점화식과 재귀 호출
재귀 호출(Recursive call)
- 함수가 자기 자신을 호출하는 것
- 분할 정복(Divide & Conquer), 점화식 등을 구현하는 데에 많이 사용
- 재귀 구현은 항상 반복(Iteration) 구현으로 변환될 수 있음
점화식(Recurrence relation)
- 재귀식(Recursion relation)이라고도 부르며, 수열의 항 사이의 관계를 나타냄
- 점화식으로 표현된 수열을 n에 대한 식으로 표현하는 것을 ‘풀이한다’ (solve)고 하며, 풀이한 결과를 일반식이라고 함
- 대표적인 점화식의 예
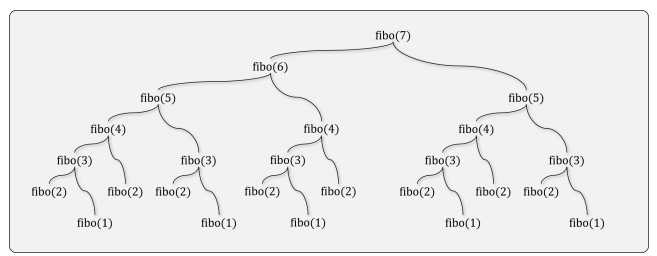
-> 피보나치 수열: 𝑓(𝑛) = 𝑓(𝑛 − 1) + 𝑓(𝑛 − 2)
-> 팩토리얼: 𝑓(𝑛) = 𝑛 × 𝑓(𝑛 − 1)
-> 등차 수열: 𝑓(𝑛) − 𝑓(𝑛 − 1) = 𝑑
-> 등비 수열: 𝑓(𝑛) / 𝑓(𝑛 − 1) = 𝑟
재귀 함수의 구현
- 재귀 호출을 할 때에는 반드시 탈출 조건이 필요: 탈출 조건이 없으면, 재귀 호출은 무한히 계속됨
- 점화식에 의거하여 재귀 호출을 수행: 입력 파라미터를 달리하여 결국 탈출 조건에 도달할 수 있게 함
분할 정복(Divide & Conquer)
- 재귀 호출을 이용하여 큰 문제를 작은 문제로 난어 해결하는 방법: 재귀 호출을 이용해 Top-Down 형식으로 구현귀 호출을 이용하여 큰 문제를 작은 문제로 난어 해결하는 방법: 재귀 호출을 이용해 Top-Down 형식으로 구현
점화식의 반복 구현
재귀 호출의 한계
- 여러 번 재귀 호출이 발생하는 경우, 기하급수적으로 호출 횟수가 증가: 함수 호출 스택(Function call stack)의 크기에 제한이 있어, 일정 횟수 이상 호출이 불가
- 실질적인 계산에 필요한 연산보다, 함수 호출에 의한 Overhead가 발생
반복구현(Iteration)
- 종료조건을 초기값(initial value)으로 함, Bottom-Up으로 구현
Tail Recursion
- 재귀 함수에서, 재귀 호출이 마지막에 단 한번 수행되는 것
- 컴파일러에서 Tail Recursion 최적화를 지원하는 경우, 함수 호출 스택을 재활용함
- 컴파일러에서 최적화를 지원하지 않으면 적용되지 않음(Python은 미지원)
재귀 예시 문제풀이
1) 카탈랑 수는 0번, 1번, 2번, ... 순으로 아래와 같이 구성되는 수열을 의미한다.
1, 1, 2, 5, 14, 42, 132, 429, 1430, 4862, …
이를 점화식으로 나타내면 아래와 같다.
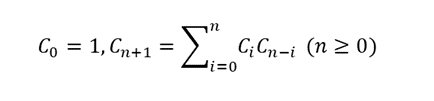
카탈랑 수의 n 번째 값을 구하는 프로그램을 작성하세요.
def solution(n):
if n == 0:
return 1
value = 0
for i in range(n):
value += solution(i) * solution(n-i-1)
return value
if __name__ == '__main__':
N = 7
sol = solution(N)
print(sol)2) 회문 또는 팰린드롬(palindrome)은 앞 뒤 방향으로 같은 순서의 문자로 구성된 문자열을 말한다.
예시) 'abba', 'kayak', 'madam'
유사회문은 문자열 그 자체는 회문이 아니지만 한 문자를 삭제하면 회문이 되는 문자열을 말한다.
예시) 'summuus'의 5번째 또는 6번째 문자 'u'를 제거하면 'summus'인 회문을 만들 수 있다.
주어진 문자열을 확인한 후 문자열 종류에 따라 다음과 같이 출력하는 프로그램을 작성하세요.
회문: 0
유사회문: 1
기타: 2
def solution(s):
def solve(l, r, k):
if l >= r:
return 0
if s[l] == s[r]:
return solve(l+1, r-1, k)
elif k > 0:
if solve(l+1, r, k-1) == 0 or solve(l, r-1, k-1) == 0:
return 1
return 2
return solve(0, len(s)-1, 1)
if __name__ == '__main__':
s = 'abba'
sol = solution(s)
print(sol)
s = 'summuus'
sol = solution(s)
print(sol)
s = 'xabba'
sol = solution(s)
print(sol)
s = 'xabbay'
sol = solution(s)
print(sol)
s = 'comcom'
sol = solution(s)
print(sol)
s = 'comwwmoc'
sol = solution(s)
print(sol)
s = 'comwwtmoc'
sol = solution(s)
print(sol)3) 하노이의 탑

하노이의 탑 퍼즐 게임 규칙은 다음과 같다.
- 한 번에 한 개의 원판 만 옮길 수 있다.
- 큰 원판이 작은 원판 위에 있어서는 안된다.
원판의 개수 n 이 주어졌을 때, 가장 왼쪽 기둥으로부터 끝 기둥으로 이동하는 과정을 출력하는 프로그램을 구현하세요.
단, 초기에 모든 원판은 가장 큰 원판부터 순서대로 왼쪽 기둥에 위치해 있다.
def solution(n):
def solve(n, start, end, temp):
if n == 1:
return [[start, end]]
return solve(n-1, start, temp, end) + [[start, end]] + solve(n-1, temp, end, start)
return solve(n, 1, 3, 2)
if __name__ == '__main__':
n = 3
sol = solution(n)
print(sol)정렬 알고리즘
정렬(Sorting)
- 특정 값을 기준으로 데이터를 순서대로 배치하는 방법
- 정렬 알고리즘의 조건
-> 정렬 알고리즘의 출력은 입력을 재배열하여 만든 순열
-> 정렬 알고리즘의 출력에서 이전 원소는 다음 원소보다 작지 않음(오름차순)
정렬 알고리즘을 배우는 이유
- 다양한 방식으로 구현이 가능해, 알고리즘 핵심 개념 학습에 용이
-> 점근표기법(Asymptotic notation)
-> 분할 정복 알고리즘(Divide & Conquer)
-> 최악의 경우, 최선의 경우, 평균적인 경우
정렬 알고리즘의 주요 구분
- 제자리 알고리즘(In-place algorithm): 알고리즘 수행에 메모리가 𝑂(log 𝑁) 이하로 사용되는 알고리즘
- 안정 알고리즘(Stable algorithm): 정렬 기준이 동일한 값이 정렬 전후에 순서가 유지되는 알고리즘
다양한 정렬 알고리즘
- 구현 난이도는 쉽지만, 속도는 느린 알고리즘: 버블 정렬, 삽입 정렬, 선택 정렬
- 구현 난이도는 조금 어렵지만, 속도는 빠른 알고리즘: 합병 정렬, 힙 정렬, 퀵 정렬, 트리 정렬
- 하이브리도 정렬: 팀소트, 블록 병합 정렬, 인트로 정렬
- 기타 정렬 알고리즘: 기수 정렬, 카운팅 정렬, 셀 정렬, 보고 정렬
기초 정렬 알고리즘
버블 정렬(Bubble sort)
- 인접한 두 원소를 검사하여 자리를 교체하는 단순한 정렬 알고리즘
- 공간 복잡도:
- 시간 복잡도
-> 최악의 경우:
-> 최선의 경우:
-> 평균적인 경우:
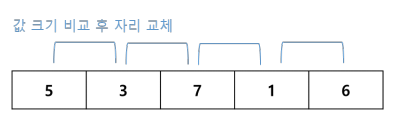
버블 정렬 과정
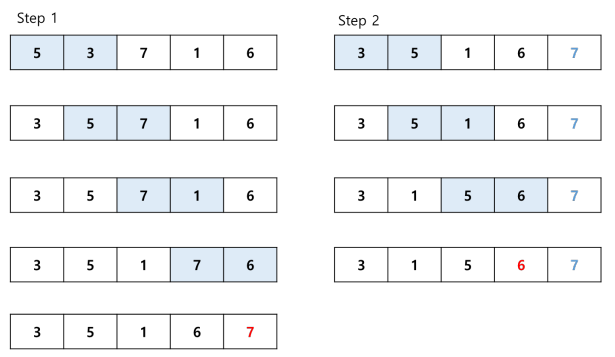
삽입 정렬(Insertion sort)
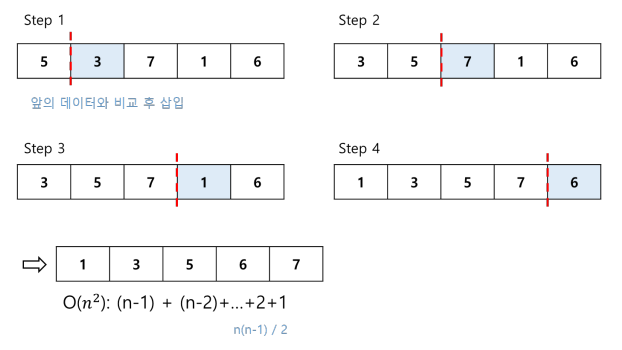
- 앞의 데이터를 정렬 해가면서 뒤쪽의 데이터를 적절한 위치에 삽입
- 공간 복잡도:
- 시간 복잡도
-> 최악의 경우:
-> 최선의 경우: 이미 정렬이 된 경우
-> 평균적인 경우:
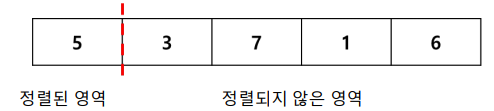
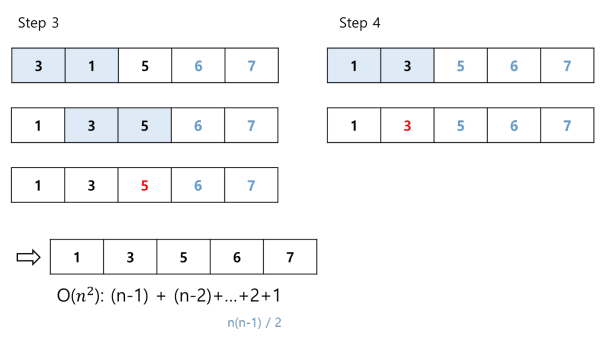
삽입 정렬 과정
선택 정렬(Selection sort)
- 최소값을 찾아서 맨 앞으로 정렬하는 방식
- 공간 복잡도:
- 시간 복잡도
-> 최악의 경우:
-> 최선의 경우: 매번 최소값을 찾아야 하므로 항상 일정하게 동작
-> 평균적인 경우:
선택 정렬 과정
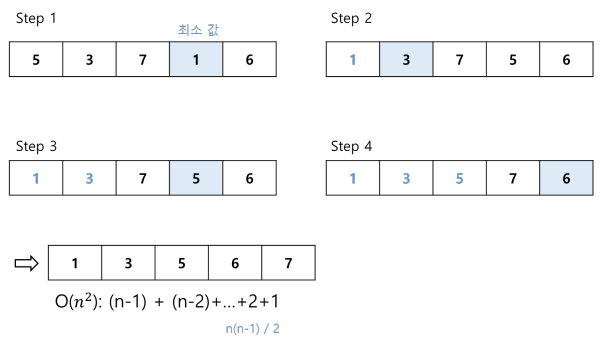
합병 정렬(Merge sort)
- q배열의 길이가 1이 될때까지 이분할 하고, 인접한 배열끼리 합병하면서 정렬하는 알고리즘
- 공간 복잡도:
- 시간 복잡도
-> 최악의 경우:
-> 최선의 경우:
-> 평균적인 경우:
합병 정렬 과정
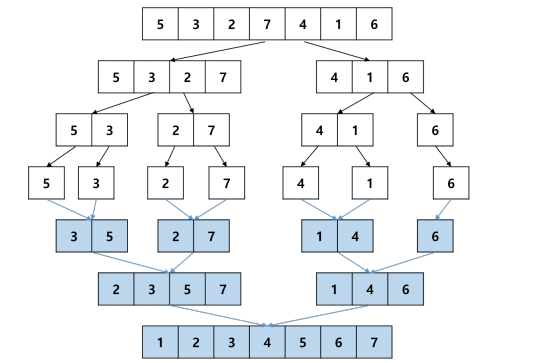
퀵 정렬(Quick sort)
- 임의의 값(pivot)을 정해, 그 값을 기준으로 좌우로 나누어 정렬하는 알고리즘. Pivot의 선택에 의해 알고리즘 성능이 크게 달라질 수 있음
- 공간 복잡도:
- 시간 복잡도
-> 최악의 경우:
-> 최선의 경우:
-> 평균적인 경우:
퀵 정렬 과정
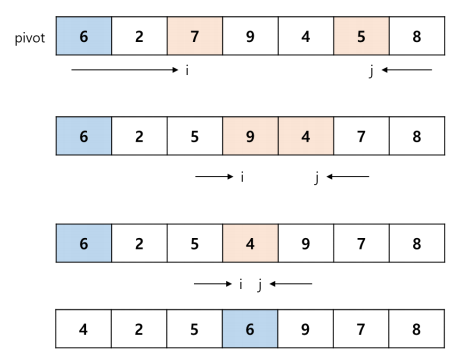
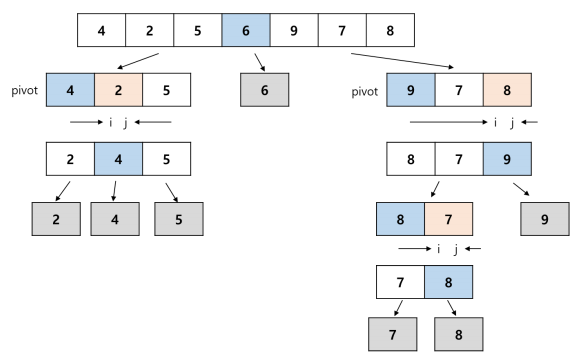
정렬 예시 문제 풀이
1) 당신은 학교에서 선생님으로 일하고 있다. 어느날 학생의 성적를 관리하는 프로그램을 제작해 달라는 의뢰를 받았다.
총 N명의 학생의 성적을 관리하고자 한다. 이 때 i번째 학생(0 <= i < N)의 학년이 grade[i], 반이 class_name[i], 점수가 score[i]에 기록되어 있다.
이 때, 학생의 점수를 아래와 같은 조건에 맞게 정렬하여 출력하시오.
- 정렬의 우선순위는 '학년이 낮을 수록 앞에', '반 숫자가 낮을 수록 앞에', '점수가 높을 수록 앞에' 순으로 정렬한다.
- 매개변수 형식
grade = [3, 2, 1, 2, 1, 3, 2]
class_name = [1, 3, 2, 3, 1, 3, 3]
score = [50, 40, 66, 80, 100, 42, 99] - 반환값 형식
[100, 66, 99, 80, 40, 50, 42]
def solution(grade, class_name, score):
items = [(g, c, -s, s) for g, c, s in zip(grade, class_name, score)]
items.sort()
return list(map(lambda x: x[-1], items))
if __name__ == '__main__':
grade = [3, 2, 1, 2, 1, 3, 2]
class_name = [1, 3, 2, 3, 1, 3, 3]
score = [50, 40, 66, 80, 100, 42, 99]
sol = solution(grade, class_name, score)
print(sol)2) 문자열 s가 있을 때, 이 문자열을 재배치하여 만든 문자열을 '애너그램'이라고 한다.
예를 들어, "fine"은 "infe"의 애너그램이라고 할 수 있다.
s가 영문 소문자로만 이루어져 있다고 할 때, 문자열 t가 문자열 s의 애너그램인지 판단하는 프로그램을 작성하시오.
- 매개변수 형식
s = "imfinethankyou"
t = "atfhinemnoyuki" - 반환값 형식
True
def solution(s, t):
if len(s) != len(t):
return False
s_sorted_list = sorted(list(s))
t_sorted_list = sorted(list(t))
for s_, t_ in zip(s_sorted_list, t_sorted_list):
if s_ != t_:
return False
return True
if __name__ == '__main__':
s = "imfinethankyou"
t = "atfhinemnoyuki"
sol = solution(s, t)
print(sol)3) 당신은 천재적인 두뇌를 가진 개발자끼리 겨루는 '제로 지니어스' 프로그램에 참가하게 되었다.
'제로 지니어스' 프로그램에서는 주어진 숫자를 이어붙여 가장 큰 수를 만드는 프로그램을 작성하는 미션이 주어졌다.
문제의 조건은 아래와 같다.
0또는 양의 정수가numbers배열로 주어진다.numbers배열에 주어진 정수를 이어붙여 만들 수 있는 가장 큰 수를 출력한다.
예를 들어, 주어진 정수가[6, 10, 2]라면[6102, 6210, 1062, 1026, 2610, 2106]를 만들 수 있고, 이중 가장 큰 수는6210이다.
위 미션을 수행하여 프로그램을 작성하시오. 단, 출력 정수 값이 너무 클 것을 대비하여 문자열로 출력하시오.- 매개변수 형식
numbers = [3, 30, 34, 5, 9] - 반환값 형식
"9534330"
from functools import cmp_to_key
def solution(numbers):
def compare(x, y):
a = int(str(x) + str(y))
b = int(str(y) + str(x))
return 1 if b > a else -1
key = cmp_to_key(compare)
numbers.sort(key=key)
return ''.join(map(str, numbers))
if __name__ == '__main__':
numbers = [3, 30, 34, 5, 9]
sol = solution(numbers)
print(sol)이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
