스택(Stack)
스택 이론
- 리스트와 달리 기능을 제한하는 추상자료형
- 후입선출 (Last In First Out: LIFO)의 특성
- 자료가 입력된 역순으로 처리되어야 할 때 사용 ex) 함수 콜 스택, 인터럽트 처리, 수식 계산 등
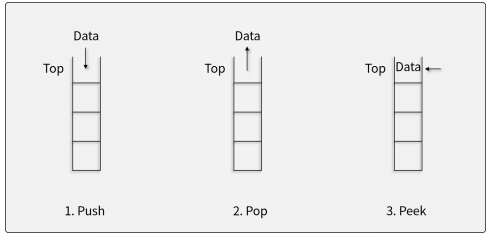
스택의 연산자
- 자료를 top 위에 삽입하는 연산자 (push())
- 자료를 top에서 꺼내는 연산자 (pop())
- top에 있는 자료를 반환하지만, 삭제하지는 않는 연산자 (peek())
- 스택이 비어있는지 확인하는 연산자 (is_empty())
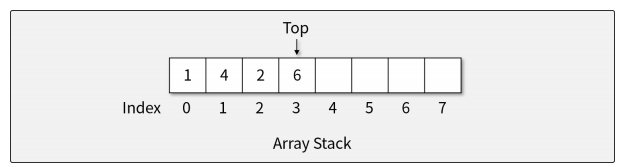
스택의 구현
- 배열을 사용하므로, 크기가 정해져 있음
- 메모리상 자료가 연속적이기 때문에 동작 속도가 빠름
오버플로우와 언더플로우
- 스택은 고속 동작을 위해 보통 배열로 수형
- 스택이 가득 차 있을 때 push()하면 오버플로우 발생: 메모리 공간의 부족으로 발생
- 스택이 비어있을 때 pop()하면 언더플로우 발생: 프로그램의 버그로 발생
스택의 활용
# Python에서 stack 사용하기 (리스트 응용)
stack = []
print(len(stack) == 0) # is_empty()는 len(stack) == 0 으로 판단
for i in range(1, 11):
stack.append(i) # push()를 구한하고 있는 append
print(stack)
print(len(stack) == 0) # is_empty()는 len(stack) == 0 으로 판단
print(stack[-1]) # peek()는 [-1]로 구현
for i in range(1, 11):
val = stack.pop() # pop()
print(val, end=' ')
print()
print(len(stack) == 0) # is_empty()는 len(stack) == 0 으로 판단1) 스택을 이용하여 문제열 s를 뒤집기
def solution(s):
res = ""
stack = []
for c in s:
stack.append(c)
while stack:
res += stack.pop()
return res
if __name__ == '__main__':
s = "zerobase"
sol = solution(s)
print(sol)2) 괄호 짝이 잘 맞는지 검사하기, 입력받은 문자열 s의 괄호가 올바른 짝이면 True, 아니면 False
def solution(s):
stack = []
for c in s:
if c == "(":
stack.append(c)
elif c == ")":
if stack:
stack.pop()
else:
return False
if stack:
return False
else:
return True
if __name__ == '__main__':
s = "(()(()))()"
sol = solution(s)
print(sol)3) 후위표기법으로 표기된 계산식 s 연산하기
# 후위표기법: 피연산자가 2개 나온 후에 연산자가 나오는 표기법
# ex) "4 2 +" -> 4 + 2 = 6
# 입출력 예시)
# s = "2 4 +"
# 결과: 6
#
# s = "2 2 -"
# 결과: 0
#
# s = "1 3 + 5 * 2 * 5 +"
# 결과: 45def solution(s):
stack = []
for c in s.split(' '):
if c.isdigit():
stack.append(int(c))
else:
val2 = stack.pop()
val1 = stack.pop()
if c == '+':
stack.append(val1 + val2)
elif c == '-':
stack.append(val1 - val2)
elif c == '*':
stack.append(val1 * val2)
elif c == '/':
stack.append(val1 / val2)
val = stack.pop()
return val
if __name__ == '__main__':
s = "1 3 + 5 * 2 * 5 +"
sol = solution(s)
print(sol)큐(Queue)
큐 이론
- 스택과 유사하게 기능을 제한하는 추상자료형
- 선입선출 (First In First Out; FIFO)의 특성
- 자료가 입력된 순서대로 처리되어야 할 때 사용 ex) 네트워크 트래픽, 프린터 버퍼 등
큐의 연산자
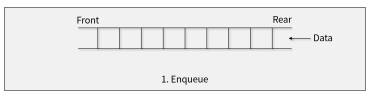
-
자료를 rear로 삽입하는 연산자 (put(), enqueue())
-
자료를 front에서 꺼내는 연산자 (get(), dequeue())
-
front에 있는 자료를 반환하지만, 삭제하지는 않는 연산자 (peek())
큐의 구현
-
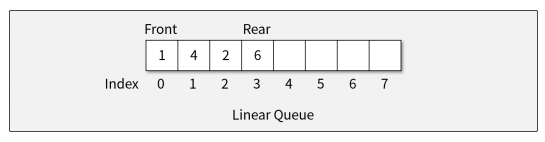
선형 큐(Linear queue)
-> 배열을 이용하여 구현하는 가장 기본적인 큐
-> 한번 사용한 메모리 공간이 버려지는 문제
-> 반드시 오버플로우가 발생하는 구조적인 문제가 있음
-
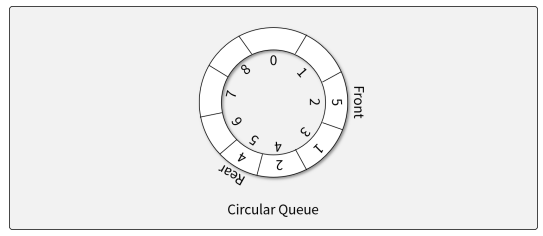
환형 큐(Circular queue)
-> 선형 큐의 시작과 끝을 연결하여 메모리를 재활용하는 구조
-> 배열을 가득 채우기 전까지는 오버플로우가 발생하지 않음
-
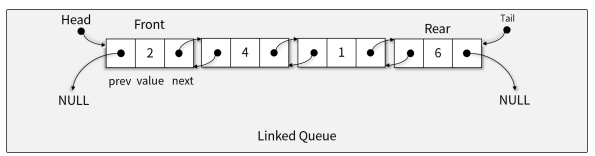
연결 리스트 큐(Linked queue)
-> 연결 리스트를 이용해 큐 구현
-> 구조적으로 메모리 제약이 없기 때문에 많이 사용
큐의 활용
# Python에서 큐 사용하기 (리스트 응용)
queue = []
for i in range(1, 11):
queue.append(i) # put()은 append()를 이용
print(queue)
print(queue[0]) # peek()는 [0]를 이용
for i in range(1, 11):
val = queue.pop(0) # get()은 pop(0)을 이용
print(val, end=' ')
print()
# Python 에서 큐 사용하기 (queue 패키지 사용)
from queue import Queue
queue = Queue()
for i in range(1, 11):
queue.put(i)
# print(queue.peek()) # peek()는 미구현
for i in range(1, 11):
val = queue.get()
print(val, end=' ')
print()1) 카드 섞기 문제 1부터 N 까지의 번호로 구성된 N장의 카드가 있다. 1번 카드가 가장 위에 그리고 N번 카드는 가장 아래의 상태로 카드가 순서대로 쌓여있다. 아래의 동작을 카드 한 장만 남을 때까지 반복했을 때, 가장 마지막 남는 카드 번호를 출력하시오.
1. 가장 위의 카드는 버린다.
2. 그 다음 위의 카드는 쌓여 있는 카드의 가장 아래에 다시 넣는다.
def solution(N):
queue = list(range(1, N+1))
while len(queue) > 1:
queue.pop(0)
queue.append(queue.pop(0))
return queue[0]
if __name__ == '__main__':
N = 7
sol = solution(N)
print(sol)2) 요세푸스 문제 N과 K가 주어졌을 때 (N, K) 요세푸스 순열을 구하시오. N과 K는 N >= K 를 만족하는 양의 정수이다. 1부터 N 번까지 N명이 순서대로 원을 이루어 모여 있다. 이 모임에서 원을 따라 순서대로 K번째 사람을 제외한다. 모든 사람이 제외될 때까지 반복하며 이 때, 제외되는 순서가 요세푸스 순열이다.
def solution(N, K):
queue = list(range(1, N+1))
result = [0 for _ in range(N)]
ind = 0
while queue:
for _ in range(K-1):
queue.append(queue.pop(0))
result[ind] = queue.pop(0)
ind += 1
return result
if __name__ == '__main__':
N = 5
K = 2
sol = solution(N, K)
print(sol)해싱(Hashing)
해싱 이론
- 넓은 범위의 값을 더 좁은 범위의 값으로 변환하는 기법
- 동일한 입력에 대해서 항상 동일한 출력을 보장
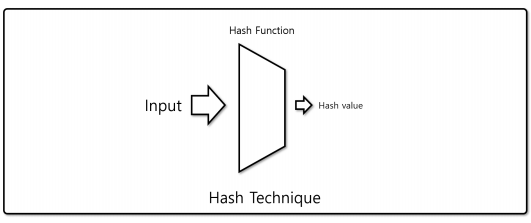
해시 함수(Hash function)
- 해싱에 사용되는 함수로, 자주 사용되므로 빠른 동작이 요구됨
- 다른 입력이 동일한 출력을 가질 수 있으며, 이것을 해시 충돌 (Hash collision)이라 함
- 파이썬에서는 hash() 함수가 내장 함수로 구현되어 있음
해시 셋(Hash set)
- 해싱 기법을 이용하는 대표적인 자료구조
- 한정된 크기를 가지는 버킷(bucket)을 이용해 자료를 저장
- 자료를 저장하는 인덱스는 해시 함수의 출력인 해시 값을 버킷의 크기로 나눈 나머지로 함 (index = hash_value % bucket_size)
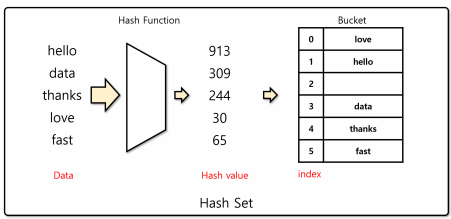
해시 셋의 특징
- 파이썬에서는 set 자료형으로 해시 셋이 구현되어 있음
- 자료의 중복을 허용하지 않으며, 빠르게 자료를 탐색할 수 있음
- 버킷이 가득 차면 버킷의 크기를 증가시켜 재배치 함
해시 테이블(Hash table)
- 해시 셋과 유사하나, 해시를 계산하는 key와 짝을 이루는 value를 함께 버킷에 저장하는 자료구조
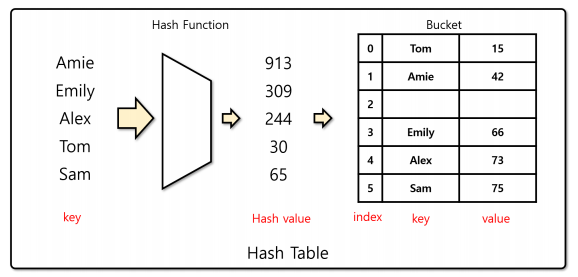
해시 테이블의 특징
- 파이썬에서는 dict 자료형으로 해시 테이블이 구현되어 있음
- Key는 중복이 허용되지 않으나, value는 중복이 허용
- 공간 복잡도를 희생하여 시간 복잡도를 낮추는 대표적인 자료구조
해시 충돌(Hash collision)
- 해시 함수가 서로 다른 입력에 대해 동일한 출력을 내는 경우
- 해시 충돌이 100% 발생할 경우, 탐색 성능은 𝑂(1)에서 𝑂(𝑁)으로 감소
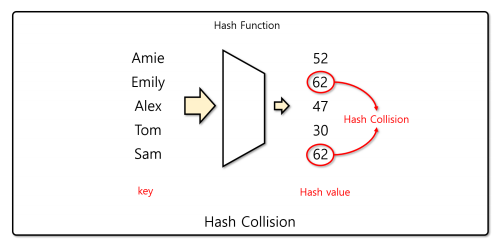
해시 충돌의 해결
-
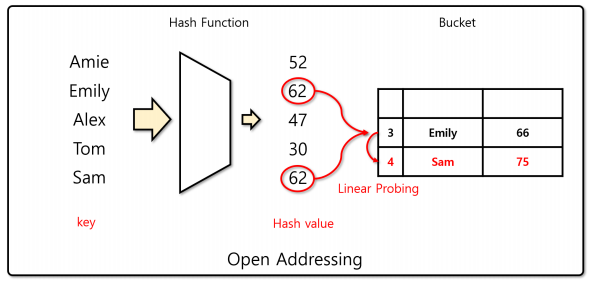
개방 주소법(Open addressing)
-> 버킷의 다른 index를 선택하여 자료를 저장하는 기법
-> 개방 주소법은 더 이상 해시 충돌이 발생하지 않을 때 까지 반복 -
개방 주소법의 종류
-> 선형 탐사 (Linear probing): index를 1씩 이동시키는 방법
-> 이차 탐사 (Quadratic probing): index를 , , , … 씩 이동
-> 이중 해싱 (Double hashing): 별도의 해시 함수로 이동 간격을 계산
선형 탐사(Linear probing)
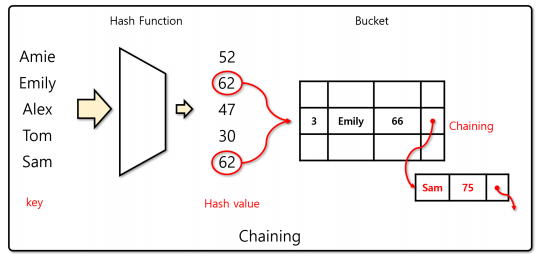
체이닝(Chaining)
- 해시 충돌이 발생할 경우 버킷에 자료를 연결 리스트로 추가해나가는 기법
해시 활용
1) 리스트의 중복을 제거하고 출력하시오, 다느 출력 리스트이 순서는 오름차순으로 정렬하시오.
def solution(arr):
return sorted(list(set(arr)))
if __name__ == '__main__':
arr = ["hello", "zero", "base", "buy", "zero", "hello"]
sol = solution(arr)
print(sol)2) 정수로 이루어진 리스트 arr에서, 총 합이 0이 되는 부분 리스트가 있는지 여부를 출력하시오. 부분 리스트란, 리스트의 일부 연속된 부분을 잘라 만든 리스트를 말한다.
def solution(arr):
s = set()
s.add(0)
total = 0
for elem in arr:
total += elem
# 장점1. total이 자주 중복되면 중복없이 하나로 해결된다.
# 장점2. total in s 라는 탐색 연산이 O(1)로 동작
if total in s:
return True
s.add(total)
return False
if __name__ == '__main__':
arr = [3, 4, -7, 3, 1, 3, 1, -4, -2, -2]
sol = solution(arr)
print(sol)3) 철수와 영희는 눈을 가리고 잡기 놀이를 하기로 했다. 철수는 도망치는 역할을 맡았으며, (x1, y1) 좌표에서 출발한다. 매 1초마다 철수는 동/서/남/북 중 한군데를 임의로 선택하여 이동한다. 영희는 철수를 잡는 역할을 맡았으며, (x2, y2) 좌표에서 출발한다. 매 1초마다 영희는 북서/북동/남서/남동 중 한군데를 임의로 선택하여 이동한다. 모든 경우 중에서, 영희가 철수를 가장 빨리 잡는 경우 몇 초의 시간이 걸리는지 출력하시오.
# 입력설명
# -1000 <= x1 <= 1000
# -1000 <= y1 <= 1000
# -1000 <= x2 <= 1000
# -1000 <= y2 <= 1000
#
# 입출력 예시
# x1 = 2
# y1 = 4
# x2 = 5
# y2 = -3
# 출력: 4def solution(x1, y1, x2, y2):
set_a = {(x1, y1)}
set_b = {(x2, y2)}
a_history = set()
b_history = set()
a_history.update(set_a)
b_history.update(set_b)
move_a = [(1, 0), (-1, 0), (0, 1), (0, -1)]
move_b = [(1, 1), (-1, 1), (1, -1), (-1, -1)]
t = 0
while True:
t += 1
next_set_a = set()
next_set_b = set()
for x, y in set_a:
for dx, dy in move_a:
pos = (x + dx, y + dy)
if pos in a_history:
continue
next_set_a.add((x + dx, y + dy))
for x, y in set_b:
for dx, dy in move_b:
pos = (x + dx, y + dy)
if pos in next_set_a:
return t
if pos in b_history:
continue
next_set_b.add((x + dx, y + dy))
set_a = next_set_a
set_b = next_set_b
a_history.update(set_a)
b_history.update(set_b)
if __name__ == '__main__':
x1 = 2
y1 = 4
x2 = 5
y2 = -3
sol = solution(x1, y1, x2, y2)
print(sol)이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
