Chapter8 영상에 모델 활용하기
모델 동영상에 활용하기
- 사용 데이터: AI Hub에서 제공하는 로봇 관점 주행 영상

- 필요 모듈 import
import cv2
import mmcv
from mmcv.transforms import Compose
from mmdet.apis import inference_detector, init_detector
from mmdet.registry import VISUALIZERS
import tqdm- 필요 파일 경로 정의
video = './video_test_in.mp4'
config = './panoptic_secondset_config.py'
checkpoint = './work_dirs/panoptic_secondset_config/epoch_4.pth'
device = 'cuda:0'
score_thr = 0.5
out = './video_out.mp4'model = init_detector(config, checkpoint, device=device)
model.cfg.test_dataloader.dataset.pipeline[0].type = 'mmdet.LoadImageFromNDArray'
test_pipeline = Compose(model.cfg.test_dataloader.dataset.pipeline)
visualizer = VISUALIZERS.build(model.cfg.visualizer)
visualizer.dataset_meta = model.dataset_meta
video_reader = mmcv.VideoReader(video)
video_writer = Noneif out:
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(
out, fourcc, video_reader.fps,
(video_reader.width, video_reader.height))
for frame in tqdm.tqdm(video_reader):
result = inference_detector(model, frame, test_pipeline=test_pipeline)
visualizer.add_datasample(
name='video',
image=frame,
data_sample=result,
draw_gt=False,
show=False,
pred_score_thr=score_thr
)
frame = visualizer.get_image()
video_writer.write(frame)
video_writer.release()
cv2.destroyAllWindows()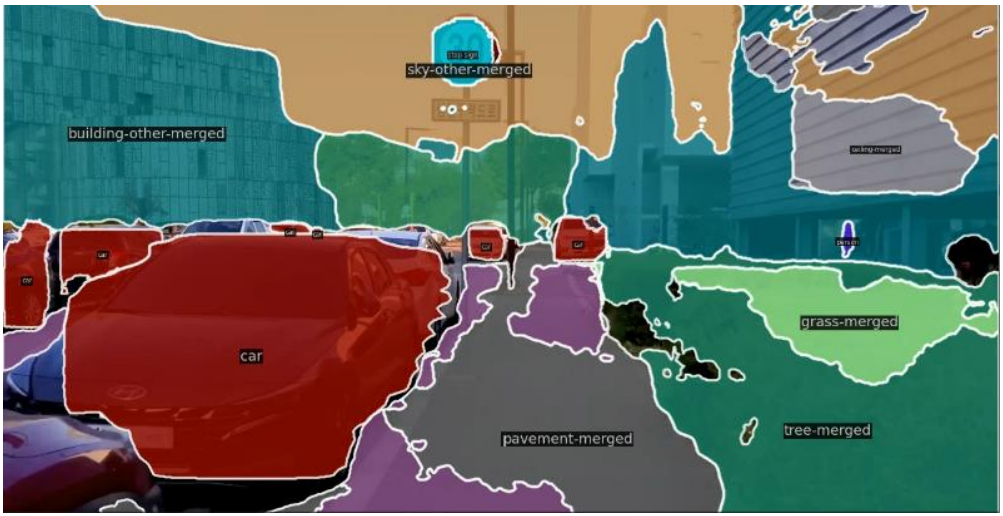
웹캠에 활용하기
import cv2
import mmcv
import torch
import sys
from mmdet.apis import inference_detector, init_detector
from mmdet.registry import VISUALIZERSconfig = './panoptic_secondset_config.py'
checkpoint = './epoch_4.pth'
device_sel = 'cpu' #GPU 사용 시 'cuda:0'
camera_id = 0
score_thr = 0.5device = torch.device(device_sel)
model = init_detector(config, checkpoint, device=device)visualizer = VISUALIZERS.build(model.cfg.visualizer)
visualizer.dataset_meta = model.dataset_metacamera = cv2.VideoCapture(camera_id, cv2.CAP_DSHOW)
width = camera.set(cv2.CAP_PROP_FRAME_WIDTH, 320)
height = camera.set(cv2.CAP_PROP_FRAME_HEIGHT, 240)
width = camera.get(cv2.CAP_PROP_FRAME_WIDTH)
height = camera.get(cv2.CAP_PROP_FRAME_HEIGHT)
print('changed resolution width {}, height {}'.format(width, height))while True:
ret_val, img = camera.read()
img = mmcv.imconvert(img, 'bgr', 'rgb')
result = inference_detector(model, img)
visualizer.add_datasample(
name='result',
image=img,
data_sample=result,
draw_gt=False,
pred_score_thr=score_thr,
show=False
)
img = visualizer.get_image()
img = mmcv.imconvert(img, 'rgb', 'bgr')
cv2.imshow('result', img)
ch = cv2.waitKey(1)
if ch == 27 or ch == ord('q') or ch == ord('Q'):
sys.exit()이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
