Chapter 8 합성곱 신경망
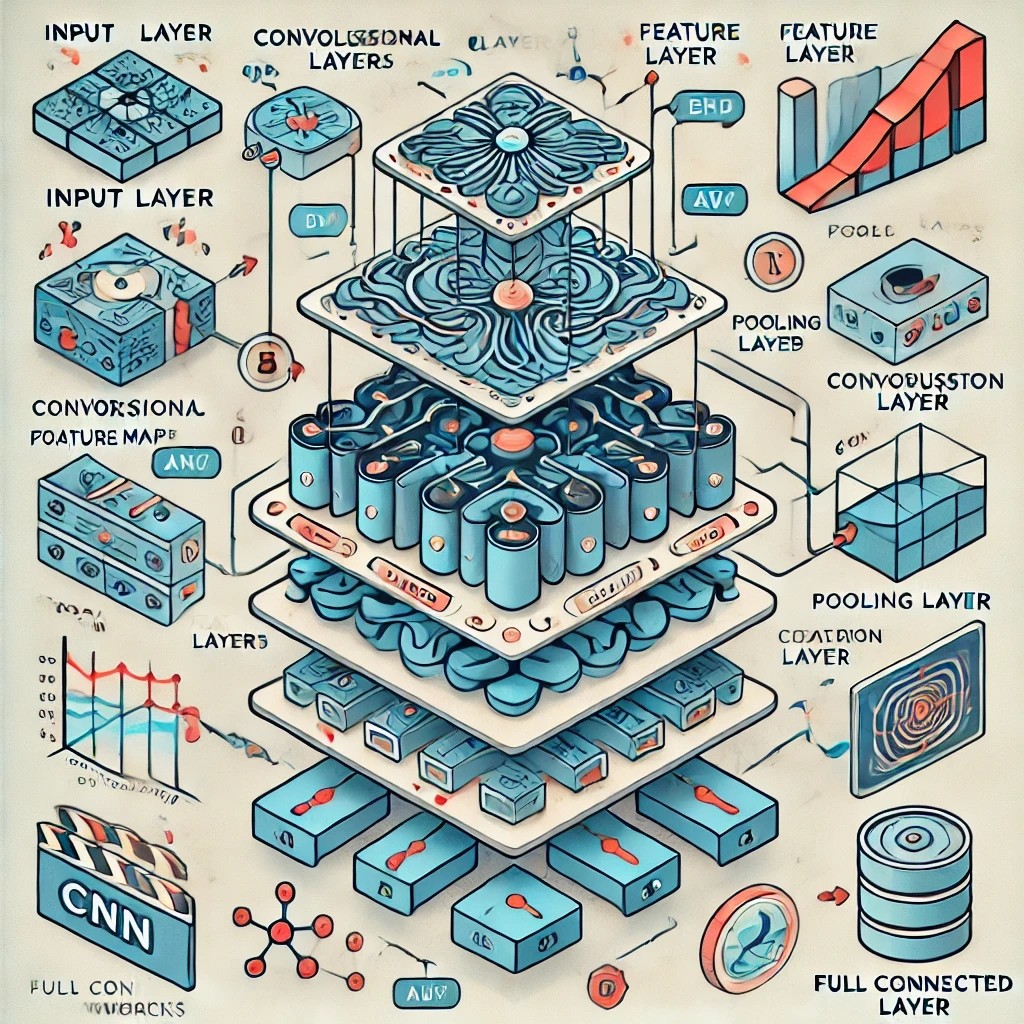
합성곱 신경망(Convolutional neural networks)
-
필터(filter)를 학습하여 합성곱 연산을 기반으로 하는 인공신경망
-
주로 영상(image)을 입력으로 하며, 다양한 기능을 구현할 수 있다.
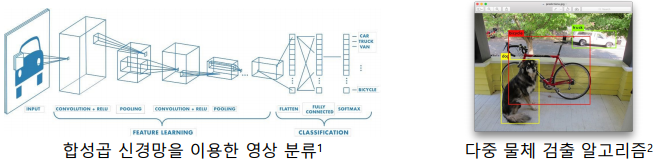
-> 영상 분류: 영상의 내용을 분석하여 어떤 클래스인지 분류 (합성곱은 특징 추출에 사용)
-> 영상 복원(restoration): 훼손된 영상을 입력 받아 본래의 영상으로 복원
-> 다중 물체 검출: 영상에서 다양한 물체를 동시에 검출하는 알고리즘
-
합성곱 신경망의 다양한 애플리케이션

신호처리와 합성곱 연산
-
선형 시불변 시스템 (Linear Time Invariant: LTI)
-> 시간에 영향받지 않고 선형적인 신호 처리 시스템
-> LTI 시스템은 잡음 제거, 미분, 패턴 인식 등 다양한 기능을 함

-
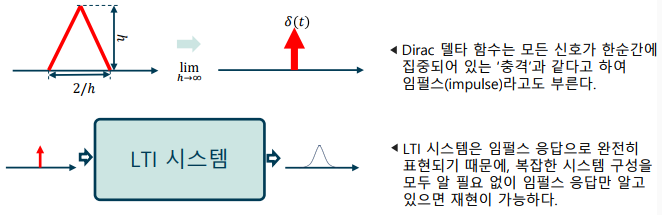
Dirac 델타 함수
-> 적분이 1이고, 한 순간에 모든 신호가 집중된 함수 -
임펄스 응답 (Impulse response)
-> LTI 시스템에 Dirac 델타 함수 신호를 입력했을 때의 출력
-> LTI 시스템을 완전히 표현하며, 필터(filter)라고도 부름
-
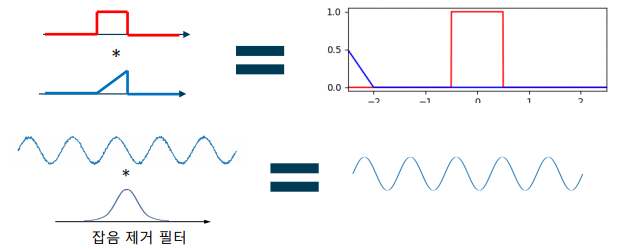
합성곱 연산(Convolution)
-> 두 함수(신호)를 합성하는 연산
-> 신호 하나를 뒤집고 이동하면서, 두 신호의 곱을 적분(합산)하여 계산
-> LTI 시스템은 입력신호에 필터를 합성곱한 결과와 같음
영상 신호와 합성곱 연산
-
이차원 신호로 표현되는 영상 신호(image signal)
-> 이차원 신호는 신호값을 밝기로 변환하여 시각화할 수 있음
-> 반대로, 영상은 밝기를 신호값으로 하여 이차원 신호로 표현
-> 컬러 영상은 보통 RGB 등의 3개 채널로 표현

-
이차원 디지털 신호(영상 신호)는 상하와 좌우를 모두 뒤집어 합성곱 계산을 수행
-> 상관 (correlation) – 합성곱과 달리 신호를 뒤집지 않고 가중합을 수행하는 연산
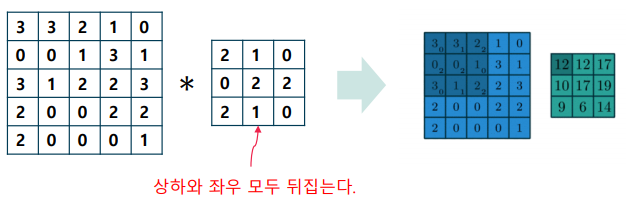
합성곱 기법
-
패딩(Padding)
-> 합성곱 연산 과정에서 필터의 크기에 따라 영상의 크기가 감소
-> 영상이 줄어드는 만큼 미리 크기를 늘여서 이 문제를 해결
-> 0으로 채우는 경우 제로 패딩이라고 하며, 신호를 반복하거나 거울처럼 뒤집어 채우기도 함
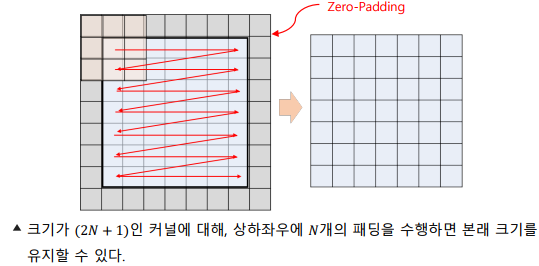
-
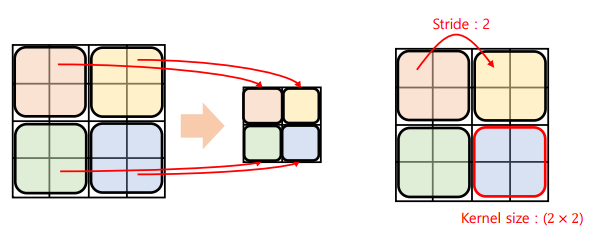
스트라이드(Stride): 합성곱 연산에서 커널(필터)가 이동하는 단위로, 1보다 크면 출력의 크기를 감소시킴 (출력의 크기를 반으로 줄이고 싶을 때 사용)
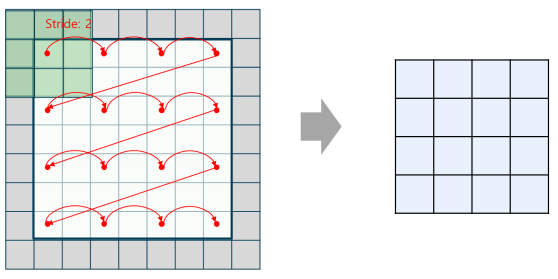
합성곱 계층
-
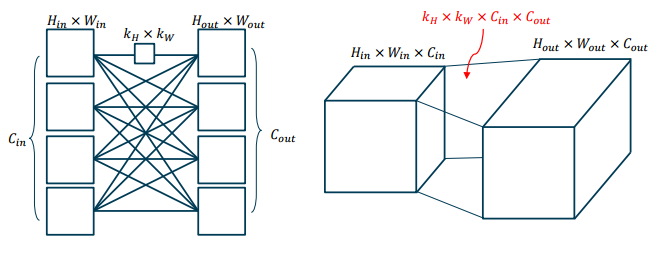
합성곱 계층의 기본 구성: 전결합계층의 뉴런의 곱연산을 합성곱 연산으로 변환
-> 가중치 대신 필터(filter)를, 각 입력을 영상(이차원 신호)로 변환
-> 보조 변수 대신 편향(bias)를 사용
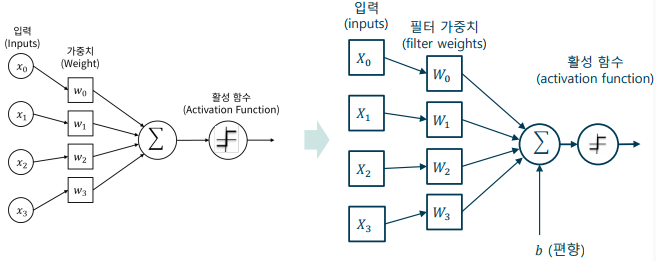
-
합성곱으로 이루어진 뉴런을 전결합 형태로 연결한 것으로 가중치의 형식을 필터(filter) 또는 커널(kernel)이라고 부름
-
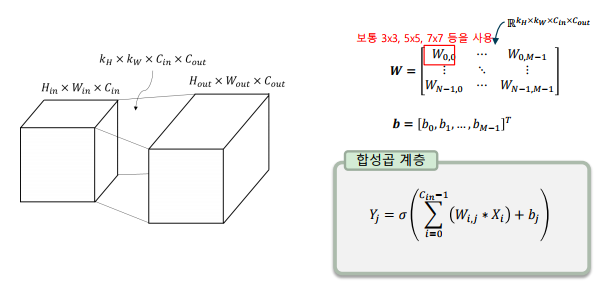
합성곱 계층은 번의 합성곱 연산으로 이루어짐, 편향은 각 출력마다 하나의 스칼라 합으로 이루어짐
import tensorflow as tf
x = tf.random.normal((32, 128, 128, 3)) # (N, H, W, C)
conv_layer = tf.keras.layers.Conv2D(filters=32, # number of filters (output channels)
kernel_size=(5, 5), # convolution kernel size => 총 Weight 텐서 크기 3 x 3 x 3 x 32
strides=(1, 1), # stride of convolution
padding='valid', # pad to make it same sized (cf. 'valid')
activation='relu') # activation function is set to ReLU
y = conv_layer(x)
y.shape # (N, H, W, 32)풀링 계층
-
특징 맵의 크기를 줄이는 계층
-> 여러 화소의 정보를 종합해 하나의 화소로 변환하는 계층
-> 풀링 계층을 통과하면 영상의 크기가 줄어드는 대신 정보가 집약
-
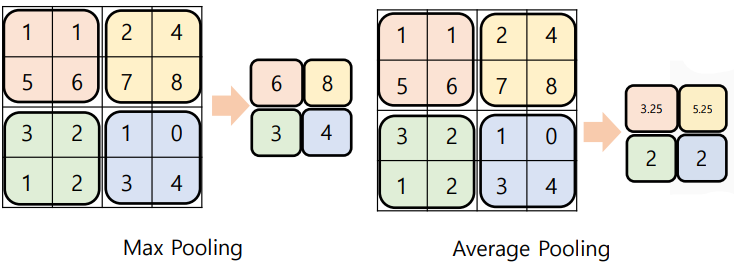
최댓값 풀링(max pooling): 커널 내의 최댓값을 사용
-
평균값 풀링(average pooling): 평균값을 사용
import tensorflow as tf
x = tf.random.normal((32, 128, 128, 3)) # (N, H, W, C)
pool = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=None, padding='valid')
y = pool(x)
y.shape
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='valid')(x).shape # (32, 64, 64, 3)
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(5, 5), padding='valid')(x).shape # (32, 26, 26, 3)
tf.keras.layers.MaxPooling2D(pool_size=(5, 5), padding='valid')(x).shape # (32, 25, 25, 3)
tf.keras.layers.MaxPooling2D(pool_size=(5, 5), padding='same')(x).shape # (32, 26, 26, 3)
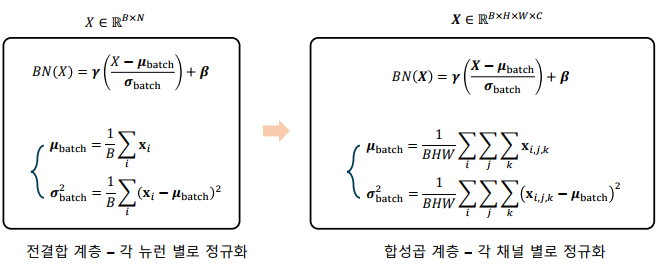
tf.keras.layers.AveragePooling2D(pool_size=(2, 2))(x).shape # (32, 64, 64, 3)배치 정규화 이론
-
Internal Covariate Shift: 학습 과정에서 계층별 입력 데이터 분포가 달라지는 현상
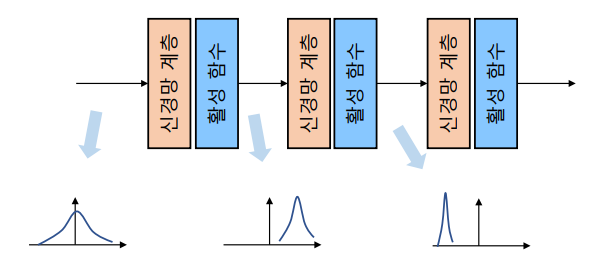
-
배치 정규화(batch normalization) 계층: 미니 배치 학습 과정에서 배치별로 특징을 정규화하는 계층
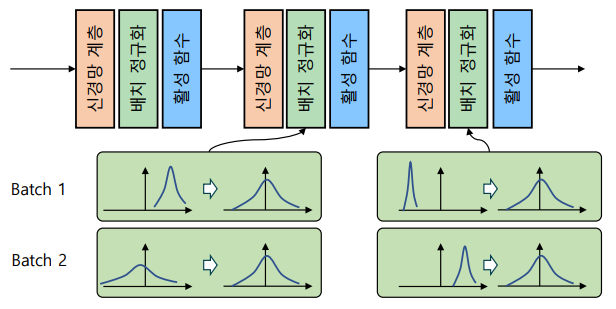
-
배치 정규화의 학습 과정
-> 모든 계층의 특징이 동일한 스케일이 되어 학습율 결정에 유리함
-> 추가적인 스케일과 편향 변수를 학습하여 활성 함수에 적합한 분포로 변환하여 사용
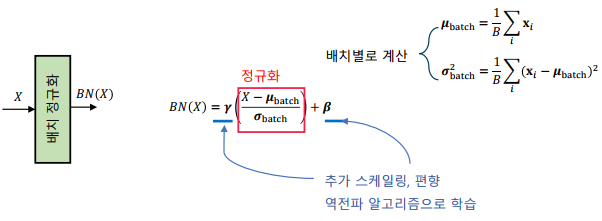
-
배치 정규화의 테슽 과정
-> 테스트 단계에서는 배치를 사용하지 않음
-> 평균과 분산을 이동 평균(또는 지수 이동 평균)으로 계산하여 고정
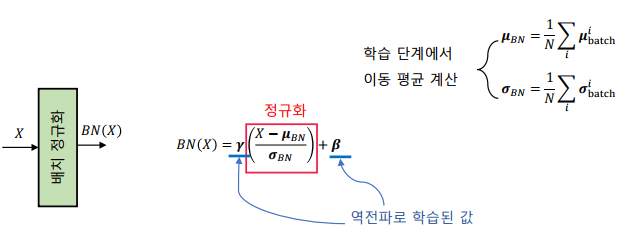
-
합성곱 계층의 배치 정규화: 합성곱 계층에 적용할 경우, 채널 별로 배치 정규화 수행
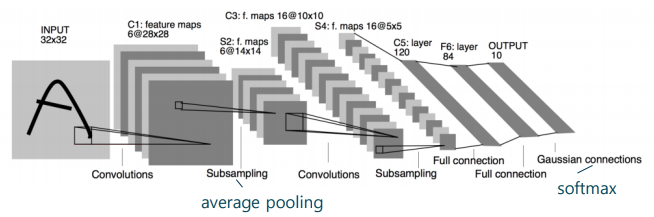
LeNet-5
- 합성곱 신경망(convolutional neural network; CNN)의 기본적인 구조를 잘 정립한 연구
- 합성곱 계층과 전결합 계층을 조합하여 다중 분류 문제 해결
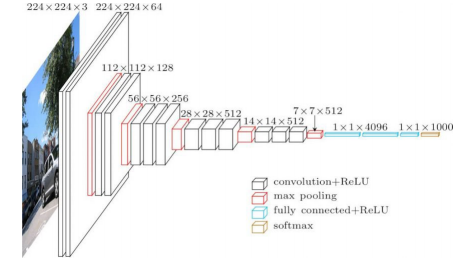
VGG-Net
- 이미지넷 영상 인식 경연 대회(ILSVRC) 에서 상위 입상한 딥러닝 모델로 대중적으로 사용되기 시작한 첫 딥러닝 모델
import cv2
import tensorflow as tf
import matplotlib.pyplot as plt
vgg16 = tf.keras.applications.VGG16( # VGG16 model
include_top=True, # include top layers (classifier)
weights="imagenet", # weights learned from imagenet
classes=1000, # classifies 1000 classes
classifier_activation="softmax", # activation function is softmax
)
img = cv2.imread('/content/fey-move.png') # read image by opencv
img = cv2.resize(img, (224, 224)) # resize image to (224, 224)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # reorganize image channels
img = img / 255.0 # input range from [0, 255] to [0.0, 1.0]
plt.imshow(img)
plt.show()
img = tf.constant(img)[tf.newaxis, ...] # (H, W, C) -> (N, H, W, C)
tf.keras.applications.vgg16.decode_predictions(vgg16.predict(img)) # classify the image
-> 신뢰하기 어려운 결과이지만 이런 방식으로 구동 된다
ResNet(Residual Network)
-
딥러닝 모델의 깊이와 성능을 대폭 향상시킨 기념비적인 모델
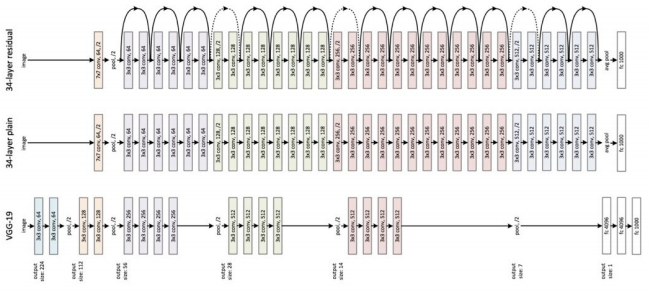
-
Skip Connection: 특징을 추출하기 전과 후를 더하는 특별한 연결 구조
-> 일반 구조에서 표현 가능한 특징은 residual 구조에서도 표현이 가능
-> 거듭된 연구로 전후 특징을 더한 후 활성 함수를 거치지 않는 identity mapping 구조 확립
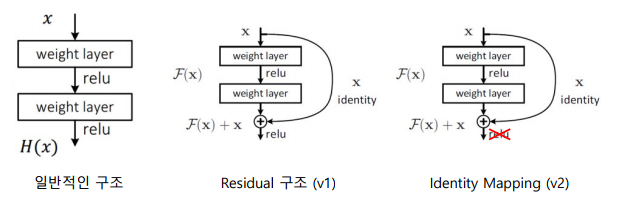
-
Pre-Activation 구조: 활성 함수를 합성곱 계층보다 앞쪽에 배치하는 구조
-> Identity mapping 형식의 skip connection을 적용하기 위해 제안
-> 기울기가 변형 없이 전달되는 gradient highway가 형성되어, 빠르고 안정적인 학습이 가능
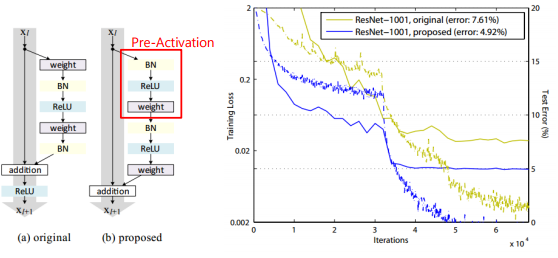
-
ResNet 구조
-> Identity mapping을 이용한 특징 추출
-> 풀링 계층을 대체하는 구조(점선 표기된 skip connection) 도입
-> 전결합계층과 softmax를 이용한 다중 분류
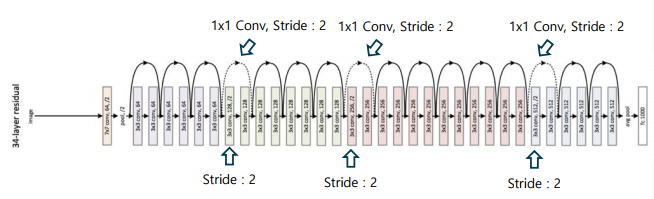
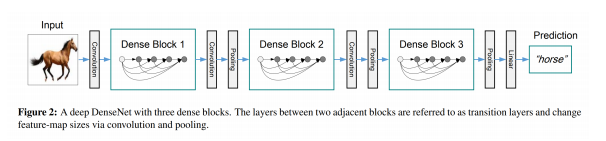
DenseNet
-
Densely Connected Network: ResNet을 계승하여, skip connection을 dense connection으로 변경한 모델
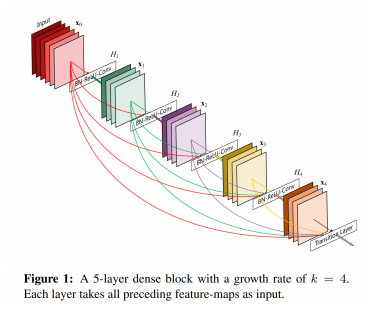
-
전체 구조: ResNet과 유사하게, 특징을 추출하는 Block과 Pooling으로 이루어져 있음
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
