Chapter 1 Huggingface Tutorials
허깅페이스
- 코랩 환경에서 설치
!pip install huggingface_hub datasets transformers-> transformers: 트랜스포머 모델과 토크나이저 사용
-> datasets: 라이브러리와 데이터셋을 쉽게 사용
-> huggingface_hub: 허깅페이스 허브와 연결
- 테스트
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
question = "What is Hugging Face?"
input_ids = tokenizer.encode(question, return_tensors="pt")
output = model.generate(input_ids, max_length=60, num_return_sequences=1)
answer = tokenizer.decode(output[0], skip_special_tokens=True)
print(f"Question: {question}")
print(f"Answer: {answer}")
- 감성분석
from transformers import pipeline
classifier = pipeline('sentiment-analysis')
res = classifier('I am very happy!')
res
res = classifier('The current situdation is very bad.')
res
- 문장 생성
generator = pipeline("text-generation", model='distilgpt2')
res = generator(
'The current situation is very bad.',
max_length = 30,
num_return_sequences = 3
)
res
허깅페이스 라이브러리 사용
- 토크나이저 불러오기
from transformers import AutoModel
model_id = 'klue/roberta-large'
tokenizer = AutoModel.from_pretrained(model_id) -> KLUE 한국어 언어 이해 평가 데이터
-> roberta : RoBERTa는 Facebook AI에서 개발한 자연어 처리(NLP) 모델로, BERT(Bidirectional Encoder Representations from Transformers)를 기반으로 한 모델, BERT의 구조를 유지하면서 성능을 더욱 향상시키기 위해 다양한 최적화를 추가한 것이 특징
-
문장, 단어, 토큰
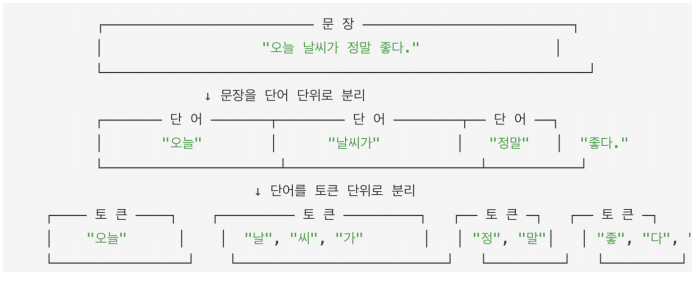
-
토크나이저는 텍스트를 토큰으로 나눔
from pprint import pprint
tokenized = tokenizer("토크나이저는 텍스트를 토큰 단위로 나눈다")
pprint(tokenized)-> attension mask : 실제 텍스트인지 길이를 맞추기 위한 용도인지 구분
-> input_ids : 전체 말뭉치에서 몇 번째 토큰인지 [단, roberta의 경우는 의미가 없음]
- 토큰 아이디를 토큰으로 바꾸는 방법
tokenizer.convert_ids_to_tokens([tokenized['input_ids'][1]])pprint(tokenizer.convert_ids_to_tokens(tokenized['input_ids'])) 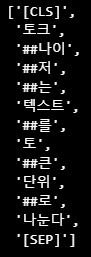
- 다시 문장으로 변경
pprint(tokenizer.decode(tokenized['input_ids'])) 
- 특수 토큰 제거
pprint(tokenizer.decode(tokenized['input_ids'], skip_special_tokens=True))
- 미세한 차이를 보여주는 문장의 구분
first_tokenized_result = tokenizer(['첫 번째 문장', '두 번째 문장'])['input_ids']
tokenizer.batch_decode(first_tokenized_result)['[CLS] 첫 번째 문장 [SEP]', '[CLS] 두 번째 문장 [SEP]']
second_tokenized_result = tokenizer([['첫 번째 문장', '두 번째 문장']])['input_ids']
tokenizer.batch_decode(second_tokenized_result)['[CLS] 첫 번째 문장 [SEP] 두 번째 문장 [SEP]']
- 모델 학습에 사용할 연합 뉴스 데이터셋 다운로드
from datasets import load_dataset
klue_tc_train = load_dataset('klue', 'ynat', split='train')
klue_tc_eval = load_dataset('klue', 'ynat', split='validation')
klue_tc_train - 데이터 구조
klue_tc_train[0]
- title, label만 남기기
klue_tc_train = klue_tc_train.remove_columns(['guid', 'url', 'date'])
klue_tc_eval = klue_tc_eval.remove_columns(['guid', 'url', 'date'])
klue_tc_train- train 데이터 만들기
def make_str_label(batch):
batch['label_str'] = klue_tc_label.int2str(batch['label'])
return batch
klue_tc_train = klue_tc_train.map(make_str_label, batched=True, batch_size=1000)
klue_tc_train[0]- train/val 데이터 만들기
train_dataset = klue_tc_train.train_test_split(test_size=10000,
shuffle=True, seed=42)['test']
dataset = klue_tc_eval.train_test_split(test_size=1000, shuffle=True, seed=42)
test_dataset = dataset['test']
valid_dataset = dataset['train'].train_test_split(test_size=1000,
shuffle=True, seed=42)['test']- title 항목을 토큰화하는 함수
import torch
import numpy as np
from transformers import (
Trainer,
TrainingArguments,
AutoModelForSequenceClassification,
AutoTokenizer
)
def tokenize_function(examples):
return tokenizer(examples["title"], padding="max_length", truncation=True)- 토큰화 함수를 적용해 모델에 입력 가능한 형태로 변환
model_id = "klue/roberta-base"
model = AutoModelForSequenceClassification.from_pretrained(
model_id,
num_labels=len(train_dataset.features['label'].names))
tokenizer = AutoTokenizer.from_pretrained(model_id)
train_dataset = train_dataset.map(tokenize_function, batched=True)
valid_dataset = valid_dataset.map(tokenize_function, batched=True)
test_dataset = test_dataset.map(tokenize_function, batched=True)- 모델 학습에 필요한 설정 정의
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
evaluation_strategy="epoch",
learning_rate=5e-5,
push_to_hub=False
)- 모델의 예측결과와 실제 라벨을 비교하여 정확도 계산 함수
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return {"accuracy": (predictions == labels).mean()} - 학습 (허깅페이스의 트레이너 이용)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()- evaluation 결과
trainer.evaluate(test_dataset) 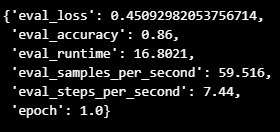
직접 학습해보기
import torch
from tqdm.auto import tqdm
from torch.utils.data import DataLoader
from transformers import AdamW
def tokenize_function(examples):
return tokenizer(examples["title"], padding="max_length", truncation=True)- 모델
device = 'cuda' # 'cuda' 'cpu
model_id = "klue/roberta-base"
model = AutoModelForSequenceClassification.from_pretrained(
model_id,
num_labels=len(train_dataset.features['label'].names))
tokenizer = AutoTokenizer.from_pretrained(model_id)
model.to(device)- 데이터로더로 train, test, val 데이터
def make_dataloader(dataset, batch_size, shuffle=True):
dataset = dataset.map(tokenize_function, batched=True).with_format("torch")
dataset = dataset.rename_column("label", "labels")
dataset = dataset.remove_columns(column_names=['title'])
return DataLoader(dataset, batch_size=batch_size, shuffle=shuffle)
train_dataloader = make_dataloader(train_dataset, batch_size=8, shuffle=True)
valid_dataloader = make_dataloader(valid_dataset, batch_size=8, shuffle=False)
test_dataloader = make_dataloader(test_dataset, batch_size=8, shuffle=False)- 훈련
def train_epoch(model, data_loader, optimizer):
model.train()
total_loss = 0
for batch in tqdm(data_loader):
optimizer.zero_grad()
input_ids = batch['input_ids'].to(device) # 모델에 입력할 토큰 아이디
attention_mask = batch['attention_mask'].to(device) # 모델에 입력할 어텐션 마스크
labels = batch['labels'].to(device) # 모델에 입력할 레이블
outputs = model(input_ids, attention_mask=attention_mask, labels=labels) # 모델 계산
loss = outputs.loss # 손실
loss.backward() # 역전파
optimizer.step() # 모델 업데이트
total_loss += loss.item()
avg_loss = total_loss / len(data_loader)
return avg_loss- evaluation 코드
def evaluate(model, data_loader):
model.eval()
total_loss = 0
predictions = []
true_labels = []
with torch.no_grad():
for batch in tqdm(data_loader):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
logits = outputs.logits
loss = outputs.loss
total_loss += loss.item()
preds = torch.argmax(logits, dim=-1)
predictions.extend(preds.cpu().numpy())
true_labels.extend(labels.cpu().numpy())
avg_loss = total_loss / len(data_loader)
accuracy = np.mean(np.array(predictions) == np.array(true_labels))
return avg_loss, accuracy- 학습
num_epochs = 1
optimizer = AdamW(model.parameters(), lr=5e-5)
for epoch in range(num_epochs):
print(f"Epoch {epoch+1}/{num_epochs}")
train_loss = train_epoch(model, train_dataloader, optimizer)
print(f"Training loss: {train_loss}")
valid_loss, valid_accuracy = evaluate(model, valid_dataloader)
print(f"Validation loss: {valid_loss}")
print(f"Validation accuracy: {valid_accuracy}")- 테스트 acc
_, test_accuracy = evaluate(model, test_dataloader)
print(f"Test accuracy: {test_accuracy}") # 정확도 0.82- 추론을 위한 함수
def inference(model, tokenizer, text, device):
model.eval()
label_names = ['IT과학', '경제', '사회', '생활문화', '세계', '스포츠', '정치']
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=512)
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=-1)
predicted_label = predictions.item()
return label_names[predicted_label]- 결과
# 추론을 위한 텍스트 준비
text = "중국과 미국과 일본 사이에서 우리의 위치는 어디일까?"
result = inference(model, tokenizer, text, device)
print(f"입력 텍스트: {text}")
print(f"예측된 카테고리: {result}")
- 모델 저장
import os
# 모델 저장 경로 설정
output_dir = "my_model"
os.makedirs(output_dir, exist_ok=True)
# 모델 저장
model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
print(f"Model and tokenizer saved to {output_dir}")- 추론해서 저장한 모델 재사용
from transformers import pipeline
model_id = "./my_model"
classifier = pipeline("text-classification", model=model_id, framework="pt")
label_names = ['IT과학', '경제', '사회', '생활문화', '세계', '스포츠', '정치']
# Test the loaded pipeline
text = "중국과 미국과 일본 사이에서 우리의 위치는 어디일까?"
result = classifier(text)
print(f"입력 텍스트: {text}")
print(f"예측된 카테고리: {label_names[int(result[0]['label'].split('_')[1])]}")- 커스텀 추론기
import torch
from torch.nn.functional import softmax
from transformers import AutoModelForSequenceClassification, AutoTokenizer
class CustomPipeline:
def __init__(self, model_id):
self.model = AutoModelForSequenceClassification.from_pretrained(model_id)
self.tokenizer = AutoTokenizer.from_pretrained(model_id)
self.model.eval()
self.label_names = ['IT과학', '경제', '사회', '생활문화', '세계', '스포츠', '정치']
def __call__(self, texts):
tokenized = self.tokenizer(texts, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = self.model(**tokenized)
logits = outputs.logits
probabilities = softmax(logits, dim=-1)
scores, labels = torch.max(probabilities, dim=-1)
labels_str = [self.model.config.id2label[label_idx] for label_idx in labels.tolist()]
return label_names[int(labels_str[0].split('_')[1])], scores[0].item()- 커스텀 추론 사용
model_id = "./my_model"
custom_pipeline = CustomPipeline(model_id)
custom_pipeline(text)
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
