의 구체적 방식: 원논문에서는 주로 정해진 사인-코사인 함수를 사용한 고정 인코딩을 제안했습니다. 수식으로는 위치
𝑘
k와 임베딩 차원의 인덱스
2
𝑖
,
2
𝑖
- 1
2i,2i+1에 대해
𝑃
𝐸
(
𝑘
,
2
𝑖)
sin
(
𝑘
10000
2
𝑖
/
𝑑
)
,
𝑃
𝐸
(
𝑘
,
2
𝑖 - 1
)
cos
(
𝑘
10000
2
𝑖
/
𝑑
)
,
PE(k,2i)=sin(
10000
2i/d
k
),PE(k,2i+1)=cos(
10000
2i/d
k
),
여기서
𝑑
d는 모델의 임베딩 차원 수,
𝑖
i는 인덱스입니다
machinelearningmastery.com
. 이로써 짝수 인덱스 차원에는 사인파, 홀수 인덱스 차원에는 코사인파가 배정되며, 주파수가 각 차원마다 기하급수적으로 다르게 설정됩니다. 즉, 서로 다른 주파수의 사인·코사인 파형이 겹쳐 각 위치마다 고유한 벡터 패턴을 형성합니다
machinelearningmastery.com
. 예를 들어, 위치 0,1,2,...의 인코딩 벡터를 시각화하면 저주파부터 고주파까지 다양하게 변화하는 사인파 그래프들을 볼 수 있습니다. 이러한 주기적 특성 덕분에 모델이 상대적 거리를 학습하기도 유리하다고 알려져 있습니다
3. d_model=512로 고정하던데, 왜지?
그래야 residual connection이 가능. 벡터 연산이니까 같은 차원이어야지
3.2 Attention
attention function에 대해 알아보자. attention은 쿼리와 key-value 쌍을 출력에 매핑하는 것으로 볼 수 있다. 출력은 가중평균을 통해 계산된다.
Query, Key, Value란 각각 무엇을 의미할까?
-
Query (질의): 입력 시퀀스의 특정 위치에서 다른 위치와의 연관성을 확인하기 위한 기준이 되는 벡터. 쉽게 말해, 입력 시퀀스의 각 단어 또는 토큰이 "나는 다른 단어들과 어떤 관계가 있지?"라고 질문하는 역할을 한다. Query는 해당 위치의 정보가 다른 단어들과 얼마나 연관이 있는지를 찾기 위한 시작점.
-
Key (키): 입력 시퀀스의 각 위치에 자신이 가진 정보를 압축한 벡터로, Query와의 유사도를 계산하기 위한 정보. Query는 각 Key와 비교되어 유사도를 측정하게 된다. Key는 일종의 "다른 단어들이 나와 얼마나 관련이 있는지 측정할 때 사용할 정보"를 담고 있다.
-
Value (값): Query가 Key와 상호작용하여 계산된 연관성(주의 점수)을 통해 최종적으로 참조하게 되는 정보를 담고 있는 벡터. Query와 Key의 유사도를 기반으로 가중치가 부여된 후, Value를 종합하여 최종적으로 문맥을 고려한 표현을 계산한다.
정리하자면:
Query: "나와 관련된 정보는?"
Key: "내가 가진 정보는?"
Value: "최종적으로 참조할 정보는?"
이라고 볼 수 있다.
3.2.1 Scaled Dot-Product Attention
먼저 attention function을 보면 아래와 같다.
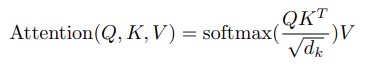
처음에 입력 seq의 각 요소는 Q,K,V 의 행렬로 변환된다.
(이때 ,,는 가중치)
: Query와 key의 내적으로 유사도 계산
: key 벡터의 차원. 이의 루트 값으로 나누어 주어 내적 값이 너무 커지지 않도록 스케일링
또한 softmax 함수를 통해 확률값으로 변환한 이 값이 attention score이다.
자신을 포함해 다른 단어들과의 유사도(관계)를 나타내는 값이 됨을 알 수 있다.
=> additive attention도 있으나, 이보다 dot-product attention이 빠르고 공간 효율적이라 이를 따랐다. 그러나 차원이 커질수록 (값이 커질수록) 내적 값이 매우 커지고, 이는 기울기 소실 문제로 이어질 수 있다. 따라서 루트 값으로 나누어 완화하고자 하였다.
3.2.2 Multi-Head Attention
Multi-Head Attention은 여러 개의 서로 다른 Attention Head를 동시에 적용하여 다양한 관점에서 정보를 처리하는 것이다. 각 헤드가 서로 다른 Query, Key, Value로
1. 독립적인 attention 계산을 수행 한 후, 각 헤드가 계산한 결과(Value 벡터들에 가중치가 적용된 값들)를
2. 연결(concatenate) 하고, 이를 다시
3. 선형 변환 을 통해 최종 출력으로 만든다.

Head 에 대해 자세히 알아보자. 입력 시퀀스의 각 벡터(단어)를 여러 개의 작은 벡터로 분할한다. 예를 들어, 512차원의 입력 벡터를 8개의 헤드로 나눈다면, 각 헤드에 대해서는 64차원짜리 벡터들이 사용되는 것이다. 이렇게 분할한 벡터들은 각 헤드마다 서로 다른 Query, Key, Value 행렬에 적용된다. 각 헤드마다 해당 벡터의 서로 다른 부분의 정보 를 학습하게 되는 것이다.
따라서 각 헤드가 서로 다른 가중치 행렬()을 사용하여 Query, Key, Value를 계산하고, attention score를 계산한다. 즉, 여러 헤드가 동시에 같은 입력에 대해 서로 다른 문맥을 학습하게 된다.
각 헤드는 서로 다른 가중치 행렬을 가지고 있기 때문에 Query, Key, Value 벡터들을 서로 다르게 변환한다. 이를 통해 같은 입력 토큰이라도 헤드마다 다르게 해석되며, 다양한 관점에서 입력을 이해할 수 있게 된다.
ex. 한 헤드는 단어 간 짧은 거리에서의 관계를 더 잘 학습하고, 또 다른 헤드는 긴 거리에서의 관계를 더 잘 학습
3.2.3 Applications of Attention in our Model
Transformer 모델은 세 가지 방식으로 멀티-헤드 어텐션을 사용한다:
1. Encoder-Decoder attention
: 디코더의 이전 레이어에서 쿼리가 오고, 인코더의 출력에서 키와 값을 통해 연산
2. Encoder self-attention
: 키, 값, 쿼리가 모두 이전 레이어의 출력에서 나옴
3. Decoder self-attention
: 디코더에서 autoregressive property를 유지하기 위해(오른쪽에서 왼쪽으로 정보를 전달하는 것을 방지) 해당 값들을 마스킹(−∞로 설정)
3.3 Position-wise Feed-Foward Networks
인코더와 디코더 모두 각 레이어마다 해당 네트워크를 가지고 있음.
- 2 linear + RELU
- 레이어마다 다른 파라미터 사용
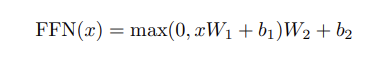
3.4 Embeddings and Softmax
-
Transformer 모델에서는 다른 시퀀스 변환 모델과 마찬가지로, 학습된 임베딩(embedding)을 사용하여 입력 토큰과 출력 토큰을 차원 d_model의 벡터로 변환
-
입력 임베딩 레이어, 출력 임베딩 레이어, 그리고 디코더의 소프트맥스 이전에 있는 선형 변환이 같은 가중치 행렬(weight matrix)을 공유
-
임베딩 레이어에서는 가중치 행렬을 √d_model로 곱하여, 임베딩 벡터의 크기를 적절히 조정
3.5 Positional Encoding
Transformer 모델에는 순환(RNN)이나 합성곱(CNN) 구조가 없기 때문에, 시퀀스의 순서 정보를 모델에 반영하기 위해 위치 인코딩(positional encoding)을 추가한다.
- 위치 인코딩은 입력 임베딩과 같은 차원 을 가지며, 임베딩에 더해짐.
- 위치 인코딩은 학습될 수도 있고, 고정될 수도 있는데, 이 논문에서는 사인(sine)과 코사인(cosine) 함수를 사용하는 고정된 인코딩 을 사용하였다.
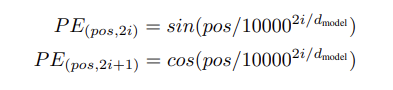
(학습된 위치 인코딩도 사용해 보았으나, 성능이 비슷하고 심지어 고정된 인코딩이 더 긴 시퀀스에 적용이 가능하여 고정된 인코딩으로 진행)
4. Why Self-Attention
CNN,RNN과 비교하여 Self-Attention의 장점이 3가지 있다.

-
총 계산 복잡도
Self-Attention 레이어는 모든 위치 간의 연결이 상수 시간 내에 이루어지는 반면, RNN 레이어는 O(n)의 순차적인 연산이 필요하다. -
병렬 처리 가능성
Self-Attention 레이어는 계산을 병렬화할 수 있는 정도가 높다. 즉, 입력 시퀀스의 모든 위치에 대한 처리를 동시에 수행할 수 있어 더 빠른 연산을 가능하게 한다. -
장기 의존성 학습의 경로 길이
Self-Attention은 입력 및 출력 시퀀스 간의 경로 길이를 짧게 유지하여 장기 의존성을 쉽게 학습할 수 있다.
추가적으로, Self-Attention은 입력 시퀀스의 길이(n)가 표현 차원(d)보다 작을 때 더 빠르며, 일반적으로 n<d이다. CNN은 커널 폭(k)으로 인해 모든 입력 및 출력 위치를 연결할 수 없으며, 이를 위해 O(n/k) 또는 O(logk(n))의 레이어 스택이 필요하다. CNN은 일반적으로 RNN보다 계산 비용이 더 높다.
5. Training
5.1 Training Data and Batching
- dataset : WMT 2014 영어-독일어 데이터셋, 영어-프랑스어 데이터셋
- encoding : byte-pair
5.2 Hardware and Schedule
- 8개의 NVIDIA P100 GPU 사용
- 기본 모델은 총 100,000 스텝 또는 12시간 동안 훈련, 각 훈련 스텝은 약 0.4초가 소요되었고, 대형 모델의 경우, 스텝 시간은 1.0초
5.3 Optimizer
- adam 사용
- 하이퍼 파라미터 :
- 학습률은 아래와 같이 변화시키며 훈련
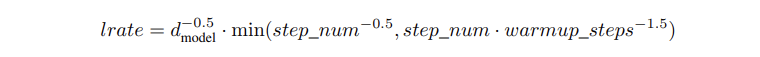 이는 처음 warmup_steps(4,000) 동안 학습률을 선형으로 증가시키고, 이후 스텝 번호의 역 제곱근에 비례하여 감소시킴
이는 처음 warmup_steps(4,000) 동안 학습률을 선형으로 증가시키고, 이후 스텝 번호의 역 제곱근에 비례하여 감소시킴
5.4 Regularization
Residual Dropout
- Pdrop = 0.1
- 각 서브 레이어의 출력에 드롭아웃을 적용하여 서브 레이어 입력에 더해지고 정규화되기 전에 적용합니다.일반화 성능을 향상
- 인코더와 디코더 스택에서 임베딩과 위치 인코딩의 합에도 드롭아웃을 적용.
Label Smoothing
- label smoothing: ϵls = 0.1
- 이는 모델이 확신이 덜한 상태에서 학습하게 하여, perplexity(혼란도)를 증가시키지만, 정확도와 BLEU 점수를 개선하였다.
6. Results
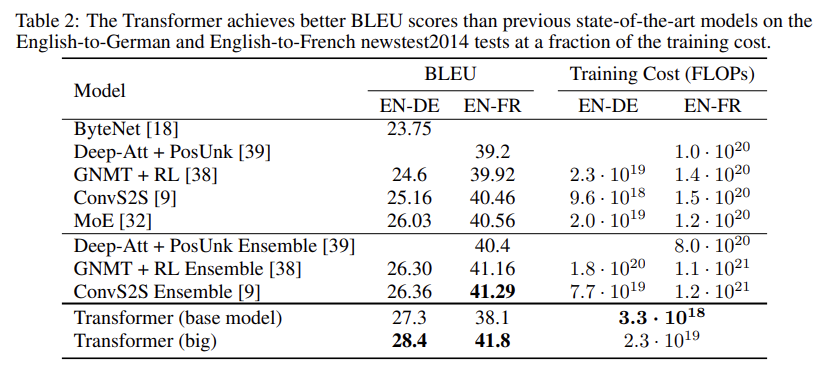
6.1 Machine Translation
big models
- 영어-독일어 번역:
Transformer (big) 모델은 과거 최상의 모델(앙상블 포함)보다 높은 BLEU 점수인 28.4를 기록
- 영어-프랑스어 번역:
big 모델이 BLEU 점수 41.0을 달성.
이는 이전 최첨단 모델의 훈련 비용보다 훨씬 저렴했음.
영어-프랑스어 번역에 사용된 Transformer (big) 모델은 드롭아웃 비율 Pdrop = 0.1을 사용(0.3 대신)
모델 훈련 및 추론:
base models
기본 모델은 마지막 5개의 체크포인트의 평균을 사용하여 생성되었으며, 큰 모델은 마지막 20개의 체크포인트의 평균을 구하였다. 빔 서치를 사용하여 빔 크기 4와 길이 패널티 α = 0.6로 설정하였다. 또한 추론 시 최대 출력 길이는 입력 길이 + 50으로 설정하였으나, 가능한 경우 조기종료하도록 하였다.
아래는 각 모델의 훈련 시간, GPU 수, 및 부동소수점 연산량을 통해 성능을 비교한 표이다.
6.2 Model Variations
Transformer의 다양한 구성 요소의 중요성을 평가하기 위해, 우리는 기본 모델을 여러 가지 방식으로 변경하고, 이를 통해 영어-독일어 번역에서의 성능 변화를 측정하였다.
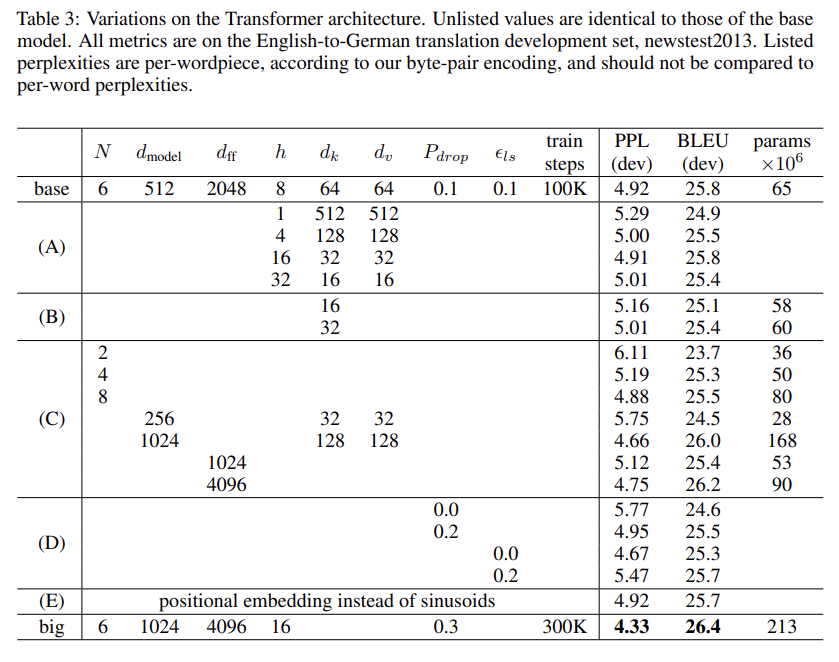
-
(A): 주의 헤드 수와 주의 키 및 값 차원을 변경하여 연산량을 일정하게 유지. 단일 헤드 주의는 최적 설정보다 0.9 BLEU 낮았으며, 헤드 수가 너무 많아지면 품질이 감소하였다.
-
(B): 주의 키 크기 dk를 줄이면 모델 품질이 저하되는 것을 관찰. 이는 호환성 결정을 쉽게 하는 것이 아니며, 점곱보다 더 정교한 호환성 함수가 유리할 수 있음을 알 수 있다.
-
(C) & (D): 예측한 바와 같이, 더 큰 모델이 더 나은 성능을 보이며, 드롭아웃이 과적합을 피하는 데 매우 유용함을 알 수 있음.
-
(E): 우리의 사인 함수 기반 위치 인코딩을 학습된 위치 임베딩으로 대체했을 때, 기본 모델과 거의 동일한 결과.
6.3 English Constituency Parsing
Transformer 모델이 다른 작업에 일반화될 수 있는지를 평가하기 위해, 영어 구문 분석 실험을 수행하였다.
이 작업은 강한 구조적 제약이 있으며, 출력이 입력보다 상당히 길다는 특징이 있다.
실험 설정:
- 모델 구조: 4층 Transformer, dmodel = 1024.
- 데이터 세트: Penn Treebank의 Wall Street Journal (WSJ) 부분에서 (약 40,000) + 약 1,700만 문장을 포함하는 고신뢰도 및 BerkleyParser 코퍼스를 사용한 반감독 학습 설정
- 어휘: WSJ 전용 설정에는 16,000개의 토큰을 사용하고, 반감독 설정에는 32,000개의 토큰을 사용
- 추론 시 최대 출력 길이를 입력 길이 + 300으로 늘렸고, 빔 크기는 21, α = 0.3으로 설정
아래의 표의 결과에 따르면, Recurrent Neural Network Grammar를 제외한 모든 이전 모델보다 더 나은 결과를 기록하였다. RNN 시퀀스-투-시퀀스 모델과 비교할 때, Transformer는 WSJ 훈련 세트(40K 문장)만으로 훈련했음에도 불구하고 BerkeleyParser【29】보다 더 나은 성능을 보였다.
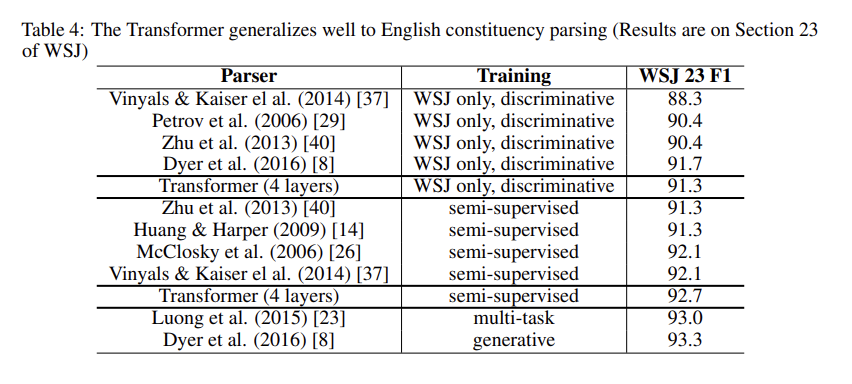
이 실험 결과는 Transformer 모델이 다양한 자연어 처리 작업에서 효과적으로 일반화될 수 있음을 시사한다.
7. Conclusion
이 연구에서는 Transformer를 소개하며, 이는 완전히 어텐션에 기반한 최초의 시퀀스 변환 모델이다. 기존의 인코더-디코더 구조에서 주로 사용되던 순환층을 다중 헤드 셀프 어텐션으로 대체하였다.
주요 성과:
- 번역 작업에서 Transformer는 순환층이나 합성곱층 기반의 아키텍처보다 훨씬 빠르게 훈련이 가능.
(WMT 2014 영어-독일어와 영어-프랑스어 번역 과제 모두에서 새로운 최첨단 성능을 달성)
향후 계획:
어텐션 기반 모델을 다른 작업에도 적용할 계획. 텍스트 외의 입력 및 출력 모달리티를 포함한 문제로 Transformer를 확장할 계획이며,이미지, 오디오, 비디오와 같은 대규모 입력 및 출력을 효율적으로 처리하기 위해 국소적, 제한된 어텐션 메커니즘을 탐구할 것이다. 또한, 생성 과정의 순차성을 줄이는 것도 하나의 목표이다.
사용한 코드 : github
