
Intro
지난 포스트에서 LangChain 프레임워크에 대한 간단한 소개와, LangChain에서 활용한 OpenAI 모델 선정 시 고려사항에 대해 정리해보았습니다.
이제 본격적으로 LangChain 프레임워크의 사용법을 살펴보겠습니다.
이번 포스트에서는 LangChain에서 OpenAI 모델을 사용하는 방법과 LangSmith로 LangChain의 실행 내용을 추적하는 방법에 대해 알아보겠습니다.
1. LangChain에서 ChatGPT 사용하기
LangChain은 LLM을 활용한 어플리케이션을 구현하기 위한 프레임워크 입니다. 그렇다면 프레임워크 내에서 어떻게 LLM을 사용하는 지 알아야겠죠?
지금부터 LangChain에서 ChatGPT를 사용하는 방법에 대해 알아보겠습니다.
1-1. 라이브러리 설치
가장 먼저 필요한 라이브러리를 설치하겠습니다.
pip install langchain langchain-openai dotenvlangchain: LangChain 프레임워크langchain-openai: ChatGPT를 LangChain에서 사용하기 용이하도록 OpenAI와 LangChain이 협력하여 구현한 라이브러리dotenv:.env에 작성한 값들을 환경변수로 등록하기 위한 라이브러리
1-2. OPENAI_API_KEY 발급
우리는 로컬에서 ChatGPT를 실행시킬 수 없기 때문에, 우리의 질문을 OpenAI에게 요청하고 응답을 받아오는 형태로 모델을 사용해야합니다.
따라서, LangChain에서 OpenAI의 ChatGPT를 활용하기 위해서는 OPENAI API에서 API Key를 발급 받아야 합니다. 이 사이트에 접속하여 로그인을 한 후, OPENAI Platform으로 넘어와 봅시다.
이 페이지에서 우측 상단 프로필 이미지를 클릭해서 your profile 버튼을 누르고, 좌측 메뉴에서 API Keys 메뉴를 선택하면 아래와 같이 발급이 가능한 화면에 진입할 수 있습니다.
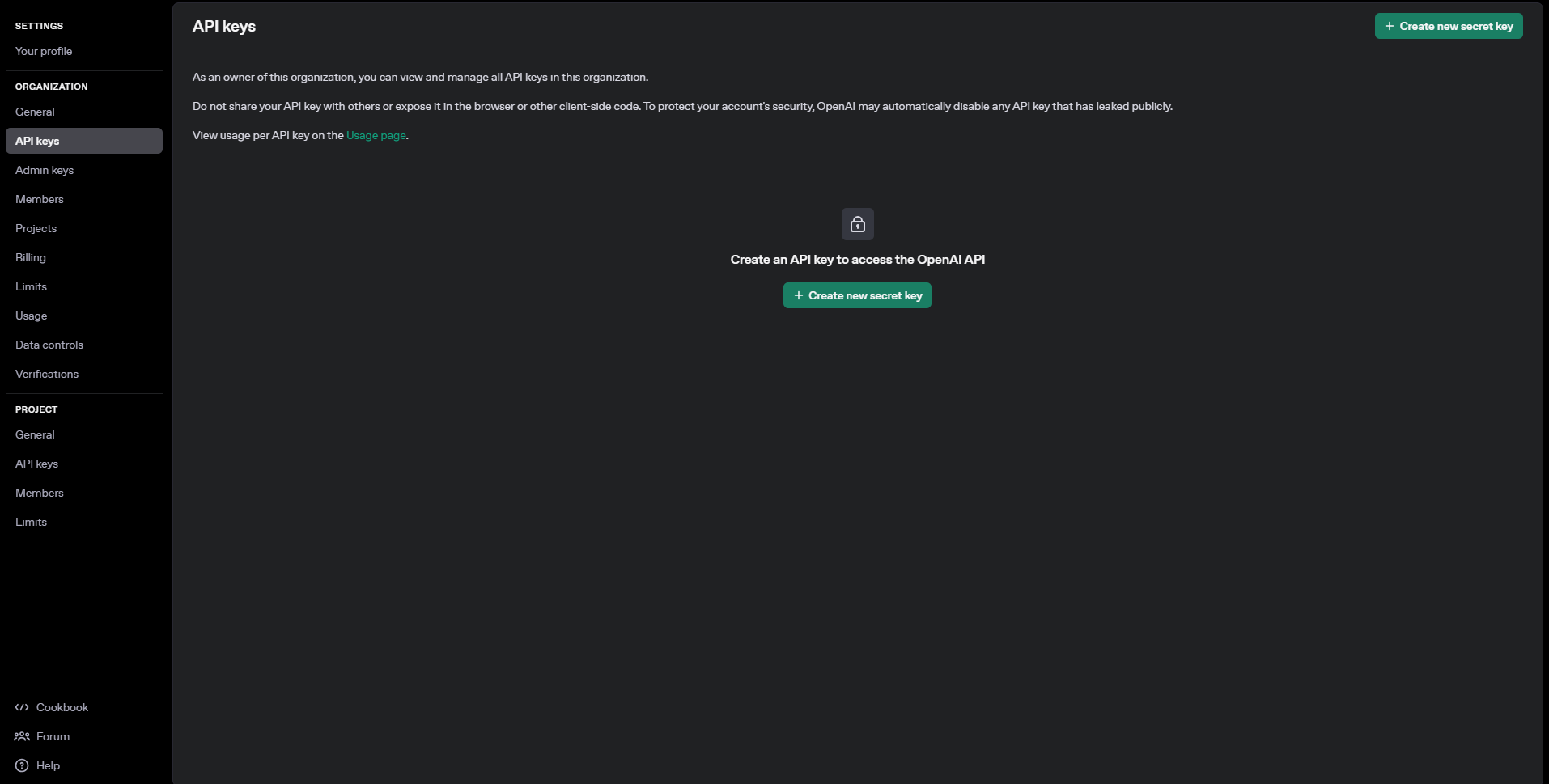
여기서 Create new secret key 버튼을 클릭해 아래와 같이 발급 절차를 수행합니다.
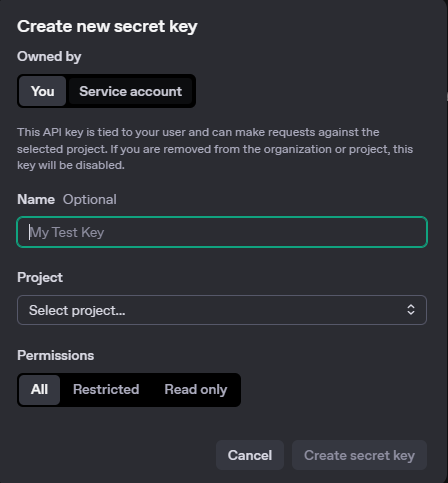
이제 발급된 API Key를 별도 안전한 공간에 저장합니다. 이후로는 Key 전체를 조회할 수 없기 때문에 반드시 지금 안전한 곳에 저장해둡시다.
1-3. OPENAI_API_KEY 환경 변수 등록
이제 발급받은 API KEY를 환경 변수로 등록합니다.
현재 실행할 파일이 있는 디렉토리에 .env 파일을 생성하고 다음과 같이 작성합니다.
OPENAI_API_KEY = "<your-api-key>"이후 실행할 파일에서 아래와 같이 코드를 작성합니다.
from dotenv import load_dotenv
load_dotenv()이렇게 load_dotenv() 함수를 사용하면 현재 디렉터리에서 .env 파일을 찾아 내부에 작성된 변수 값들을 환경 변수로 등록합니다.
이제 LangChain에서 ChatGPT를 사용할 모든 준비가 끝났습니다. 이제 본격적으로 활용하는 방법을 알아보겠습니다.
1-4. ChatOpenAI로 ChatGPT 클라이언트 생성하기
앞서 말씀드린 것처럼, 우리는 로컬에서 ChatGPT를 실행시킬 수 없습니다.
따라서 로컬에서 실행 중인 LangChain에서 ChatGPT의 생성 결과를 받아보기 위해서는,
1. OpenAI에게 요청을 보내고
2. 이에 대한 응답을 받는 형태로 구현해야 합니다.
즉, chatGPT에 요청을 보내고 응답을 받아줄 클라이언트를 생성해야합니다.
LangChain에서는 이것을 langchain_openai 라이브러리의 ChatOpenAI 클래스를 통해 쉽게 구현해두었습니다. 이 클래스에 여러 옵션을 설정하여 인스턴스를 생성하면, 해당 옵션에 맞는 ChatGPT 클라이언트를 생성해주는 것이죠.
ChatOpenAI 클래스는 다음과 같이 사용합니다.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model_name = "gpt-4o-mini", # 사용할 모델명
temperature=0.1, # 창의성 (0.0 ~ 2.0)
max_tokens=1000 # 생성할 최대 토큰 수
)더 많은 옵션을 지정할 수 있기 때문에, 어떤 옵션이 있는 지 궁금하다면 여기에서 더 조사할 수 있겠습니다.
이 코드에서는 llm이라는 변수에 ChatGPT 클라이언트를 생성하여 할당합니다.
1-5. ChatOpenAI 실행하기, 응답구조 확인하기
이제 ChatGPT에게 질문을 해보겠습니다.
질문을 던지기 위해서는 기본적으로 .invoke() 메서드를 사용합니다.
question = "대한민국의 수도는 어디입니까?"
response = llm.invoke(question)이렇게 받은 응답(response)를 출력해보면 다음과 같습니다.
AIMessage(content='대한민국의 수도는 서울입니다.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 9, 'prompt_tokens': 16, 'total_tokens': 25, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_709714d124', 'finish_reason': 'stop', 'logprobs': None}, id='run-5749bd3b-d7c0-4b1a-a833-10c93345ff7d-0', usage_metadata={'input_tokens': 16, 'output_tokens': 9, 'total_tokens': 25, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})reponse를 출력해보니 AIMessage 객체라는 것을 알 수 있습니다. 그리고 실제 질문에 대한 답변 텍스트는 content라는 key에 들어있다는 것을 확인할 수 있습니다.
즉, ChatOpenAI 인스턴스를 실행하면 그 결과는 AIMessage 객체로 반환되고 그 내부에 질문에 대한 답변 뿐 아닌 다양한 내용을 포함하고 있는 것입니다.
응답구조를 조금 더 자세히 살펴보겠습니다.
for key, val in dict(response).items():
print(f"Key : {key}")
print(f"Value : {val}")
print()이렇게 응답 객체를 dict로 변환하여 그 내용을 출력해보면,
Key : content
Value : 대한민국의 수도는 서울입니다.
Key : additional_kwargs
Value : {'refusal': None}
Key : response_metadata
Value : {'token_usage': {'completion_tokens': 9, 'prompt_tokens': 16, 'total_tokens': 25, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': '-', 'finish_reason': 'stop', 'logprobs': None}
Key : type
Value : ai
Key : name
Value : None
Key : id
Value : <생략>
Key : example
Value : False
Key : tool_calls
Value : []
Key : invalid_tool_calls
Value : []
Key : usage_metadata
Value : {'input_tokens': 16, 'output_tokens': 9, 'total_tokens': 25, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}content에서 실제 답변을 제공하고 있고, response_metadata에서 토큰 사용량, 사용한 모델 등과 같이 더 많은 정보를 포함하고 있는 것을 알 수 있습니다.
특히 response.usage_metadata["total_tokens"] 와 같이 접근하면 매 응답 마다 사용된 토큰의 양을 추적할 수 있습니다.
응답 구조를 잘 파악하고 있는 것이 중요하겠습니다.
1-6. ChatOpenAI 스트리밍 출력하기
실제로 ChatGPT를 사용해보면 앞서 실행한 방식처럼 답변이 한번에 모두 출력되는 것이 아니라 토큰이 생성될 때 마다 바로바로 화면에 출력되는 것을 확인할 수 있습니다.
이렇게 구현하기 위해서는 앞선 .invoke() 메서드를 활용하는 것이 아닌, .stream() 메서드를 활용해 응답을 요청하면 됩니다. 다음과 같이 사용합니다.
llm = ChatOpenAI(
model_name = "gpt-4o-mini", # 사용할 모델명
temperature=0.1, # 창의성 (0.0 ~ 2.0)
)
answer = llm.stream("대한민국에서 방문할 만한 관광지 10을 추려서 정리해주세요")이번에도 응답의 형태를 확인해보겠습니다. 동일하게 AIMessage 객체일까요?
<generator object BaseChatModel.stream at --->이상합니다. 답변이 generator 이네요.
즉, range 함수와 같이 for문에서 하나씩 값을 생성해내는 객체인 것이죠. 그래서 실행 화면 상에 스트리밍 되는 것처럼 구현하기 위해서는 다음과 같이 코드를 작성해야합니다.
for token in answer:
print(token.content, end="", flush=True)여기서 flush=True 라고 설정했기 때문에, 출력할 모든 값이 버퍼에 들어오는 것을 기다리지 않고 곧바로 출력할 수 있습니다. 스트리밍 되는 것이죠.
하지만 아직 충분하지 않습니다.
이렇게 한번 스트리밍 형태로 출력하게 되면 answer를 재활용해서 다시 출력도 불가능하고 답변 결과를 하나의 텍스트로 가져올 수 도 없습니다. .stream()의 응답 결과는 휘발성 이기 때문입니다.
따라서 다음과 같이 응답 결과를 모아서 하나의 텍스트로 저장해주어야 합니다.
complete_answer = ""
for token in answer:
print(token.content, end="", flush=True)
complete_answer += token.content2. LangSmith에서 LLM 추론내용 추적하기
이렇게 LangChain에서 ChatGPT를 다양하게 활용해보았습니다.
하지만 활용만 하는 정도로는 부족하겠죠? 우리가 구현한 어플리케이션에서 LLM이 올바르게 추론하고 있는 지, 내부에서 어떻게 동작하고 있는 지 추적할 필요가 있습니다.
LangChain에서는 이를 LangSmith를 통해 가능하도록 만들어줍니다. 지금부터 LangSmith를 활용해서 LLM의 추론내용을 추적하는 방법을 알아보겠습니다.
2-1. LangSmith API Key 발급 받기
OpenAI의 API Key를 발급받은 것과 마찬가지로 LangSmith 홈페이지에서 API Key를 발급받아야 합니다.
위의 홈페이지에서 로그인을 해봅시다. 그럼 다음과 같은 화면으로 넘어올 수 있습니다.
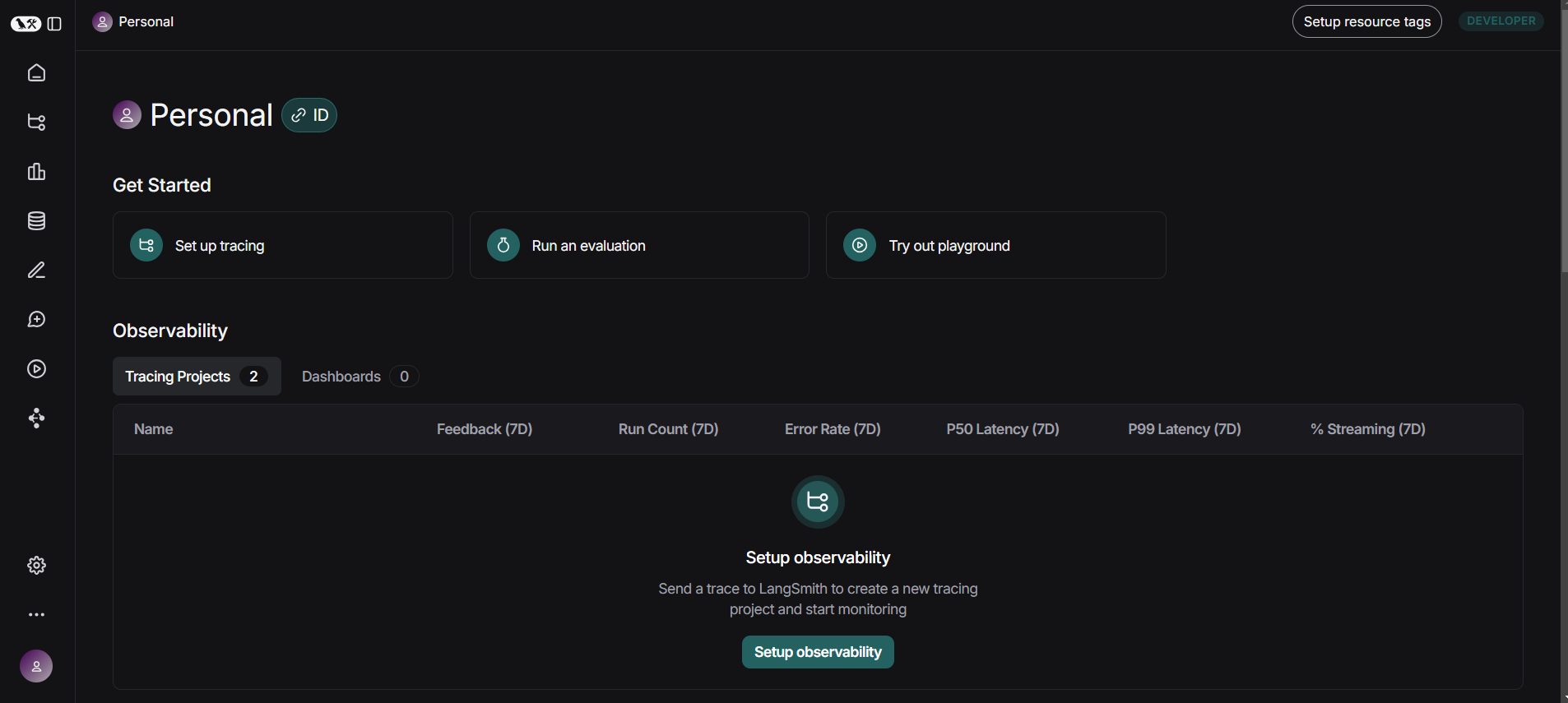
여기서 좌측하단 설정 버튼을 클릭하고, API Key 라는 메뉴로 들어갑니다.
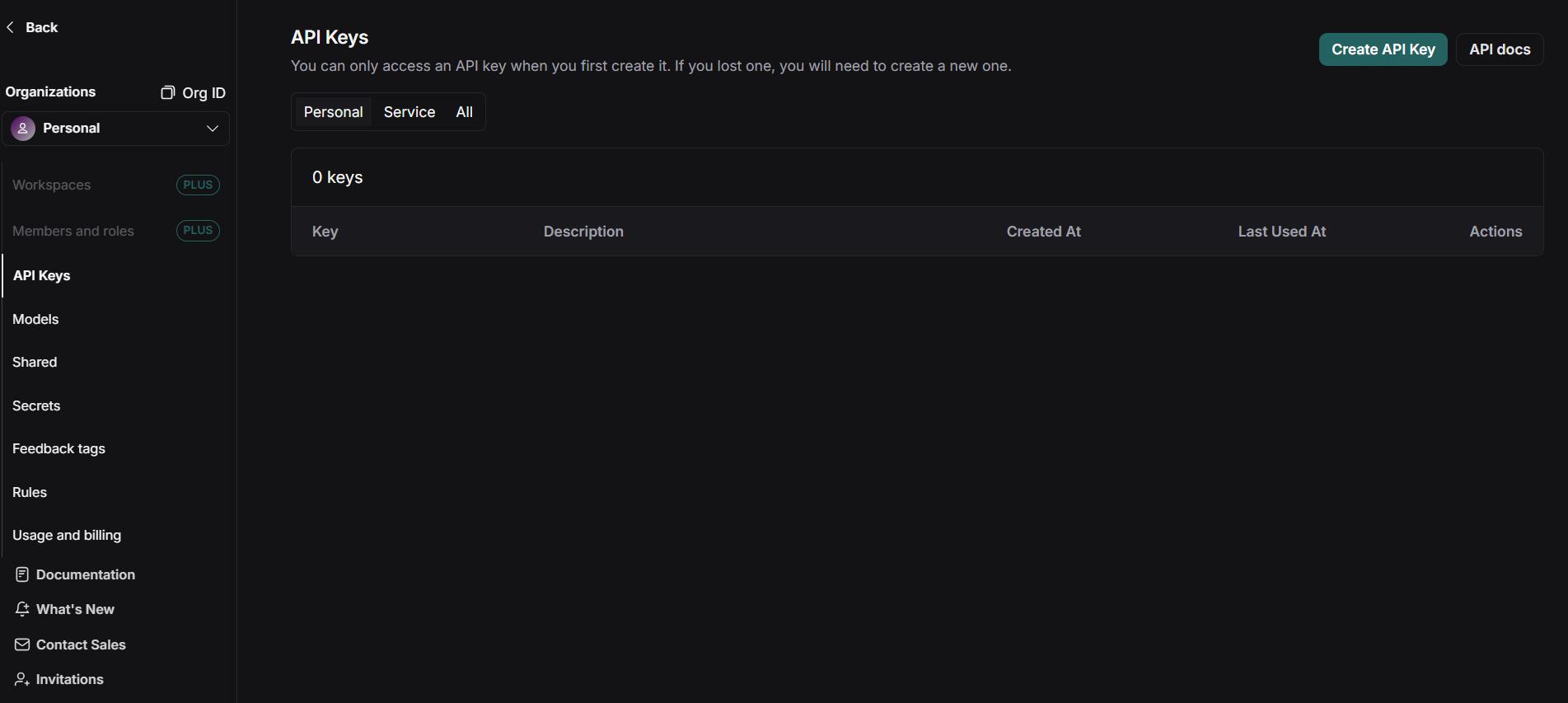
다음 우측 상단의 Create API KEY 버튼을 통해 API Key를 발급받고 이를 안전한 장소에 저장합니다. (처음 발급된 창 외에는 다시 확인할 수 없으므로 반드시 복사해서 안전한 장소에 저장해둡시다)
2-2. 환경 변수 설정하기
이제 앞서 OPENAI_API_KEY를 환경변수로 설정한 것과 마찬가지로, 발급받은 LangSmith API Key를 포함한 여러 환경변수 값을 .env 파일에 작성하고, load_dotenv()를 활용해서 환경변수로 설정합니다.
이번에 추가할 환경변수는 다음과 같습니다.
LANGCHAIN_TRACING_V2=true
LANGCHAIN_ENDPOINT="https://api.smith.langchain.com"
LANGCHAIN_API_KEY="<your-api-key>"
LANGCHAIN_PROJECT="<your-project-name>"위의 값에서
LANGCHAIN_API_KEY에 앞서 발금 받은 LangSmith API Key를 작성하고,LANGCHAIN_PROJECT에 LangSmith에서 추적 내용을 저장할 프로젝트 그룹명을 지정합니다.
이렇게 작성된 .env 파일을 load_dotenv() 함수를 활용해 환경변수로 등록하면, LangChain에서의 모든 실행 내역이 자동으로 LangSmith에 기록됩니다.
2-3. LangSmith에서 추론내용 추적하기
이제 모든 설정이 끝났습니다.
다시한번 모델을 실행하고 실행 내역을 LangSmith에서 확인해봅시다.
LangSmith 홈페이지에서 로그인 후, Tracing Project 메뉴로 들어가면 다음과 같이 앞서 지정한 프로젝트 명으로 지정된 행이 존재합니다.
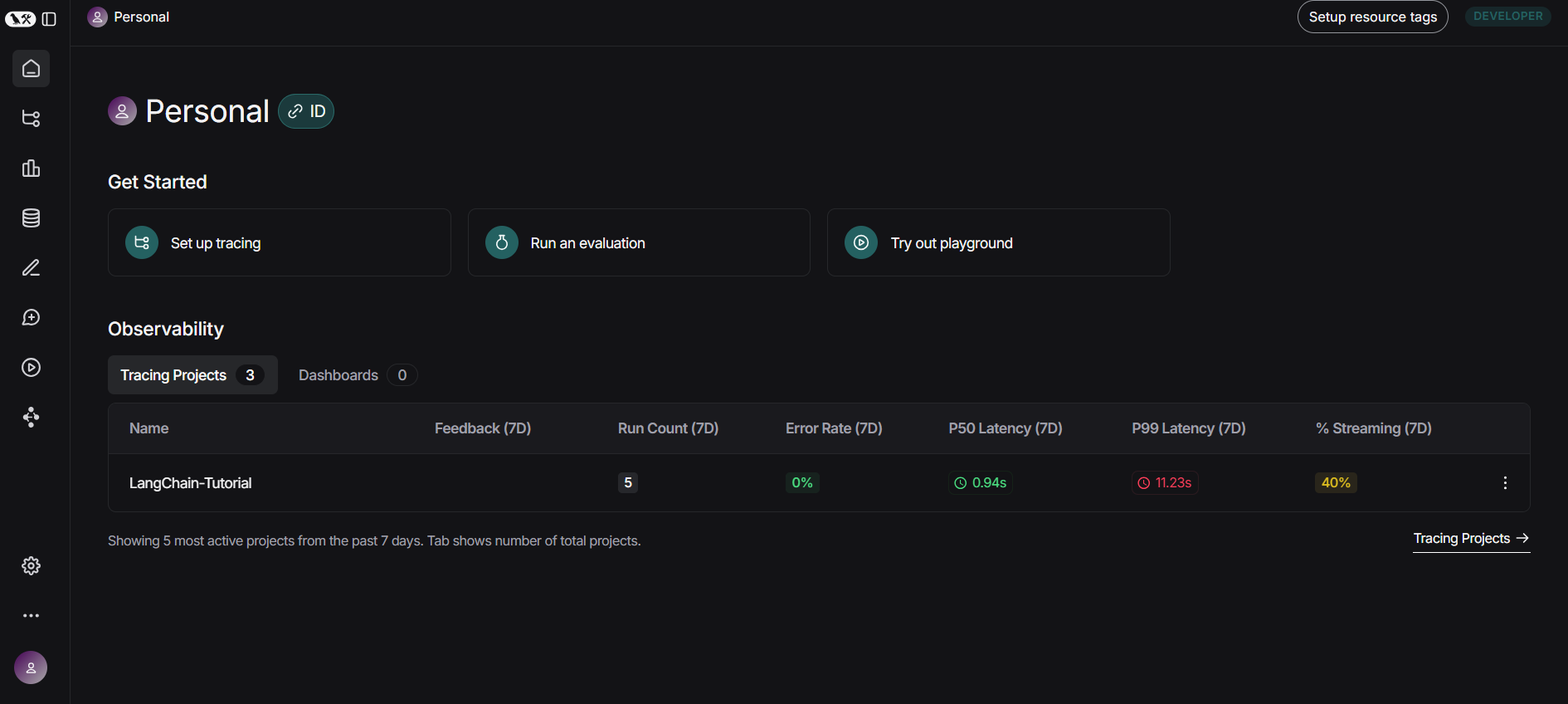
해당 프로젝트로 진입하면 아래와 같이 각 실행에 대한 추적 결과 내역을 확인할 수 있고,
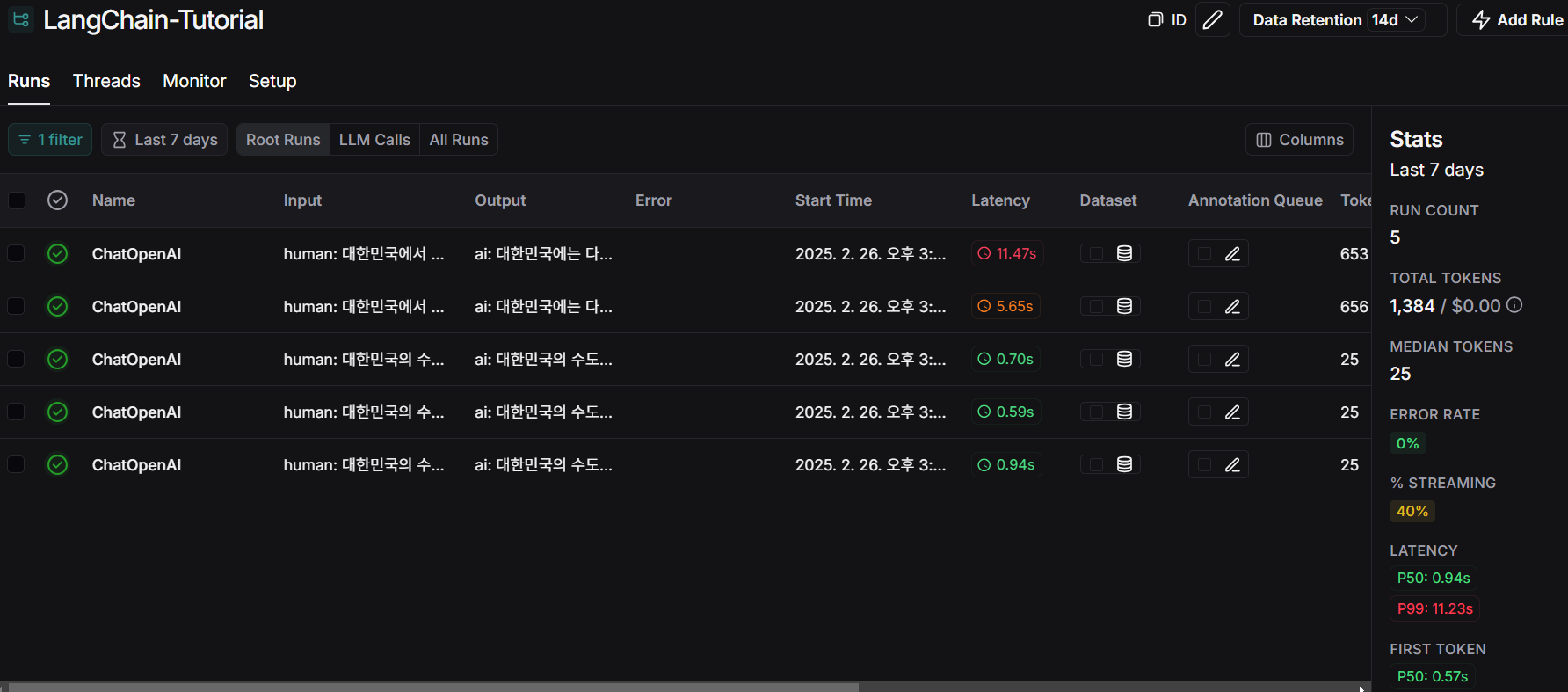
아래와 같이 각 추적 내용에 대해서도 각 단계에서의 입/출력, 호출 결과, 추론 결과, 토큰 사용량, 총 비용, 실행/지연 시간 등의 더 자세한 정보를 확인할 수 있습니다.
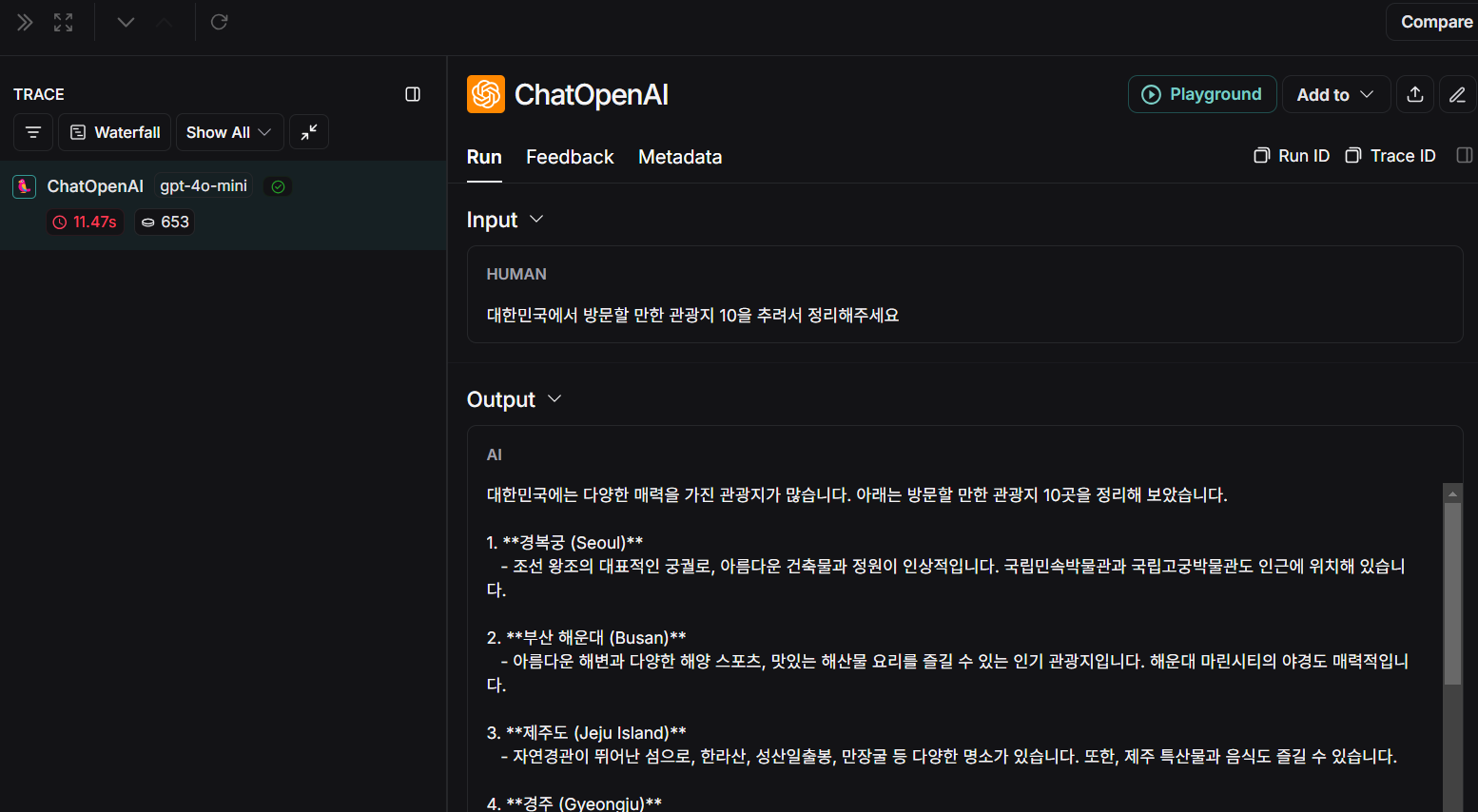
이러한 방식으로 서비스 단계에서는
- 사용자의 질의응답 내역을 추적하며 어떤 질문을 하였고, 어떤 응답을 하였는 지 추적이 가능
- 사람들이 자주 이용하는 플랫폼의 정보, 다양한 메타 데이터 추적 가능
이라는 장점이 있고,
개발 단계에서는 내부의 동작 단계를 하나하나 추적하면서 검증할 때 많이 사용하고, 에러 발생 추적에도 유용하게 사용됩니다.
이렇게 LangSmith를 활용하는 방법을 익혀두면 LLM 어플리케이션 개발 시 굉장히 유용할 것 같습니다.
Outro
지금까지 LangChain에서 LLM 모델을 활용하고, 그 실행 내역을 LangSmith로 추적하는 방법을 알아보았습니다.
특히, LangSmith를 활용하는 방법을 익혀서 확인하는 습관을 들이는 것이 향후, LangChain을 활용한 어플리케이션 개발 시 큰 도움이 될 것이기 때문에 이번 기회를 통해 잘 정리할 수 있어 뿌듯합니다.
출처
