
Intro
최근 LLM에 대해 공부하고 프로젝트를 통해 LangChain, LangGraph를 활용한 LLM 어플리케이션 개발을 수행해보았습니다.
프로젝트를 수행하면서 LangChain이라는 프레임워크 생태계를 더 깊게 이해하고 활용하고 싶다는 생각이 커져서, 이번 포스트를 기점으로 LangChain에 대해 복습하고 추가로 학습하며 정리해보려고 합니다.
이 시리즈를 통해 LangChain의 기본 문법부터 고급 문법까지 학습해보며 정리하고, 다른 시리즈를 통해 RAG를 더욱 심도있게 학습해볼 계획입니다.
힘차게 시작해보겠습니다!
1. LangChain 이란?
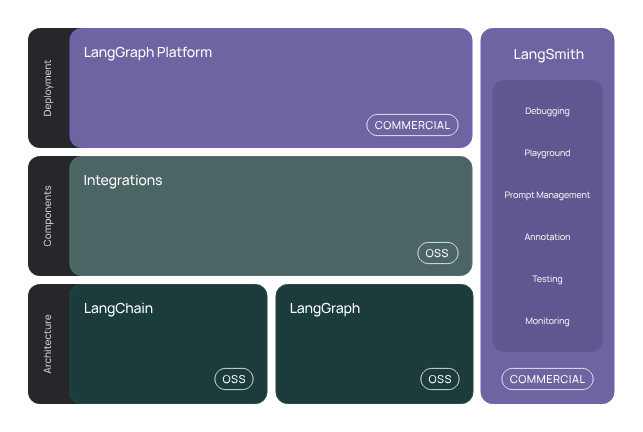
LangChain은 대규모 언어 모델(LLM)을 사용하여 애플리케이션을 개발하기 위한 프레임워크입니다. 너무나도 똑똑한 LLM을 활용해 어떤 서비스, 가령 보험 관련 고객응대 챗봇과 같은 특정 어플리케이션을 구현하고 싶을 때 사용할 수 있습니다. 즉, LLM을 나의 어플리케이션에 쉽게 엮을 수 있는 프레임워크 인 것이죠.
LangChain은 LLM 어플리케이션을 개발할 때 필요한 많은 기능을 자동화하여 제공하고 있습니다.
-
LLM 응답 처리와 같이 본래 Python으로 직접 구현했다면 굉장히 복잡했을 작업들도 LangChain은 코드 몇 줄로 해결할 수 있게 구현해두었습니다.
-
LLM 어플리케이션을 구현할 때는 LLM의 입출력과 API 처리 등 각 단계를 하나하나 검증하며 진행하는 것이 중요합니다. 어플리케이션을 개발하는 입장에서는 답변 성능이 좋다면 왜 좋은지, 안좋다면 왜 안좋은 지 검증할 필요가 있기 때문입니다. LangChain에서는 이러한 과정을 LangSmith라는 같은 생태계의 기능 중 하나로 가능하게 해줍니다.
LangChain 생태계는 다음과 같습니다.
2. OpenAI 모델 선택하기
LangChain 프레임워크 사용법을 살펴보기 전에 우선 LangChain에서 주로 활용하는 OpenAI LLM 모델에 대해 살펴보고, 적절한 모델을 선정하는 방법에 대해 알아보겠습니다.
LangChain에서 OpenAI의 ChatGPT 모델을 사용하기 위해서는 ChatOpenAI 라는 클래스를 활용합니다. ChatOpenAI 클래스는 지정된 api-key를 활용해 OpenAI사 ChatGPT 모델 응답 요청할 수 있는 client 인스턴스를 생성합니다. 이렇게 생성한 client 인스턴스를 활용해 우리는 LangChain 프레임워크 상에서 ChatGPT의 응답을 요청하고 반환받을 수 있습니다.
ChatOpenAI 클래스에는 다양한 옵션을 지정할 수 있습니다. 다음의 예시를 통해 주요 옵션에 대한 설명을 정리해보았습니다.
| 파라미터(옵션) | 설명 |
|---|---|
temperature | LLM 모델의 출력이 사용하는 단어의 무작위성을 제어합니다. (범위 : 0~2) |
max_token | LLM 모델이 생성할 토큰의 최대 수를 지정합니다. |
model_name | 사용할 LLM 모델을 지정합니다. |
model_name 이라는 옵션을 통해 사용할 LLM 모델의 종류를 지정할 수 있습니다. gpt-4o, gpt-4o-mini, gpt-3.5-turbo 등 다양한 모델 중에서 선택할 수 있습니다.
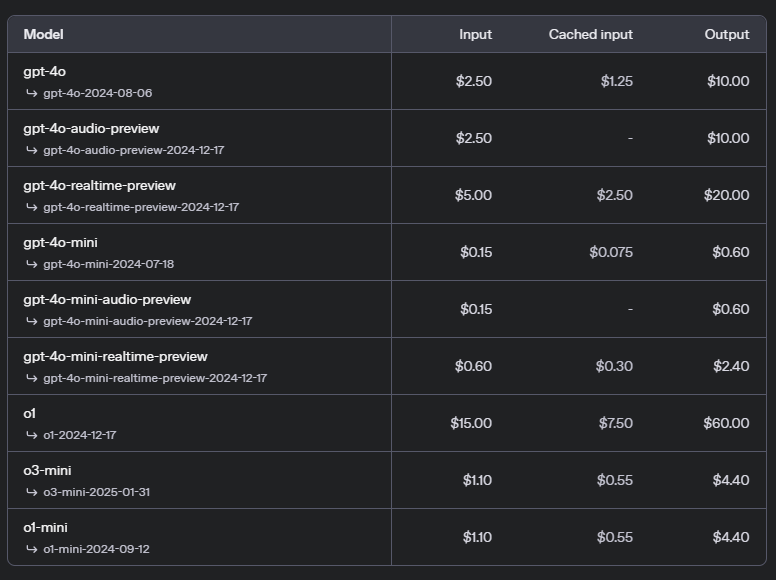
다만, 위와 같이 각 모델 마다 성능의 차이 외에도 context length도 차이가 나며 input token과 output token의 가격도 차이가 나게됩니다.
context length..? input/output token의 가격 차이...? 왜 이러한 차이가 나는 지 제대로 알아야 모델을 제대로 비교하고 적절한 모델을 선택하는 힘을 기를 수 있을 것입니다. 이에 대해 조금 더 자세히 알아보죠.
2-1. Token 을 기준으로 고려하기
Token이란 자연어 처리의 주요 개념 중 하나로, 텍스트를 작은 단위로 나누어 처리하기 위해 사용되는 단위입니다. 단어도 토큰이 될 수 있고, 형태소, 개별 문자 모두 토큰이 될 수 있습니다.
LLM에서의 토큰은 LLM을 학습시킬 당시 모델이 이해하고 처리하기 위해 사용했던 텍스트의 기본 단위를 의미합니다. 즉, 우리는 특정 LLM이 이해할 수 있도록 텍스트를 기본 단위로 나누어 제공해야하는 것이죠. 이렇게 텍스트를 LLM 모델이 이해할 수 있도록 나누는 작업을 Tokenization(토큰화) 라고 합니다.
단적으로 LLM은 일련의 token을 입력받아서 일련의 token을 생성해내는 방식으로 동작합니다. 따라서 어떤 토큰화 방식이 사용되느냐에 따라 모델의 성능과 효율성이 결정됩니다.
그래서 Token을 기준으로 적절한 가격의 모델을 선정하기 위해서는 모델의 목적과 텍스트 데이터의 특성을 고려해야합니다.
텍스트 데이터의 특성은 왜 고려해야 할까요? 언어에 따라 토큰이 달라지기 때문입니다. 실제로 gpt-3.5-turbo 기준 영어의 토큰 효율이 한글의 효율보다 좋지 못했습니다. 아래와 같은 방식입니다.
| 언어 | 원문 | 토큰화 |
|---|---|---|
| 영어 | You are a helpful assistant | You + are + a + helpful + assistant |
| 한글 | 안녕하세요? 반가워요 | 안 + 녕 + 하세요 + ? + 반 + 가 + 워 + 요 |
언어적 특성 상, 한글은 한 단어가 그대로 한 토큰이 되기 어렵기 때문에 영어보다 토큰화 효율이 떨어지는 경우가 있습니다. 이렇게 언어별로 토큰 수 가 달라져서 책정되는 가격이 달라질 수 있기 때문에 우리는 텍스트의 특성도 고려하여 모델을 선정해야합니다.
한 가지만 더 짚고 넘어가자면, 모델 별로도 토큰화 방식에 차이를 보이기 때문에 실제로 토큰 가격을 계산해보고 선정하는 것이 좋겠습니다!
그럼 어떻게 토큰 비용을 계산할 수 있는가! 다음 사이트에서 모델별 예상 토큰 비용을 계산할 수 있습니다.
모델 선정 시 한번 사용해보면 편리할 것 같습니다. 그리고 아래의 사이트에서는 모델별 토큰 비용을 정리하여 제공하고 있습니다.
OpenAI GPT API Pricing Calculator
2-2. Context Window 를 기준으로 고려하기
이제 Context Length에 대해 살펴보겠습니다. Context Length는 LLM이 한번에 처리할 수 있는 최대 토큰 수를 의미합니다. 각 GPT 모델의 Context Length는 다음과 같습니다.
gpt-3.5-turbo: 16k tokengpt-4o: 128k token
그런데, 오해하면 안되는 부분이 있습니다. Context Length가 128k 라고 해서 128k의 토큰을 입력할 수 있다고 생각하면 안된다는 점입니다.
이 Context Length는 시스템 프롬프트와 입력 토큰, 참고할 문서, 대화 내용 그리고 출력 토큰 까지도 포함한 수치 입니다. 출력 길이가 길어질 수 록, 입력할 수 있는 토큰의 수는 줄어들게 되는 것이죠. 따라서 Context Length가 128k 라고 해서 128k의 토큰을 입력할 수 있다고 판단해서는 안됩니다.
이런 점 때문에 Context Length를 고려할 때 함께 고려해야 하는 것이 바로 LLM이 한번에 출력해낼 수 있는 토큰의 수치인 max_token 수치 입니다. 이 수치 값에 따라 시스템 프롬프트와 입력 토큰의 수치가 정해지기 때문이죠.
최신의 모델은 큰 Context Length를 지원하기 때문에 max_length 만큼의 토큰을 제외하더라도 많은 수의 토큰을 입력할 수 있어 입력에서의 오류는 잘 일어나지 않습니다. 하지만, 어플리케이션을 개발하는 입장에서 반드시 고려되어야하는 수치입니다. (가령, 더 긴 결과물을 원하더라도 max_length 만큼 만 생성할 수 있기 때문에 '이어서 생성하기'와 같은 기능을 구현해야할 수 도 있습니다.)
2-3. Input Token / Output Token 가격 차이
이처럼 LLM은 Context Window에서 max_length만큼의 token 수를 제외하더라고 방대한 양의 token을 처리하여 답변을 생성해냅니다. 이에 따라 자연히 입력 토큰의 가치 보다 출력 토큰의 가치가 더 높아질 수 밖에 없는 것이죠.
실제로, gpt-4o와 gpt-4o-mini 모델의 경우 input token의 가격보다 output token의 가격이 4배 높았습니다.
요약 task와 같이 출력 token이 적은 서비스의 경우가 문서/보고서 작성 task와 같은 서비스에 비해 저렴한 이유도 여기에 있습니다.
2-4. 결론
지금까지 알아본 고려요소를 정리하면 다음과 같은 결론을 내릴 수 있습니다.
결론 : 우리는 Context Window와 Input/Output Token 가격 까지 모두 고려하여 적절한 모델을 선정해야합니다.
Outro
지금까지 LangChain 프레임워크에 대한 소개와 LangChain에서 활용할 OpenAI 모델 선정 시 고려요소 까지 알아보았습니다.
특히, Context Length와 Input/Output Token Pricing 에 대한 내용은 추후 어플리케이션 설계 시 반드시 고려해야할 요소이기 때문에 잘 정리해둘 수 있었던 좋은 기회가 되었습니다.
다음 포스트 부터 실제 LangChain 문법에 대해 하나씩 정리해보도록 하겠습니다.
출처
