학습 데이터 전처리란?
학습 데이터 전처리란 무엇을 의미하는걸까요? 인공지능을 학습시키기 위해서는 인공지능이 이해할 수 있는 형태로 데이터를 가공해야합니다. 조금이라도 규격에 맞지 않으면 인공지능의 정확도가 떨어질 수 있으므로 세심한 주의가 필요한 과정이지요.
따라서 학습 데이터 전처리란 인공지능 모델을 학습 하기전 데이터셋이 적절한 형태로 가공되었는지 체크해주는 일련의 정제과정을 의미합니다. 대개 특정 기능을 수행하는 파이프라인을 만들어 전처리 프로세스를 수행하지요.
마크애니에서는 어떠한 데이터셋 전처리 과정을 거치는지 살펴볼까요?
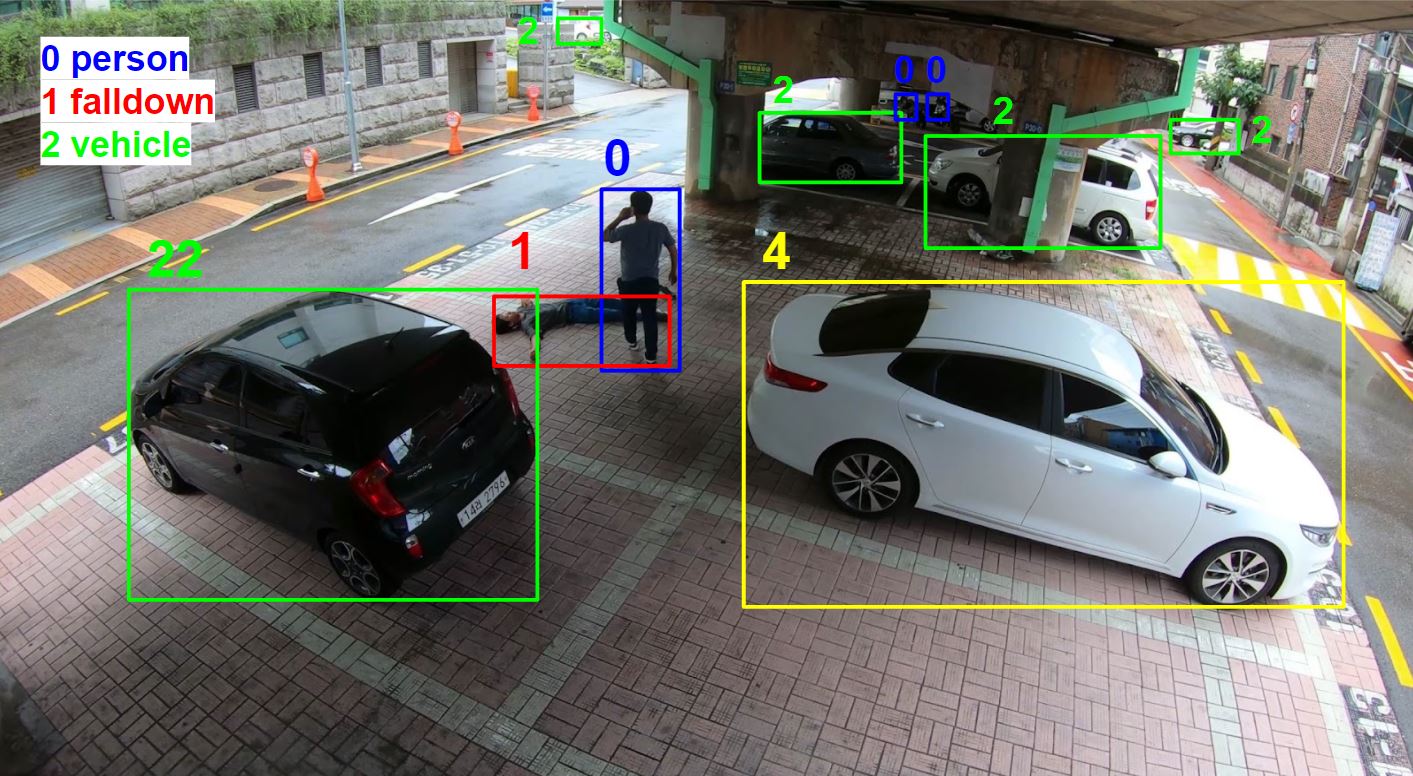
다음 중 잘못된 곳은?
다음은 사람, 쓰러짐, 차량 정보가 바운딩 박스 형태로 라벨링된 이미지입니다. 데이터에서 '잘못되었다'는 것은 해당 데이터를 사용하였을 때 인공지능이 제대로 학습되지 않는 데이터를 의미합니다.

해당 이미지에서는 어떤 부분이 잘못되었을까요? 전처리 파이프라인을 하나씩 보시며 설명해드리도록 하겠습니다. 학습 데이터셋은 다음과 같은 8가지 전처리 과정을 거치게 됩니다.
Step 1. masking small box
Step 2. image masking
Step 3. removing masking label
Step 4. check out of lable number
Step 5. check base label
Step 6. remove overlap box
Step 7. check pair files (img&txt)
Step 8. count label box
우선 첫 번째 과정은 크기가 너무 작아 오히려 학습에 방해가 되는 객체를 제거하는 과정입니다. 이미지 내의 객체 정보를 읽어와 일정 width 이하인 객체는 예비 마스킹 처리합니다. 이때 바로 해당 픽셀을 날려버리기 보다는, 마스킹 레이블을 따로 설정하고 해당 번호로 class index를 변경하는 방식을 추천드립니다. 데이터가 복구될 수 없게 망가지는것을 방지하기 위해서이지요.
두 번쨰 과정은 마스킹 인덱스를 가진 객체의 내부를 마스킹하는 과정입니다. 여러가지 마스킹 방법이 있지만, 가장 보편적인 방법은 해당 영역의 픽셀을 0으로 날리는 방법입니다. 해당 과정은 이미지의 픽셀을 날리는 것이기 때문에 객체의 박스 정보는 그대로 남아 있게 됩니다.
따라서 세 번째 과정은 마스킹된 객체의 박스 정보를 삭제하는 과정입니다. 마스킹에 해당하는 영역 정보가 필요한 경우 해당 프로세스를 생략할수도 있겠지요?
이렇게 세 단계를 거친 이미지는 다음과 같이 변하게 됩니다.

학습에 방해를 줄만큼 작은 객체들이 마스킹되어있는 모습을 확인하실 수 있습니다.
네 번째 과정은 범위를 벗어난 라벨이 있는지 체크하는 과정입니다. 해당 이미지의 클래스는 3가지입니다. 따라서 3을 넘는 클래스 인덱스는 오류가 되겠지요. 해당 과정에서는 모든 객체 박스의 인덱스를 읽어 범위를 벗어나는 라벨을 가진 이미지의 목록을 출력해줍니다. 함부로 삭제하거나 마스킹했을 경우 학습의 성능에 영향을 줄 수 있기 때문에, 에러가 있는 데이터의 목록을 출력하여 수정하는 것이 바람직합니다.
다섯 번쨰 과정은 빠진 라벨을 추가하는 과정입니다. 한 라벨의 범위가 다른 라벨이 포함되는 경우가 있을 수 있는데요, 이를 멀티라벨이라고 부르곤 합니다. 예를들어 과일, 사과, 포도라는 라벨이 있다면 사과와 포도는 과일에 포함되므로, 과일의 멀티라벨이 되겠지요. 해당 이미지에서는 쓰러짐이 사람의 멀티라벨로 작용됩니다. 따라서 쓰러짐 클래스를 가진 객체는 반드시 사람 라벨 또한 가지고 있어야합니다.
해당 단계에서는 멀티 라벨이 이런 베이스 라벨을 가지고 있는지를 체크하고, 만약 베이스 라벨이 존재 하지 않는다면 자동으로 추가를 해줍니다.
여섯 번째 과정은 중복된 박스 정보를 삭제해주는 과정입니다. 간혹 같은 정보를 이중, 삼중으로 라벨링 해버리는 경우가 생기는데요, 이를 제거하지 않고 학습에 들어간다면 객체가 중복으로 학습이 되어 인공지능의 성능이 떨어질 수 있습니다. 따라서 중복된 어노테이션 정보는 삭제해주는 것이 바람직합니다.

여섯 단계를 거친 데이터의 모습입니다. 4로 잘못 라벨링 되어있었던 차량이 2로 수정되고, 쓰러짐으로만 라벨링 되어있던 객체에 사람 라벨이 추가된 모습을 보실 수 있습니다.

일곱 번째 단계는 원본 데이터와 어노테이션 데이터의 수가 일치하는지 확인하는 단계입니다. 방대한 양의 데이터를 작업하다보면 간혹 원본 데이터나 어노테이션 데이터가 소실되어 짝이 맞지 않는 경우가 있습니다. 이 단계는 각 데이터의 수를 세고 짝이 없는 데이터의 목록을 출력해줍니다. 이미지만 있는 경우 어노테이션 데이터를 새로 생성하고, 어노테이션 데이터만 있는 경우 해당 파일명과 일치하는 이미지를 찾아내거나 어노테이션 데이터를 삭제합니다.

마지막, 여덟 번쨰 단계는 데이터셋의 클래스 별 객체 수와 비율을 표시하는 단계입니다. 전처리를 거친 데이터셋이 어떻게 구성되어 있는지 통계적으로 파악할 수 있습니다. 각 클래스의 비율을 파악한다면 어떤 데이터를 보충하여야 되는지 알 수 있겠지요. 또한 총 이미지 수와 어노데이션 정보가 없는 이미지 수를 한 번에 볼 수도 있어 네거티브 데이터가 데이터셋에서 얼마나 많은 비중을 차지하는지도 알 수 있습니다.
이야기를 마치며...
오늘은 이렇게 학습 데이터셋의 전처리 과정에 대해 알아보았는데 재밌게 보셨나요? 예시로 든 데이터셋은 가장 기본적인 바운딩 박스 어노테이션을 갖는 데이터셋이었지만, 새그먼테이션, 키포인트, 뎁스 등 다양한 라벨링 방법에 따라 파이프라인의 구성요소가 조금씩 바뀔 수 있습니다. 데이터셋의 포맷이 txt인지 json인지에 따라 데이터에 접근법 또한 달라질 수 있고, 데이터셋의 사이트에 따라 전처리 과정이 추가되거나 빠질 수도 있답니다.
데이터셋 전처리 과정은 인공지능을 학습시킬 때에 빠져서는 안될 중요한 과정입니다. 이러한 과정을 일련의 파이프라인으로 만들어 순차적으로 통과시키고, 모든 단계가 통과되었을 때 학습을 돌리는 것이 학습에서의 에러를 방지하는 가장 좋은 방법일 것입니다.
그럼 이상으로 오늘의 포스팅을 마치겠습니다. 다음 시간에는 또 다른 유익한 포스팅으로 찾아뵙겠습니다!

감사합니다, 공부에 사용하겠습니다!