Chapter 9 표현학습
표현 학습(Representation learning) 소개
-
샘플을 의미 있는 데이터로 만드는 변환(transform)을 학습하는 방법
-
가공되지 않은 입력(raw input)보다 주어진 작업에 더 유용한 표현(representation)을 구하고자 할 때 사용
-> 입력을 변환한 결과를 특징(feature) 또는 임베딩(embedding)이라고 부름
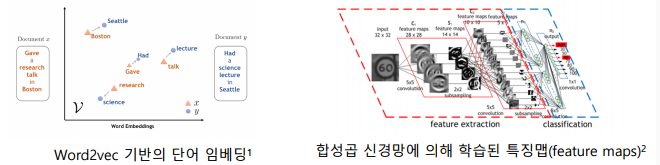
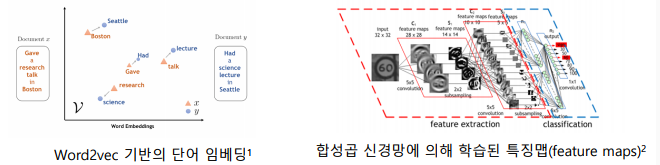
-
머신러닝에서 찾아볼 수 있는 표현 학습
-> 주성분분석(Principal component analysis; PCA)
-> 인공신경망의 은닉 계층(hidden layer)
-> 지도 사전 학습(supervised dictionary learning): 딥러닝 이전에 많이 사용되었던, 희소성(sparsity) 기반의 임베딩 기법
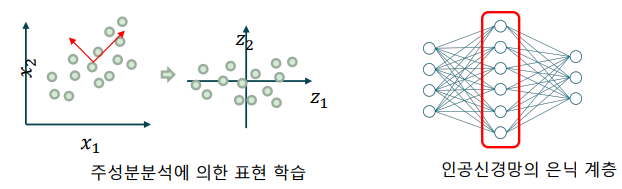
인공신경망의 가중치와 특징
-
인공신경망의 각 뉴런의 가중치의 의미
-> 각 뉴런의 가중치는 입력에서 특징을 추출하는 특징 추출기(feature extractor)를 의미
-> 학습된 가중치를 시각화하면 어떤 입력이 의미 있는지 유추할 수 있음
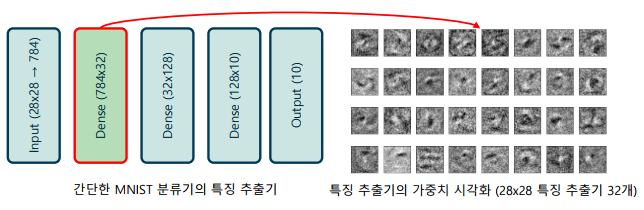
-
인공신경망의 은닉 계층(특징)의 의미
-> 계층에 입력이 가해졌을 때, 가중치에 의해 계산된 출력(은닉 계층)의 값을 특징(feature)이라고 부름
-> 가중치에 동일한 패턴이 입력에 있을 때, 이것이 강조되어 특징으로 추출되어 나옴
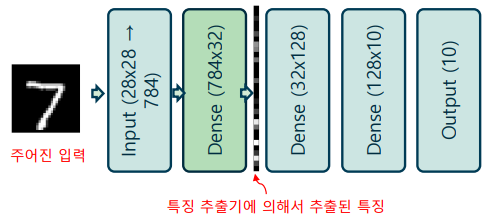
-
합성곱 신경망의 커널(kernel)의 의미
-> 커널의 크기만큼 공간 특성을 잡아내는 특징 추출기를 의미
-> 전결합계층과 달리, 특징의 패턴이 커널 공간 안에 포함 되어야만 함
-> 이러한 관점에서 보면 합성곱 신경망은 전결합계층(dense connection) 중에서 일부의 연결만 남겨둔 것(sparse connection)으로 해석할 수도 있음
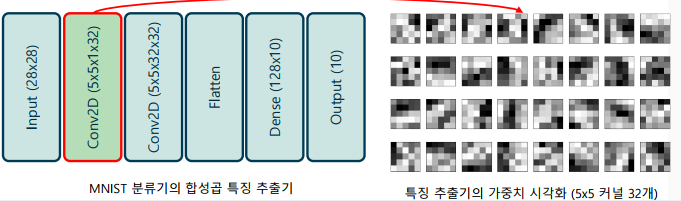
-
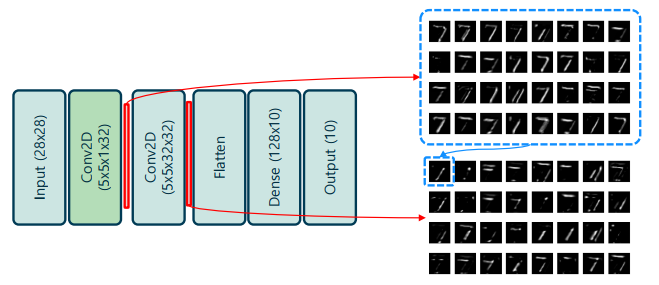
합성곱 신경망의 feature map의 의미
-> 입력과 커널의 합성곱 연산의 결과로 발생한 출력을 말함
-> 커널에 나타난 패턴과 동일한 패턴이 입력에 나타날 경우, 이것이 반응(response)하여 높은 값으로 나타남
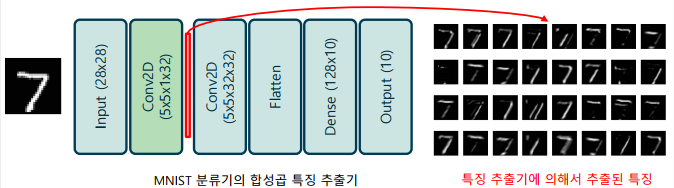
-> 합성곱 계층이 여러 번 나타날 경우, 각 특징맵은 이전 특징맵 전체를 사용하여 생성
사전 학습 모델과 전이 학습
-
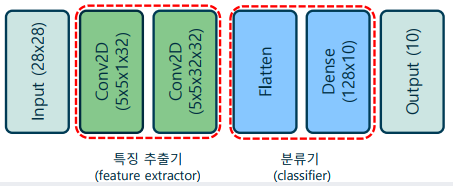
합성곱 신경망의 각 영역의 특징
-> 특징 추출기 – 가공되지 않은 입력(raw input)에서 의미있는 정보를
추출하여 표현(representation)을 수행하는 영역. 주로 합성곱 계층으로 이루어져, 공간적으로 인접한 영역의 정보를 취합
-> 분류기 – 앞서 특징 추출 영역에서 가공된 정보를 이용하여, 실질적인 분류 동작을 수행하는 영역. 주로 전결합계층과 softmax 활성함수를 이용해 좋은 결정 경계를 학습
-
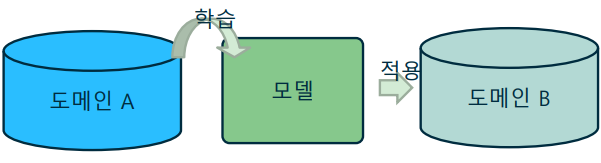
전이학습(Transfer learning)
-> A라는 도메인에서 학습한 모델을 B라는 다른 도메인에 적용하는 기술
-> 도메인에 무관한 보편적인 특성을 활용하여 차선책(suboptimal)을 빠르게 학습하는 방법
-> 모델 학습을 위한 계산 비용을 절약하거나, 모델 학습의 난이도를 대폭 낮출 수 있음
-
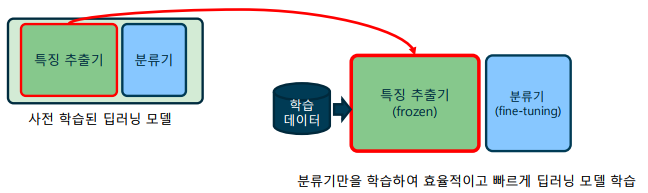
사전 학습 모델(Pre-trained models)
-> 유명한 이미지 특징 추출기는 사전에 학습된 가중치가 공개되어 있음
-> 대표적인 사전 학습 모델 - VGG-Net, ResNet, DenseNet 등 -
사전 학습 모델을 이용한 전이학습: 사전 학습 모델을 불러온 후, 분류기 부분만 새로 만들어 학습
-> 새로운 부분만 학습하는 과정을 세부 튜닝(fine-tuning)이라 함
-> 학습 효율을 위해 보통 사전 학습 모델은 고정(freeze)하여 사용
-> 모델을 고정할 경우, 중간 결과나 미분이 필요하지 않으므로 학습 중에 필요한 메모리가 대폭 감소
오토인코더(자가부호기 Autoencoder)
-
구조
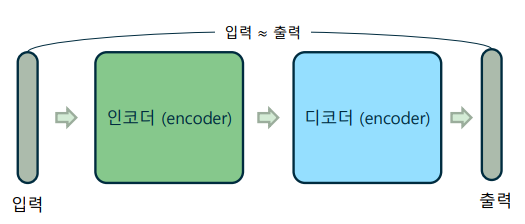
-> 인코더-디코더 구조로, 본래 입력에 최대한 가깝게 복호(decode)하는 것을 목표로 함
-> 입력과 함께 레이블이 주어지지 않으므로, 비지도 학습(unsupervised learning)에 해당
-
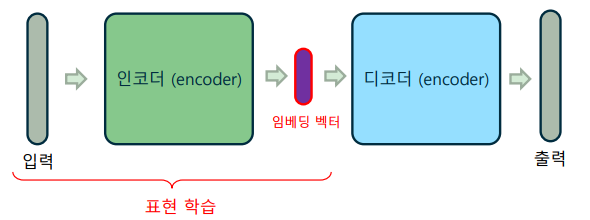
임베딩 벡터(Embedding vector)
-> 인코딩한 결과를 코드(code) 또는 임베딩 벡터라고 부름
-> 입력을 인코딩하는 과정을 표현(representation)이라고 하며, 이 과정을 학습하는 것을 표현 학습(representation learning)이라 함
-
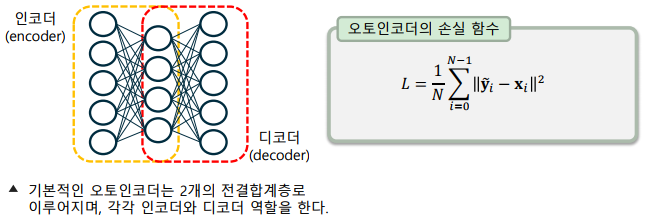
인공신경망으로 구현하는 인코더-디코더 구조
-> 입력 계층 – 인코딩하고자 하는 입력 데이터를 받는 계층
-> 은닉 계층 – 인코더(encoder)로, 보통 입력보다 더 적은 차원 수를 가짐, 더 적은 차원으로 입력 계층을 압축하여 표현하는 표현 학습
-> 출력 계층 – 디코더(decoder)로, 입력 계층과 동일한 차원을 가짐
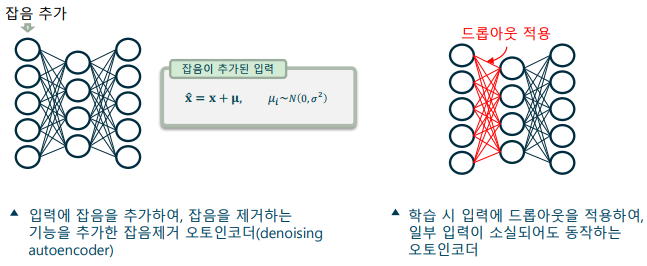
잡음제거 오토인코더(Denoising autoencoder)
- 입력 계층을 변형하여 잡음제거(denoising) 기능을 추가
-> 입력 계층에 가우시안 잡음을 추가하는 방법
-> 입력 계층에 드롭아웃을 적용하여 임펄스 잡음을 추가하는 방법
변분 오토인코더(Variational Autoencoder: VAE)
-
비지도 학습으로, 데이터의 고유한 특성을 학습하여 새로운 데이터를 생성할 수 있는 생성 모델(generative model)

-
입력 데이터를 잠재 변수 공간으로 인코딩하고, 그 공간에서 샘플링한 후 디코딩하여 원본 데이터를 복원하여 학습
-> 잠재 변수(Latent Variable) - 인코더에 의해 압축된 데이터의 표현으로, 디코더가 원본 데이터를 재구성하기 위한 출발점. 잠재 변수는 가우시안 분포를 따르는 확률 변수로 가정
-> 변분 추론(Variational Inference) - 잠재 변수의 사후 분포를 근사하는 방법. 변분 추론을 사용하여 인코더와 디코더 사이의 확률 분포를 최적화

-
인코더
-> 입력 데이터 로 잠재 변수 𝐳𝐳의 조건부 확률 분포 를 계산
-> 는 가우시안 분포를 따르며, 평균 𝛍및 표준편차 𝛔를 출력
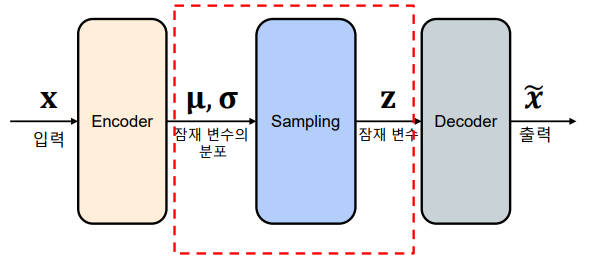
-
샘플링
-> 잠재 변수 를 로부터 샘플링 ->
-> 재파라미터화(reparameterization) 트릭으로 기울기(gradient) 계산 가능
-
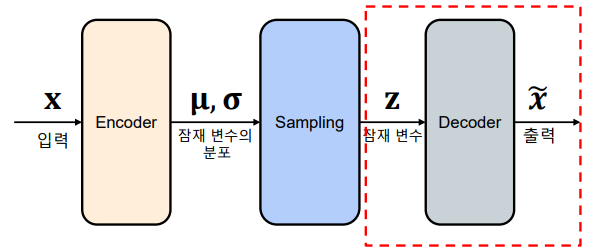
디코더
-> 잠재 변수 𝐳로부터 원본 데이터 𝐱의 확률 분포 를 계산
-> 를 사용하여 데이터를 복원(reconstruction)
-> 는 와 를 통해 계산해야 하나, 계산적으로 어려워 변분 추론을 사용 를 사용하는 대신 이를 근사하는 분포 사용
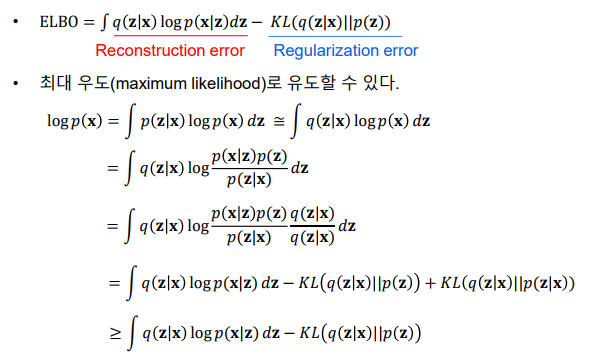
-
ELBO(Evidence Lower Bound): 변분 오토인코더의 손실함수로, 이를 최대화하여 모델을 학습

이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
