
Intro
지난 포스트에서 LangChain에서 LLM을 활용하는 방법과 LangSmith로 실행 내역을 추적하는 방법에 대해 정리해보았습니다.
이번 포스트에서는 LLM 활용법을 조금 더 발전시켜 멀티 모달 모델을 활용해 LangChain에서 LLM에게 이미지를 포함한 질문을 던지는 방법을 알아보겠습니다.
1. Multi-Modal 이란?
멀티 모달이란, 여러 형태의 정보를 통합하여 처리하는 기술이나 접근 방식을 의미하는 용어입니다. LLM이 단순히 텍스트 질의에 대한 텍스트 답변을 생성하는 것이 아닌, 이미지와 텍스트를 동시에 처리하여 답변하는 식으로 다양한 타입의 데이터를 처리하여 답변을 생성하는 것을 말합니다.
멀티 모달 모델은 다음과 같은 데이터 유형을 인식할 수 있도록 구현됩니다.
- 텍스트 : 문서, 책, 웹 페이지 내용 등 텍스트로 이루어진 모든 데이터
- 이미지 : 사진, 그림, 그래픽 등
- 오디오 : 음성, 음악, 소리, 효과 등
- 비디오 : 동영상, 실시간 스트리밍 영상 등
현재 OpenAI에서 제공하는 모델 중에서 gpt-4o가 멀티 모달 모델로 제공되고 있습니다. 이미지를 처리해낼 수 있는 vision 기능이 추가된 모델로 아직 이미지를 생성해낼 수 는 없지만, 이미지를 입력으로 받아 인식하고 이를 바탕으로 답변을 생성할 수 있습니다.
오늘은 이 gpt-4o 모델을 활용해 '이미지 멀티 모달 모델'을 사용하는 방법에 대해 알아보겠습니다.
2. gpt-4o모델에 이미지를 포함한 질문하기
먼저, LLM 클라이언트를 생성해보겠습니다.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model_name = "gpt-4o",
temperature = 0.1
)이전 포스트에서 LangChain 내부에서 OpenAI의 LLM을 활용하기 위해서는 ChatOpenAI 클래스로 클라이언트를 생성해야 한다고 설명드렸습니다. 우리는 LLM의 응답을 받아보기 위해서 OpenAI에게 API 요청을 보내는 것이죠.
2-1. 이미지를 base64 인코딩
그렇다면 이미지를 포함해서 API 요청을 보내려면 어떻게 해야할까요?
이미지를 API 요청에 포함시키기 위해서는 base64 형태로 인코딩 되어야 합니다. 다음과 같이 코드를 작성해봅시다.
import base64
def encode_img_to_base64(file_path):
with open(file_path, "rb") as image_file:
file_content = image_file.read()
return f"data:image/png;base64,{base64.b64encode(file_content).decode('utf-8')}"
file_path = "<your-image-path>"
encoded_image = encode_img_to_base64(file_path)위의 encode_img_to_base64() 함수는 이미지 파일을 읽어 base64 형태로 인코딩 합니다. base64.b64encode(file_content).decode('utf-8')가 이미지 파일을 인코딩하고 디코딩 시 utf-8로 인식할 수 있도록 합니다.
여기서 encode_img_to_base64() 함수의 반환값 형태에 주목해볼까요?
GPT에게 API 요청을 보낼 때 이미지를 보내기 위해서는 단순히 base64로 인코딩된 이미지를 그대로 전달하는 것이 아닌, 반환값의 문자열 형태에 따라 작성해주어야 합니다.
data:<파일확장자>;base64,<base64로 인코딩된 이미지>위와 같은 형태로 만들어서 요청해야 합니다.
2-2. Prompt와 Messages 설정
이제 이미지를 넣어줄 준비가 되었으니, ChatGPT에게 요청할 질문에 이미지를 포함시켜보겠습니다.
지금까지 LLM에게 질문할 때는 질문 텍스트를 그대로 .invoke() 메서드에 넣어서 실행하였습니다.
question = "대한민국의 수도는?"
response = llm.invoke(question)하지만 이렇게 텍스트를 그대로 넣어주는 것이 아닌, system_prompt와 user_prompt를 포함하는 message의 리스트를 넣어서 실행하는 방법도 있습니다. 다음과 같은 방식입니다.
system_prompt = "<system-prompt>"
user_prompt = "<user-prompt>"
system_message = {"role" : "system", "content" : system_prompt}
user_message = {"role" : "user", "content" : user_prompt}
messages = [system_message, user_message]
response = llm.invoke(messages)이렇게 실행시키면 system_prompt를 통해 llm에게 명확한 역할, 즉 페르소나를 부여할 수 있습니다. 또한, 단순히 특정 텍스트에 대한 답변이 아닌 여러 대화 내역(멀티-턴)에 대한 답변을 받아볼 수 도 있습니다.
이를 응용해서 이미지를 포함한 LLM 요청을 수행할 수 있습니다. 다음과 같이 작성해봅시다.
# system prompt 설정
system_prompt = """
당신은 뛰어난 재무 분석가 입니다.
당신의 임무는 주어진 테이블 형태의 재무제표 이미지를 바탕으로 다양한 시각에서 분석하여 사용자에게 제공하는 것입니다.
"""
# user prompt 설정
user_prompt = """
이 것은 회사의 재무제표 입니다. 이를 다양한 관점에서 분석해주세요.
"""
system_message = {"role" : "system", "content" : system_prompt}
user_message = {
"role" : "user",
"content" : [
{
"type" : "text",
"text" : user_prompt
},
{
"type" : "image_url",
"image_url" : {"url" : f"{encoded_image}"}
}
]
}
# llm에게 요청할 메시지 설정
messages = [system_message, user_message]2-3. Multi-Modal 모델 invoke 하기
이제 이미지를 포함한 요청을 할 준비가 모두 끝났습니다.
다음과 같이 코드를 작성해서 답변을 확인해보겠습니다.
response = llm.invoke(messages)
print(response.content)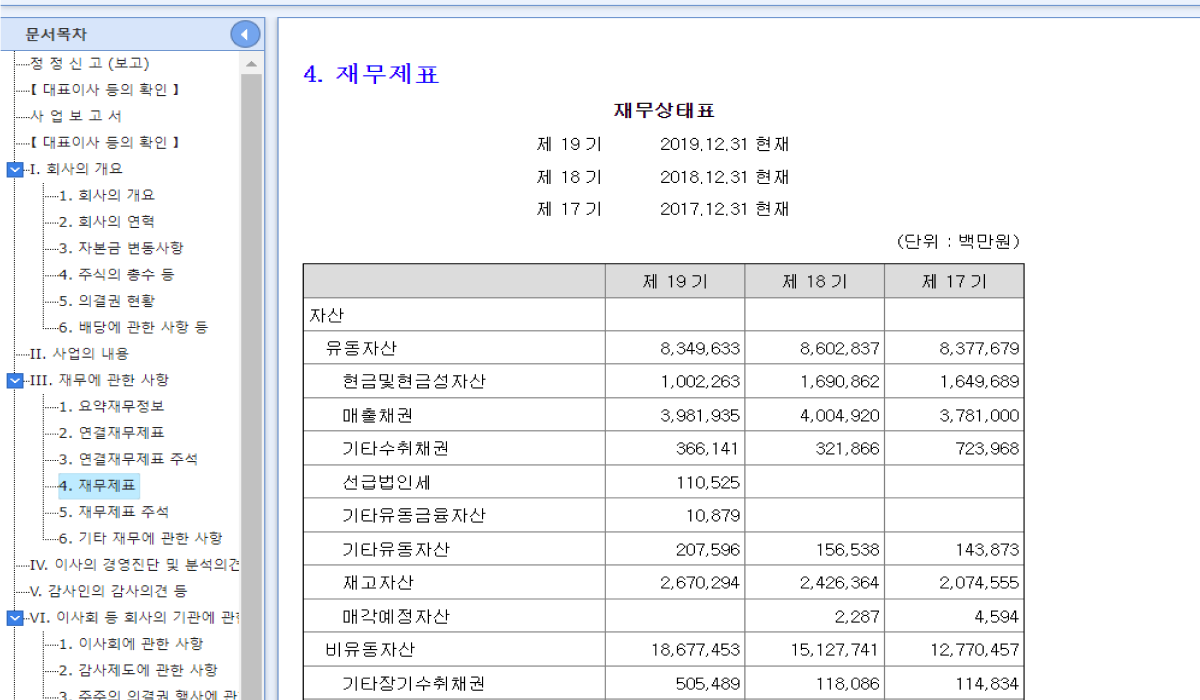
이 이미지에 대한 답변이 다음과 같았습니다.
이 재무제표는 특정 회사의 자산 상태를 보여주고 있습니다. 각 회계연도(제 17기, 제 18기, 제 19기)의 자산 항목을 분석해보겠습니다.
### 유동자산
- **현금 및 현금성 자산**: 제 19기에 감소했습니다. 이는 회사의 유동성에 영향을 미칠 수 있습니다.
- **매출채권**: 제 18기에서 제 19기로 오면서 감소했습니다. 이는 매출 회수 속도가 빨라졌거나 매출이 감소했을 가능성을 시사합니다.
- **기타수취채권**: 제 19기에 증가했습니다. 이는 단기 채권의 증가를 의미합니다.
### 비유동자산
- **기타유동자산**: 제 19기에 증가했습니다. 이는 단기 투자나 기타 자산의 증가를 나타낼 수 있습니다.
- **재고자산**: 제 19기에 증가했습니다. 이는 생산 증가나 판매 감소를 의미할 수 있습니다.
- **비유동자산 총계**: 제 19기에 증가했습니다. 이는 장기 투자나 자산의 증가를 나타냅니다.
### 종합 분석
- **유동자산의 감소**: 이는 회사의 단기 유동성에 부정적인 영향을 미칠 수 있습니다.
- **비유동자산의 증가**: 장기적인 성장 가능성을 나타낼 수 있지만, 유동성 문제를 해결할 필요가 있습니다.
- **전반적인 자산 증가**: 회사의 총 자산은 증가하고 있으며, 이는 성장 가능성을 시사합니다.
이러한 분석을 통해 회사의 재무 상태를 더 깊이 이해하고, 필요한 경우 추가적인 재무 전략을 고려할 수 있습니다.system_prompt와 user_prompt를 적절히 지정하였기 때문에, 이미지의 내용을 단순히 출력해주는 것이 아닌 분석한 결과를 반환한 것을 확인할 수 있습니다.
이렇게 LLM 에게 이미지를 포함한 답변을 요청할 수 있습니다.
Outro
이번 포스트에서는 멀티 모달 모델을 활용해 이미지를 포함한 질문에 대한 답변을 요청하는 방법을 알아보았습니다. system_prompt와 user_prompt를 적절히 지정하여 간단한 분석까지 진행하는 모습까지 확인하였습니다.
이미지 멀티 모달 모델 활용 방법을 익혀둠으로써, 더 복잡한 요청을 통해 LLM 어플리케이션을 고도화할 수 있을 것으로 기대됩니다.
출처
