
Chapter 2 확률과 확률변수
모집단과 표본
-
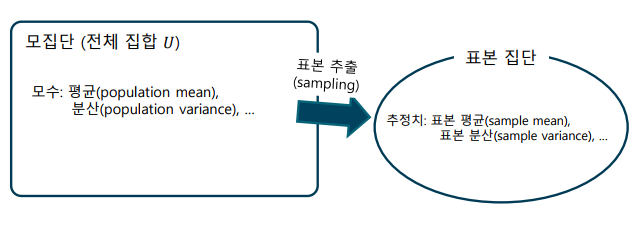
모집단(Population): 통계적인 정보를 얻고자 하는 대상이 되는 전체 집단으로 관심이 있는 전체 집단이므로, 전체 집합으로 표현
-> 모집단은 우리가 실제 분포를 알 수 없으며, 통계 추정의 대상이 됨
-> 모집단 분포를 이미 알고 있다면, 통계 분석이 필요가 없음
-> 모집단의 통계 값들을 모수(parameter)라고 함

-
표본(sample): 모집단에서 표본 추출(sampling)을 통해 얻어낸 부분 집합
-> 표본을 추출하는 과정이 편향(bias)되지 않아야 함
-> 표본의 통계값을 이용해 모수를 추정하는 것이 통계학의 주 목표
자료의 대표값
-
대표값(Representative Value): 자료를 대표하는 값
-> 자료를 대표할 수 있는 하나의 스칼라 값을 의미
-> 벡터의 경우 각 벡터 성분마다 대표값을 계산할 수 있음 -
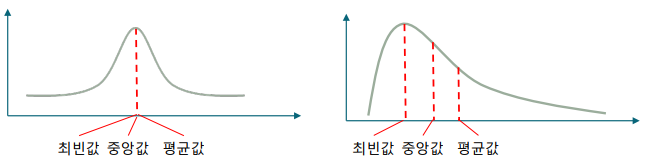
대표값의 예시: 평균, 중앙값, 최빈값, 백분위수, 사분위수, 절사평균 등

-
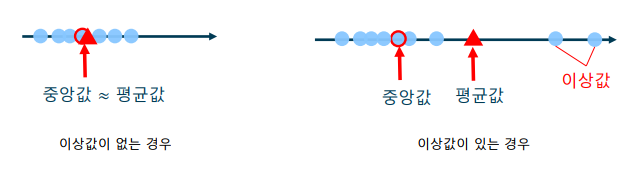
평균 vs 중앙값
-> 평균은 이상값(outlier)에 영향을 크게 받음
-> 중앙값은 평균에 비해서 이상값에 강건(robust)함. 즉, 이상값에 영향을 받지 않음
-> 절사 평균은 평균과 중앙값 사이의 trade-off를 제공
확률 변수와 확률 분포
- 확률변수(Random variables): 확률적으로 값이 달라지는 변수
-> 확률적으로 발생하는 사건에 수치가 부여된 것으로 해석할 수 있음
-> 값이 정해진 경우를 하나의 실험의 시행 결과로 봄 - 확률분포(Probability distribution)
-> 확률 변수의 수치 별 확률을 표현하기 위해 확률 분포를 사용
-> 확률 밀도 함수(probability density function): 확률 변수가 연속된 값(continuous value)를 가질 때 사용
-> 확률 질량 함수(probability mass function): 확률 변수가 이산형(discrete)일 때에 사용
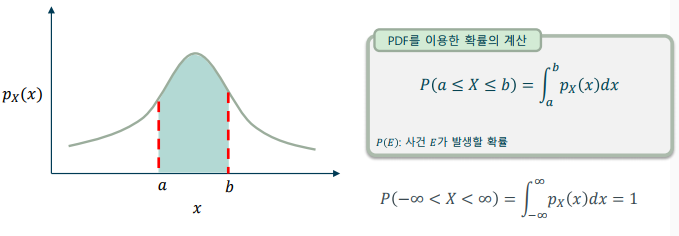
확률 밀도 함수(PDF: Probability Density Function)
- 확률 밀도 함수는 구간을 정적분해서 확률을 계산
-> 정적분(definite integral) – 닫힌 구간에서 함수의 그래프와 좌표축으로 둘러싸인 도형의 넓이를 구하는 수학적 방법
-> PDF는 0 이상의 실수이며, 전 구간에 대해 적분한 결과는 1
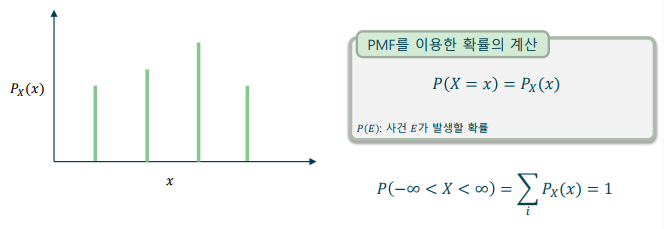
확률 질량 함수(PMF: Probability Mass Function)
- 이산화 된 확률 변수는 각 경우의 수에 확률이 부여
-> 각 사건에 대해 확률이 정의되며, 일정 범위에 대한 확률은 이 확률의 합으로 구함
-> 각 확률은 0 이상의 실수이며, 모든 확률의 합은 항상 1
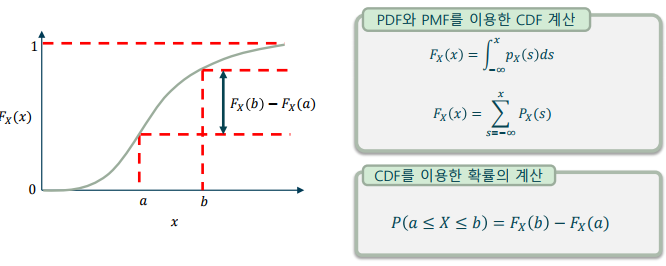
누적 확률 분포(CDF: Cumulative Distribution Function)
- 확률 분포 함수를 누적하여 나타낸 함수
-> PDF의 CDF는 –∞부터 적분하여 계산
-> PMF의 CDF는 첫 확률 값부터 누적 합하여 계산
-> CDF는 증가 함수이며 최소값은 0, 최대값은 1
다양한 확률 분포 함수
-
베르누이 분포(Bernouili distribution): 베르누이 시행을 나타내는 확률 분포
-> 베르누이 시행(Bernoulli trial) - 결과가 두가지 중 하나만 나오는 실험

-
이항 분포(Binomial distribution): N번 시행한 베르누이 시행 중 성공한 횟수를 나타내는 확률 분포
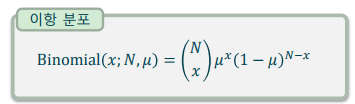
-
균등분포(Uniform distribution): 일정 구간에 대해 동일한 확률 밀도를 가지는 연속 확률 변수
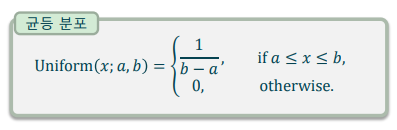
-
이산 균등 분포(Discrete uniform distribution): 일정 범위의 값에 대해 동일한 활률을 가지는 이산 확률 변수
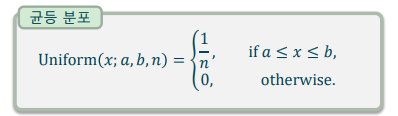
-
정규분포(Normal distribution)
-> 가우시안 분포(Gaussian distribution)라고도 하며, 큰 수의 법칙에 의해 발생하는 자연스러운 연속 확률 분포
-> 평균과 표준편차에 의해 확률 분포의 형태가 결정
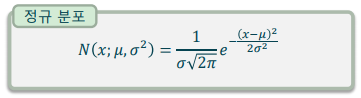
-
표준정규분포(Standard normal distribution): 평균이 0, 표준 편차가 1인 정규 분포

이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
