Chapter1 MediaPipe
분류기 사용해보기
- 이미지 분류
- 얼굴 방향
- 동작 감지

from IPython.display import Image, display
import cv2
def img_show(image, width=400):
_, buffer = cv2.imencode('.jpg', image)
display(Image(data=buffer, width=width))import mediapipe as mp
image1 = mp.Image.create_from_file(이미지 경로)
image = image1.numpy_view()
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
img_show(image) 
- 학습이 완료된 efficientnet이라는 모델을 이용해서 분류기 세팅
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
base_options = python.BaseOptions(model_asset_path=r'.\Data\effi.tflite')
options = vision.ImageClassifierOptions(base_options=base_options, max_results=4)
classifier = vision.ImageClassifier.create_from_options(options) for idx, category in enumerate(classification_result.classifications[0].categories):
text = f"{category.category_name}: {category.score:.2f}"
position = (10, 30 + idx * 30)
cv2.putText(image, text, position, cv2.FONT_HERSHEY_SIMPLEX,
1, (0, 255, 0), 2, cv2.LINE_AA)
img_show(image) 
pose estimation 사용해보기
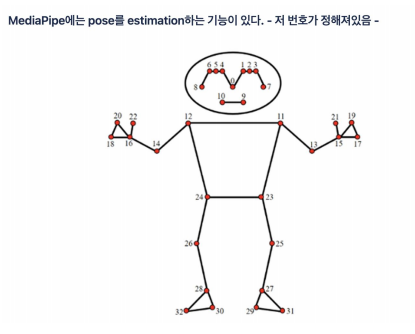
- mediapipe의 solution에서 pose를 받아오는 함수
def extract_landmarks_from_image(image):
mp_pose = mp.solutions.pose
pose = mp_pose.Pose(static_image_mode=True, min_detection_confidence=0.5)
results = pose.process(image)
return results- pose 찾기
image_raw = cv2.imread('.이미지 경로')
image = cv2.cvtColor(image_raw, cv2.COLOR_BGR2RGB)
results = extract_landmarks_from_image(image)
print(results)mp_pose = mp.solutions.pose
mp_drawing = mp.solutions.drawing_utils
mp_drawing.draw_landmarks(image_raw, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
img_show(image_raw, width=700) 
- 영상에서 pose를 추출하고 다시 영상에 입히는 함수
def video_pose_estimation(video_path, duration=10, width=600):
mp_pose = mp.solutions.pose
mp_drawing = mp.solutions.drawing_utils
cap = cv2.VideoCapture(video_path)
pose = mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5, min_tracking_confidence=0.5)
start_time = time.time()
while time.time() - start_time < duration:
_, frame = cap.read()
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = pose.process(image)
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
mp_drawing.draw_landmarks(image, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
video_show(image, width=width)
time.sleep(0.03)
cap.release()
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
