Chapter 3 Detection
-
데이터셋 확보
Aquarium Dataset -
구글 코랩 환경에서 데이터 셋 저장할 폴더 생성 후 다운로드
!mkdir dataset!wget Raw URL -O dataset/aquarium.zip- 데이터 셋 압축 해제
!unzip dataset/aquarium.zip -d dataset/aquarium- YOLO 설치
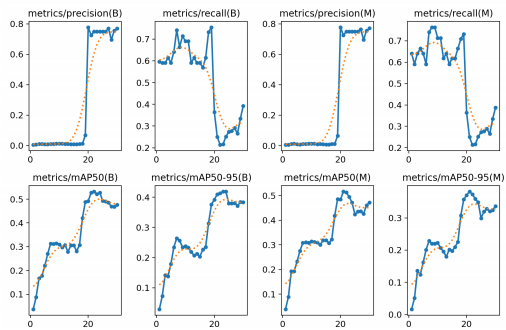
- 학습 시작
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
model.train(data='./dataset/aquarium/data.yaml')-
학습 진행 시 정상적으로 실행되지 않고 error발생하면 data.yaml 파일 내용에 path 추가
-
코랩에서 학습시킨 모델 파일 best.pt 다운 받기
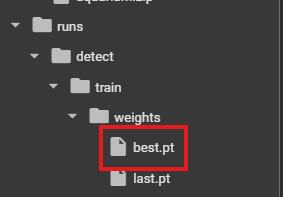
-
VSCode 환경에서 모델 확인하기(영상으로 확인)
from ultralytics import YOLO
model = YOLO('./best.pt')
model.predict(source='https://youtu.be/W0u-7lgWXpw?si=5bsFsKPh3hi1UaT9', show=True)
Chapter 4 Segmentation
!pip install ultralyticsimport ultralytics
ultralytics.checks()!yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg'
-
직접 데이터셋 만들어서 학습 진행
-
yolo 가상환경에서 필요한 모듈 설치 진행
pip install pyqt5pip install labelme- labelme가 정상적으로 설치되지 않을 경우 github에서 다운로드 받고, setup.py파일에서 일부 내용 수정(encoding)
def get_long_description():
with open("README.md", encoding='utf-8') as f:
long_description = f.read()-labelme 실행
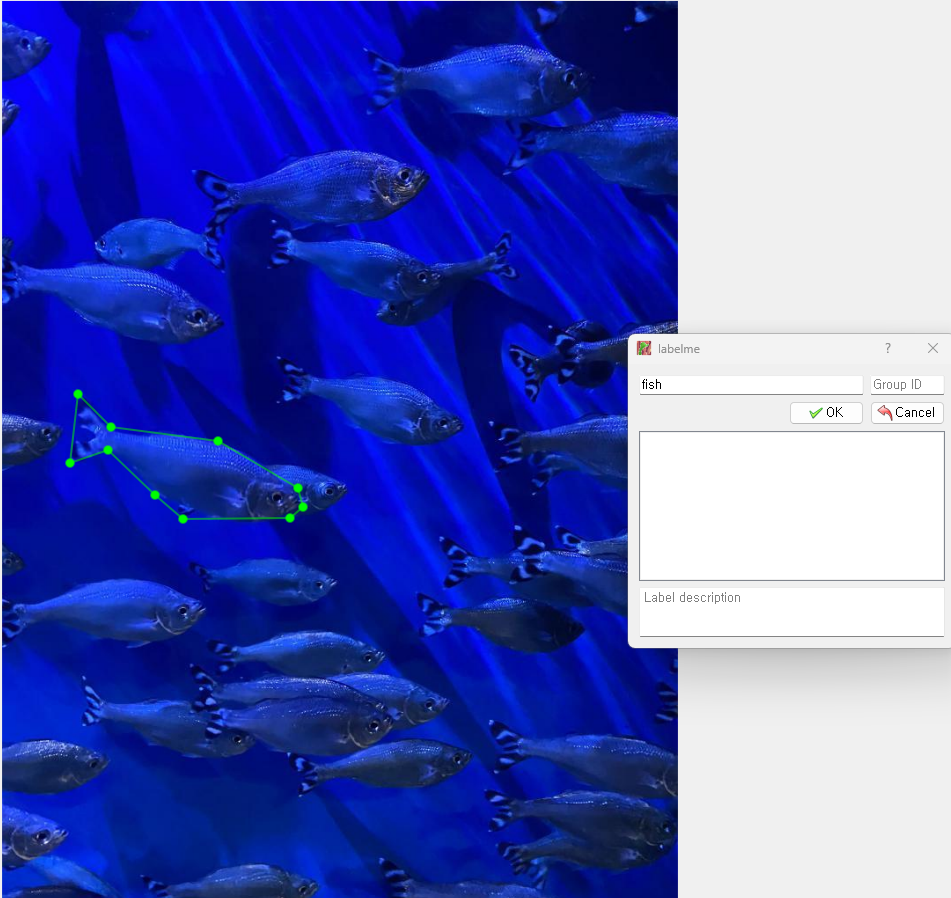
- 라벨링 완료 후 cmd 창에서
labelme2yolo --json_dir ./ --val_size 0.15 --test_size 0.15- 완성된 yolodataset 폴더를 구글 드라이브로 업로드
- 코랩 환경으로 돌아와서 구글 드라이브 마운트
from ultralytics import YOLO
model = YOLO('yolov8n-seg.pt')
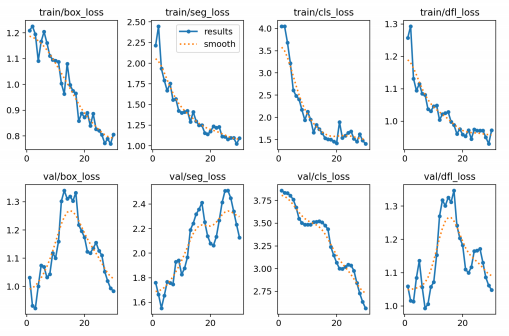
model.train(data = '파일 경로/dataset.yaml',
epochs=100)- 에러 발생시 dataset.yaml 파일 내 경로 추가

이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
