Chapter 11 현대적인 인공신경망
Fully-Convolutional Networks (FCN)
-
전결합계층 없이 합성곱 계층만을 이용한 네트워크
-
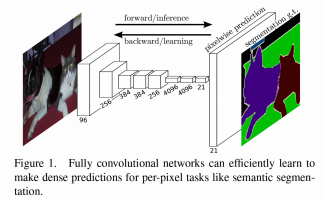
의미론적 영상 분할을 위한 딥러닝 모델로, 픽셀 단위로 레이블을 분류하는 문제 해결
-
일반적인 합성곱 신경망과의 차이점
-> 전체 영상을 분류하는 대신 픽셀별로 분류
-> 마지막 계층에 전결합 계층을 사용하지 않음
-
FCN의 구조
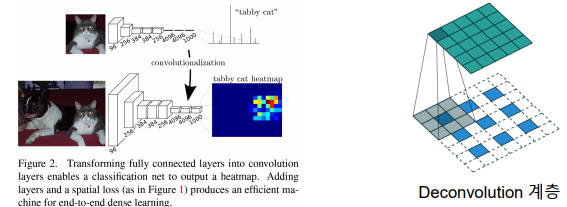
-> 합성곱 계층으로만 구성하여, 전형적인 CNN 구조에서 전결합 계층을 제거
-> 마지막 레이어에서 입력 이미지와 동일한 크기의 이미지를 출력
-> 업샘플링을 통해 입력 이미지와 동일한 해상도로 복원
-> 디콘볼루션 계층 또는 인터폴레이션 방식 사용
-
FCN의 특징
-> 다양한 크기의 영상을 처리할 수 있는 유연성을 갖춤
-> 공간 정보를 잃지 않고, 화소별로 클래스를 구분
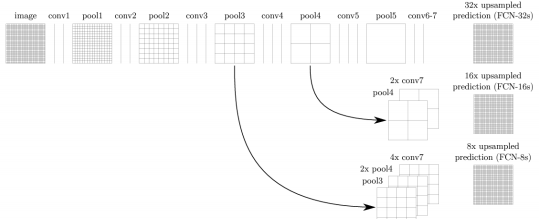
-> 세 가지 변형: FCN-32s, FCN-16s, FCN-8s
-> 다양한 업샘플링 단계를 사용하여 성능과 계산 효율성 균형
-
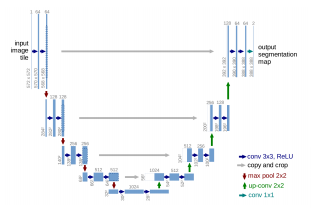
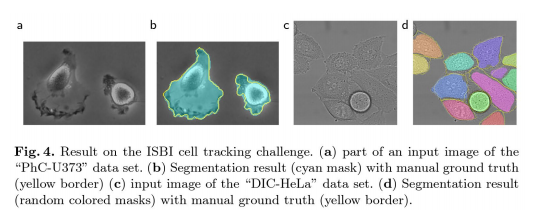
U-Net
-> 의료 영상(세포 이미지, MRI, CT 등) 분할을 위한 네트워크
-> FCN과 구조가 유사하나, 대칭 구조와 스킵 연결로 성능 개선
-> 인코더와 디코더로 이루어진 구조
• 인코더: 이미지의 특징 추출
• 디코더: 세분화된 구조 복원
-
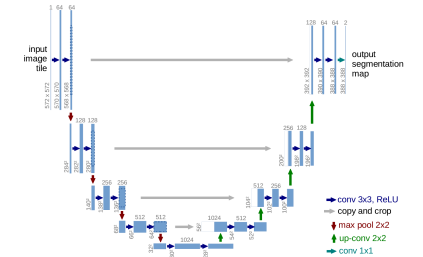
U-Net의 구조
-> 인코더: 일반적인 합성곱 신경망 구조(합성곱+풀링)로 특징 추출
-> 디코더: 업샘플링 레이어와 스킵 연결로 구성
-> 인코더에서 추출한 특징을 결합하여 복원
-> 디콘볼루션 레이어 또는 인터폴레이션 사용
-
U-Net의 특징
-> 데이터 증강(data augmentation)을 통해 적은 양의 데이터로도 효과적으로 학습 가능
-> 대칭형 구조와 스킵 연결로 인해 학습 효율성 증가
-> 스킵 연결로 세부 정보를 보존해, 고해상도 영상 분할에 적합
-
U-Net과 FCN의 비교
-> 두 네트워크 모두 의미론적 분할에 사용
--> 영상의 픽셀 단위로 레이블 분류
-> U-Net이 의료 영상에 특화되어 설계됨
--> 세포 이미지, MRI, CT 등의 의료 영상 분석
-> U-Net은 대칭형 구조와 스킵 연결로 세부 정보를 더 잘 보존
--> 고해상도 영상에서 세분화된 구조 파악 가능
-> U-Net은 메모리를 많이 사용한다는 단점이 있음
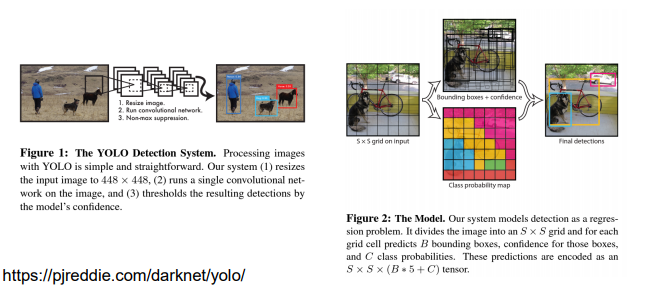
YOLO: You Only Look Once
-
딥러닝을 이용한 다중 물체 검출(multi-object detection; MOD)으로, 딥러닝을 창의적으로 사용한 문제작
-
최소한의 후처리(Non-maximal suppression)만으로 구현된 알고리즘
-
YOLO의 구조
-> 합성곱 계층과 전결합 계층으로 이루어진 보편적인 CNN 구조
-> 출력 계층을 단순 소프트맥스 출력이 아닌, 다른 방식으로 해석하여 많은 수의 물체를 동시에 검출

-
Non-Maximzl Suppression
-> 과도하게 검출 결과가 많을 경우, 중복되는 결과를 제거하는 기법
-> Confidence score가 높은 bounding-box와 일정 이상 겹치는 경우 제거하는 방식으로 구현
-> IOU: Intersection Over Union

-
YOLOv2 개선 사항
-> 바운딩 박스의 학습을 개선하기 위해 사전 지식 활용
-> 전결합계층을 제거하여 입력 영상의 크기 제한을 해제
-> 배치정규화, 다중 스케일 학습 등 적용
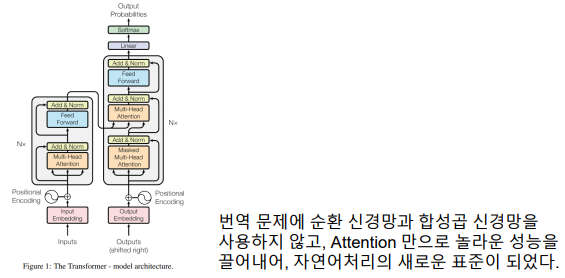
Attention is all you need (Transformer)
-
번역과 질문에 대한 답변에 특화된 심층신경망 모델
-
Attention 모듈을 이용해 기울기 소실 문제를 획기적으로 해결
-
현세대 자연어처리 모델의 표준 (GPT가 해당 구조)
-
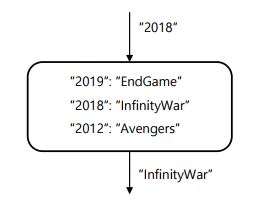
Query와 Key-Value: Attention 모듈의 입력으로, 아래와 같은 의미를 가짐
-> Query – 질의. 찾고자 하는 대상
-> Key – 키. 저장된 데이터를 찾고자 할 때 참조하는 값
-> Value – 값. 저장되는 데이터
-
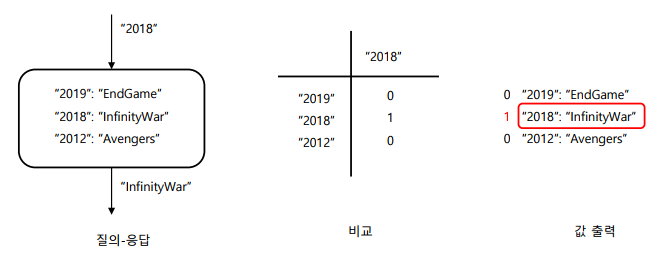
Querying: 질의에 의해 최종적으로 값을 출력하는 과정
-
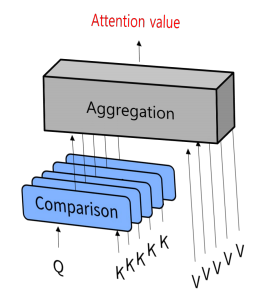
Attention 매커니즘: Q에 대해 각 K가 얼마나 유사한지 비교하고, 유사도를 반영하여 V를 합성하여 출력한 것이 Attention value에 해당
-
Seq2seq
-> 트랜스포머 모델의 기반이 되는 순환 신경망 모델
-> 순환 신경망에 Attention 매커니즘을 적용하여 기울기 소실 방지
-> Encoder – Decoder 구조로 이루어져 입출력 길이가 유연함
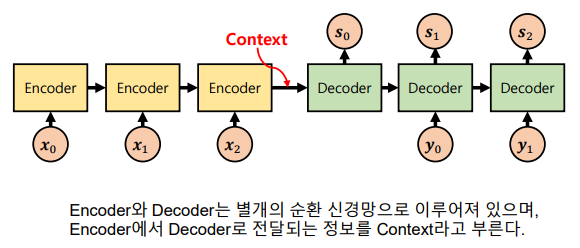
-
Seq2seq와 Attention 모듈: Context 만으로는 정보 전달이 충분치 못하기 때문에, Attention value를 적용하여 Encoder와 Decoder를 더 유기적으로 연결
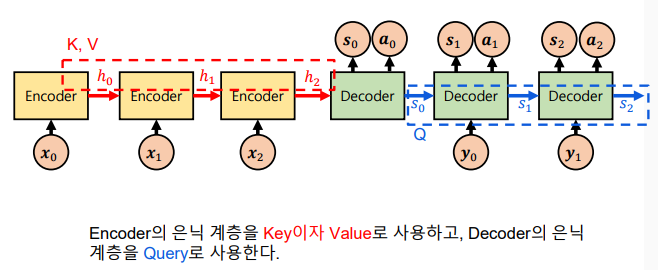
-
Transformer 네트워크 특성
-> Encoder-Decoder와 유사한 Transformer 구조 사용
-> Scaled Dot-Product Attention과, 이를 병렬로 나열한 Multi-Head Attention 블록이 알고리즘의 핵심
-> RNN의 BPTT와 같은 과정이 없으므로 병렬 계산 가능
-> 입력된 단어의 위치를 표현하기 위해 Positional Encoding 사용 -
입력과 출력
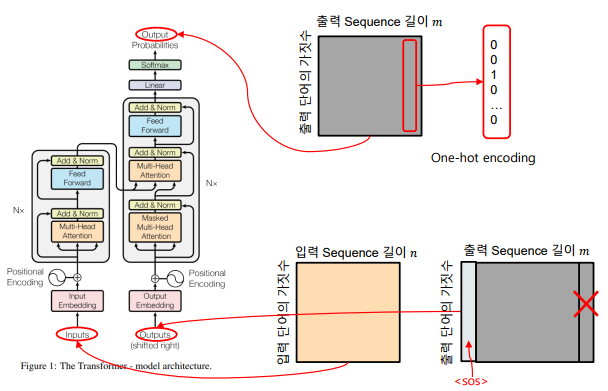
-
Word Embedding
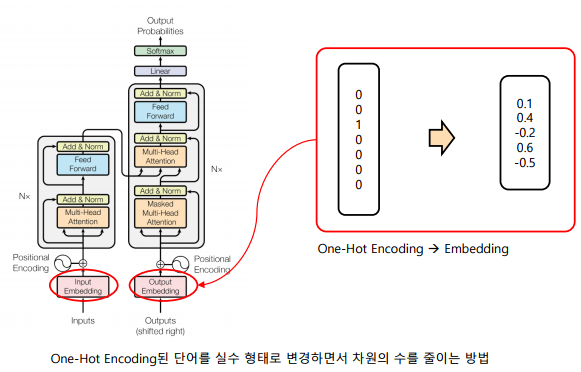
-
Positional Encoding
-> 시간적 위치별로 고유의 Code를 생성하여 더하는 방식
-> 전체 Sequence의 길이 중 상대적 위치에 따라 고유의 벡터를 생성하여 Embedding된 벡터에 더해줌

-
Scale Dot-Product Attention
-> Query, Key-Value의 구조를 띄고 있음
-> Q와 K의 비교 함수는 Dot-Product와 Scale로 이루어짐
-> Mask를 이용해 Illegal connection의 attention을 금지 (Causality)
-> Softmax로 유사도를 0 ~ 1의 값으로 Normalize
-> 유사도와 V를 결합해 Attention value 계산
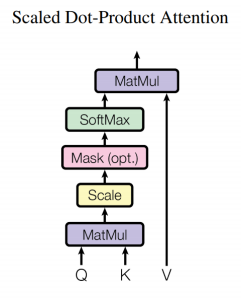
-
Multi-Head Attention
-> Linear 연산 (Matrix Mult)를 이용해 Q, K, V의 차원을 감소. Q와 K의 차원이 다른 경우 이를 이용해 동일하게 맞춤
-> h개의 Attention Layer를 병렬적으로 사용 – 더 넓은 계층
-> 출력 직전 Linear 연산을 이용해 Attention Value의 차원을 필요에 따라 변경
-> 이 메커니즘을 통해 병렬 계산에 유리한 구조를 가짐
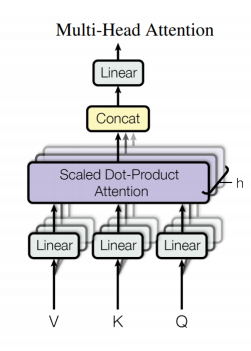
-
Masked Multi-Head Attention
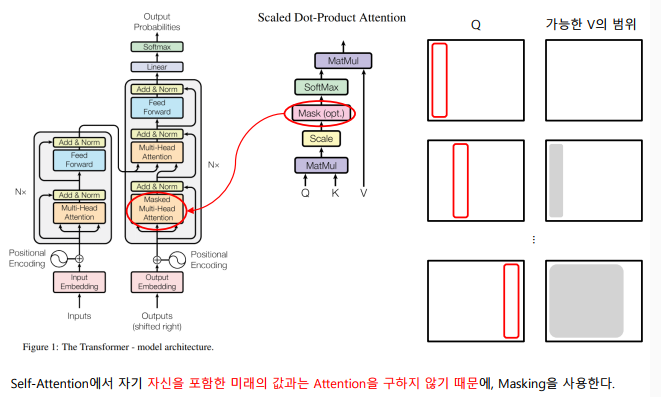
-
Multi-Head Attention in Action
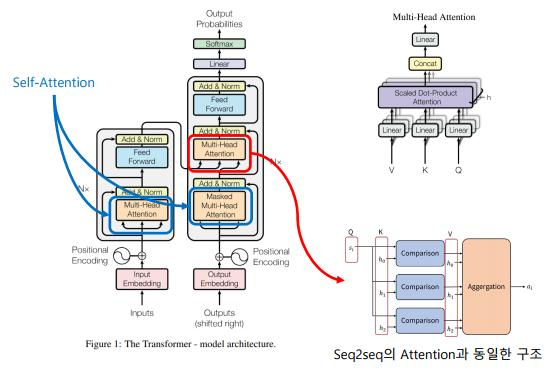
-
Position-Wise Feed-Forward

-
Add & Norm
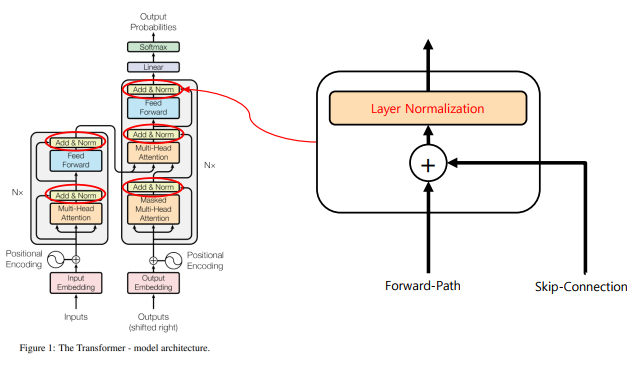
-
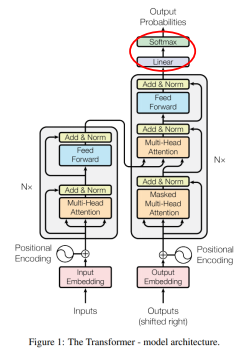
Output Softmax
-> Linear 연산(Matrix 곱셈)을 이용해 출력 단어 종류의 수에 맞춤
-> Softmax를 이용해 어떤 단어인지 Classification 문제 해결
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
