Softmax 란?
실수 벡터를 학률 분포로 바꿔주는 함수
즉, 임의의 실수 벡터를 [0, 1] 범위의 값으로 정규화해 함이 1이 되도록 만드는 함수
Softmax 함수는 이 목적을 달성하기 위해, 입력 벡터 에 대해 크게 2단계의 변환을 거칩니다.
- 입력 벡터의 각 값을 지수 변환 (exponential transform)
- 지수 변환한 각 값을 정규화 (normalization)
왜 '지수 변환'과 '정규화' 과정을 거칠까요?
지수 변환의 효과
1. 항상 양수로 만든다.
입력 실수 벡터는 양수, 음수, 0 모든 값을 가질 수 있습니다.
하지만, softmax는 각 값을 확률값(가중치)로 해석하는 것이 목표이기 때문에 '음수'는 확률로 해석하기 부적절합니다. 따라서, 입력 벡터 내의 음수 값을 '0보다 큰 값'으로 적절히 변환해야합니다.
지수 함수는 항상 0보다 큰 값을 가지므로, 어떤 입력이든 양수 범위의 값으로 변환 합니다.
따라서, 각 값을 확률 값으로 이해하기 적절한 조건을 갖출 수 있습니다.
2. 상대적인 차이를 강조한다.
지수 함수는 입력값이 차이를 크게 만드는 효과를 발휘합니다.
예를 들어, [2, 1]이라는 입력 벡터에 지수 변환을 수행하면 [7.39, 2.71]의 벡터가 됩니다. 원래 1이라는 차이값이 4.68로 더 강조되는 효과를 얻게 된 것입니다.
즉, 지수 변환은 큰 차이를 더 크게, 작은 차이를 더 작게 만들어, 차이(최고값)을 더욱 부각 시키는 효과를 가지게 됩니다.
따라서, 분류 문제에서 신경망의 출력이나, Attention의 출력에서 가장 유력한 후보에 더욱 집중할 수 있도록 돕습니다.
정규화의 효과
정규화는 각 값을 softmax 함수 처리 결과의 각 값을 확률로 해석할 수 있는 조건을 맞추어주는 역할을 합니다. 이는 다음의 수식과 같이 수행됩니다.
sofmax 변환 결과의 각 값이 확률로 해석되기 위해서는 다음 2가지 확률의 조건을 만족해야합니다.
- 확률값은 [0, 1] 범위에 존재하며, 음수가 될 수 없다.
- 모든 확률값의 합은 1이다.
지수 변환을 통해 각 값을 양수 범위의 가중치값으로 조정하였고, 정규화를 통해 모든 값이 [0, 1] 범위에 존재하며 그 모든 값의 합이 1이 되도록 조정하는 것입니다.
Softmax의 종합적인 동작 원리
즉, softmax 함수의 변환 과정을 종합적으로 설명하자면 다음과 같습니다.
- 지수 변환 : 입력값 간의 차이를 강조 + 음수 제거 (즉, 각 값을 양수 범위의 가중치로 변환)
- 정규화 : 모든 가중치 점수를 [0, 1] 범위의 값으로 축소, 총합을 1로 맞춤 (즉, 확률로 해석할 수 있도록 변환)
이를 통해 실수 벡터를 확률 분포로 바꿔줄 수 있기 때문에, 분류 태스크를 수행하는 신경망의 출력이나, Attention 알고리즘에서 Query와 Key의 유사도를 점수로 계산하고 이를 Softmax로 변환하여 Value에 곱할 가중치로 사용할 수 있게 됩니다.
Softmax와 입력 벡터 간의 관계
softmax는 특정 클래스가 항목에 대한 가중치로써 해석될 수 있다는 것을 알았습니다.
그렇다면 softmax는 언제나 모든 입력 벡터에 대해 의도한 대로 잘 동작해줄까요?
입력 벡터의 각 원소 값이 커질 때
softmax의 함수를 다시 한번 정리하자면 다음과 같습니다.
여기서 입력 벡터의 절댓값이 커져서 다른 요소에 비해 특정 값()이 커진다면 어떻게 될까요?
- 가 매우 커지면 가 매우 큰 수 로 발산합니다.
- 지수 함수는 차이를 증폭시키는 효과가 있습니다. 즉, 특정 한 요소가 다른 요소에 비해 클 경우 그 차이는 더욱 증폭될 것이고, 정규화를 거쳐 해당 값 이외의 값은 모두 0에 가깝고, 해당 값만 1에 가까워지는 현상이 나타날 것입니다.
즉, Softmax의 출력이 거의 One-Hot 확률 분포에 가까워질 것입니다. (한 요소만 1이 되고, 나머지는 0에 가까움)
이렇게 되면, 출력 확율의 변화율(기울기)가 매우 작아집니다.
Sofmax 함수의 미분
Gradient Descent 알고리즘에 따라 미분으로 학습 신호를 계산하기 위해서는 softmax를 포함한 전체 모델의 미분과정이 필요합니다.
실제로 입력 값에 따른 softmax의 기울기 영향을 알아보기 위해, softmax의 미분을 계산해봅시다. 와 로 놓는다면, Softmax의 함수의 미분은 '몫의 미분'으로 정의될 수 있습니다.
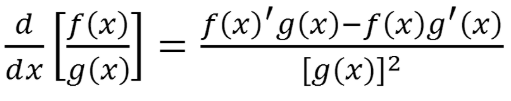
이제 임의의 값 n에 대해, softmax 함수를 에 대해 편미분을 수행하면, 일 때와, 일 때 두 가지 경우에 따라 미분 값이 달라지게 됩니다.
인 경우 )
이므로,
가 됩니다. 이를 전개하면 다음과 같습니다.
인 경우 )
이므로,
가 됩니다. 이를 전개하면 다음과 같습니다.
미분 결과
즉, 임의의 요소 z_n에 대해 softmax 함수의 미분은 다음과 같이 정의된다.
입력값 스케일에 따른 softmax 기울기
이제 softmax의 미분 함수에 근거해 입력값의 스케일이 softmax 함수의 gradient에 어떤 영향을 미치는 지 알아보겠습니다.
특정 의 값이 다른 값보다 절댓값이 크게 되면, 앞에서 설명한 것처럼 만 다른 값에 비해 1에 가까워지고, 다른 값은 0에 가까워질 것입니다.
이해를 돕기 위해 이고, 여타 softmax값은 0.01인 극단적인 경우를 예로 들겠습니다.
이렇게 되면, 과 여타 다른 값의 기울기는 다음과 같이 계산됩니다.
위 계산 결과에서 알 수 있듯, 모든 입력에 대해 기울기가 0으로 수렴하게 됩니다.
즉, softmax가 큰 입력에 포화되어 기울기가 매우 작은 영역으로 몰리게 됩니다
입력값의 스케일이 크면 왜 Softmax의 기울기가 작은 영역으로 몰리는가?
그 이유는 지수함수의 성질 때문입니다.
지수 함수는 값이 커질 수 록 그 결과가 폭발적으로 증가합니다.
이 때문에, 어느 값 하나라도 절댓값이 너무 큰 값이 들어온다면 다른 항목보다 그 차이가 너무나도 커지게 되며, 그 항목만 확률이 1에 수렴하고, 나머지는 0으로 수렴하게 됩니다.
이렇게 되면, softmax 함수 자체의 변화율은 극도로 낮아지게 됩니다. 한 값이 조금만 커져도 그 항목에 대한 신호만 자동으로 커지기 때문에 softmax 함수에서 변화하는 양이 작아지기 때문입니다.
따라서, 역전파 시 gradient가 0에 가까운 값이 전달되어 학습이 거의 일어나지 않게 됩니다.
해결 방안
따라서, softmax 함수를 활용할 때는 다음 2가지를 염두하여 사용합니다.
1. 입력 스케일 조정
입력값이 너무 큰 값을 가지지 않도록 하여 gradient 소실을 방지
2. Tempertature Sofmax
위와 같이 지수함수의 입력에 temperature에 해당하는 스케일링을 수행합니다.
- T > 1 : 분포가 더 부드러워짐 (기울기가 커짐, 학습 원활)
- 입력값의 절대값이 작아지는 효과 - T < 1 : 분포가 날카로워짐 (확률이 더 극단화됨)
- 입력값의 절대값을 키우는 효과
