Chapter 1 머신러닝 개요
머신러닝 이란
-
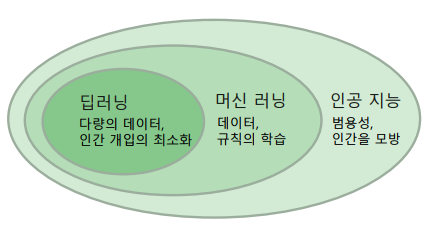
인공지능이 가장 넓은 범주에 속함
-
머신 러닝의 핵심은 데이터와 규칙의 학습 유무
-> IF-THEN 규칙으로 직접 행동 조건을 프로그래밍 하는 것은 머신러닝이 아님 -
인공지능(Artificial Intelligence): 컴퓨터가 사람의 행동을 모방하도록 하는 연구
-> 튜링테스트(1950년 앨런 튜링이 제안한 기계에 지능이 있는지 판별하는 방법)를 통해 인공지능의 수준 평가
-> 초기 연구에서는 규칙 기반 연구가 주를 이룸
-> 인공지능은 보통 강 인공지능(strong AI, 인간과 같이 감각, 사고력, 의식을 갖춘 인공 지능)을 의미함 -
머신러닝(Machine Learning): 기계가 데이터로부터 학습하여 특정한 작업의 성능을 향상시키도록 하는 연구 분야
-> 인공 지능과 달리, 행동의 규칙을 스스로 찾아낸다는 점이 머신 러닝의 가장 핵심적인 강점
-> 머신러닝은 인공지능 중 약 인공지능(weak AI, 특정 작업에 특화되어 인간 수준(또는 그 이상)을 해낼 수 있는 인공 지능)
-> 지도(supervised)/비지도(unsupervised)/강화(reinforcement) 학습이 대표적인 머신 러닝의 종류 -
딥러닝(Deep Learning): 머신 러닝의 하위 연구 분야로, 많은 양의 데이터를 학습할 수 있는 인공신경망(artificial neural network)에 대한 연구를 지칭
-> 머신러닝에 비해 학습 과정에서 사람의 개입 최소화
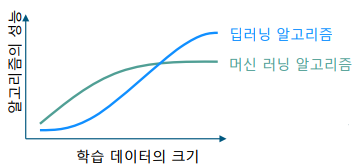
-> 일반적으로 학습 데이터가 적을 때에는 성능이 낮지만, 아주 많은 양의 학습 데이터를 학습했을 때, 성능의 한계치가 머신 러닝에 비해 높음
머신러닝의 세 갈래
-
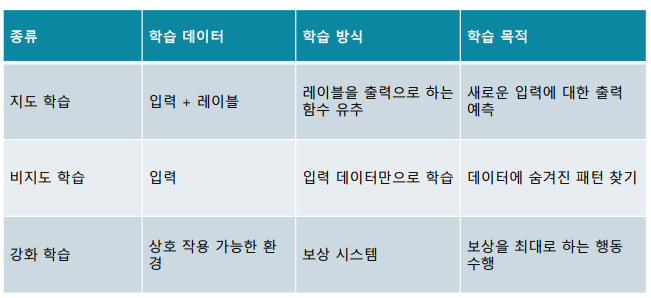
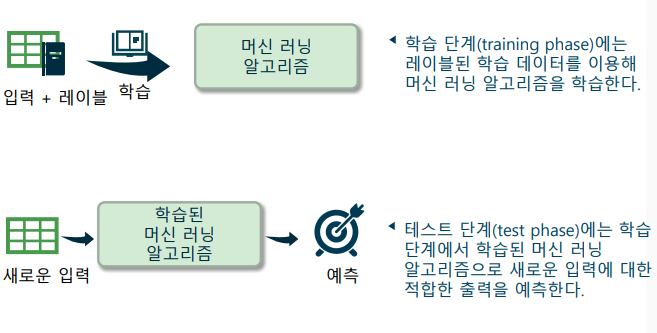
지도 학습(supervised Learning): 입력과 레이블(label)로 이루어진 훈련 데이터로부터 하나의 함수를 학습하는 머신 러닝 방법
-> 레이블: 입력에 대해 기대되는 출력 (= 정답(groundtruth))
-> 훈련 데이터에 정답(레이블)이 주어진다는 의미에서 지도 학습이라고 부름 -
지도 학습의 목적: 레이블되지 않은 새로운 입력에 대해 예측(prediction)을 수행
-
지도 학습의 종류
-> 회귀(regression): 연속적인 값을 출력하는 함수를 학습
-> 분류(classification): 범주형 값을 출력하는 함수를 학습 -
지도 학습의 활용
-
비지도 학습(Unsupervised Learning): 데이터가 어떤 구조로 이루어져 있는지 알아내는 머신 러닝 방법으로 입력에 대한 레이블이 주어지지 않음
-
비지도 학습의 종류
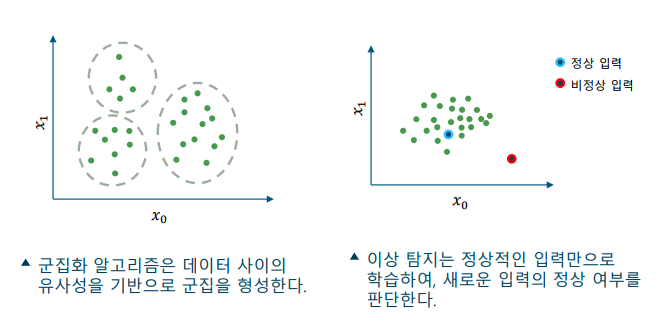
-> 군집화(clustering): 유사한 데이터끼리 군집(cluster)를 형성하는 알고리즘
-> 차원 축소(dimensionality reduction): 고차원의 데이터를 다루기 쉽고 잡음이 적은 저차원 데이터로 변환하는 알고리즘
-> 이상 탐지(anomaly/abnormal/outlier detection): 새로운 입력이 이상치(anomaly, outlier)에 해당하는지 판단하는 알고리즘 -
비지도 학습 예시
-
강화 학습(Reinforcement Learning):상호 작용(interaction)이 가능한 환경에서 에이전트(agent)의 성능을 향상시키는 머신 러닝 방법
-> 에이전트: 강화 학습을 수행하는 과정에서 행동을 수행하는 주체
-> 보상(reward): 강화 학습에서 행동이 얼마나 바람직한 지 측정한 값 -
강화 학습 예시
-> 알파고, 딥블루, 자율주행 인공지능, 로봇제어 등

머신러닝 프로세스
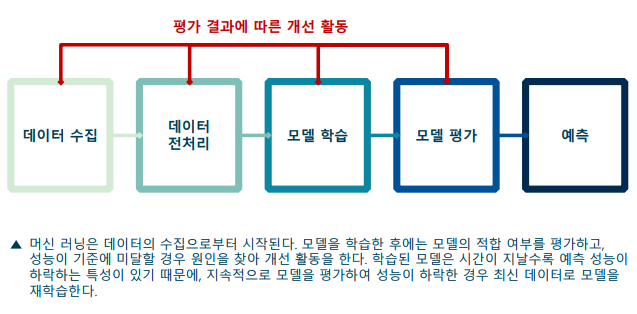
데이터 수집(Data Collection)
-
머신 러닝 알고리즘의 성능에 가장 큰 영향을 주는 단계
-> 데이터의 질이 떨어지면, 알고리즘의 성능도 떨어짐
-> Garbage In, Garbage Out (GIGO) -
데이터의 특성에 따라, 다양한 방법으로 취득
-> 센서 데이터: 데이터 수집(data acquisition; DAQ) 장비 사용
-> 영상 데이터: DSLR, 휴대폰 카메라, 네트워크 카메라 등
-> 의료 영상 데이터: MRI, CT, X-Ray, 열화상 등 의료 장비
-> 설문조사: 직접 설문이나 매체를 통한 조사 등
-> 라이브 서비스에서 수집된 정보: 고객 통계, 중고 거래 매매가 등
-> 수기 입력된 데이터베이스: 학생 성적, 연구 데이터 등 -
데이터 엔지니어링: 대규모 데이터 수집과 처리를 전문으로 하는 분야
데이터 전처리(Data Preprocessing)
-
수집한 원자료(raw data)를 가공하여 머신 러닝에 사용할 수 있게 하는 과정
-> 분석을 방해하는 요소를 억제하는 전처리: 잡음(noise), 이상치(outlier), 오기/오타(typo) 제거, 결측치 처리 등
-> 자료 분석에 용이하도록 자료의 특성을 변환하는 전처리: 특징 추출(feature extraction), 차원 감소(dimensionality reduction), 정규화(normalization), 표준화(standardization) 등 -
특징 공학(feature engineering): 데이터의 전처리를 전문적으로 다루는 분야로, 특징 추출 기법을 깊게 다룸
모델 학습(Model Training)
-
머신 러닝 모델을 학습하여, 원하는 동작을 하도록 하는 과정
-
입력과 출력의 형태와 통계적 특성에 따라 최적의 모델을 선택
-> 공짜 점심 없음 이론(no free lunch theorem): 특정한 문제에 최적화된 알고리즘은 다른 문제에서는 그렇지 않다는 것을 수학적으로 증명 (1997, Wolpert and Macready)
-> ‘만능인 머신 러닝 알고리즘은 없다.’ -
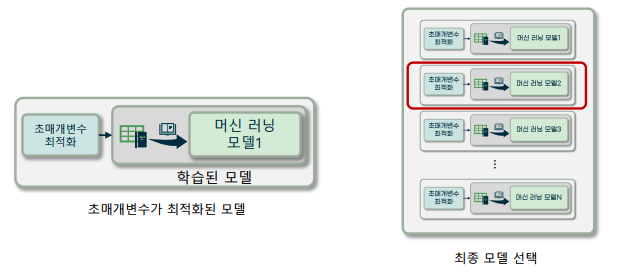
각 모델을 학습하기 위해 초매개변수(hyperparameter) 최적화 과정이 필요
-> 초매개변수: 학습 과정을 제어하기 위한 매개변수로, 모델 학습이 이루어지기 전에 값이 결정되는 매개 변수
-> cf) 학습 매개변수: 모델 학습 과정에서 값이 결정되는 매개변수
모델 평가(Model Evaluation)
- 학습 완료된 모델을 테스트 데이터(test data)에 대해 평가하는 과정
-> 테스트 데이터는 모델 학습 과정에 노출되지 않아야 함
-> 데이터 누수(data leakage): 모델을 학습하는 데에 실제로는 사용할 수 없는 데이터가 포함되는 문제
예측(Prediction)
-
모델을 서비스에 적용하여 새로운 입력에 대해 출력을 예측하는 단계
-
모델을 동결(freeze)하여 학습이 더 이상 이루어지지 않음
-
학습된 모델을 배포(deploy)하여 예측을 위해서만 사용
-> REST API, TF-Serving 라이브러리 등을 이용하여 모델 배포 -
주기적으로 모델을 재학습하여 성능 개선
-> 비정상(non-stationary) 데이터 – 현실의 데이터는 시간이 흐르면서 평균, 분산, 공분산 등이 변화
-> 예측에 대한 사용자의 피드백을 받아 새로운 훈련 데이터 확보
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
