오늘은 Plotly를 이용한 시각화를 연습했습니다. 2000~2022년 한국의 연령별 출산율 데이터를 이용해 히트맵과 막대차트를 시각화하는 과정을 포스팅하도록 하겠습니다.
모듈 임포트
- 데이터 분석과 시각화를 위해 필요한 모듈들을 불러옵니다.
pandas는 데이터 처리를,plotly는 인터랙티브한 그래프를 그리는 데 사용됩니다.
import pandas as pd
import cufflinks as cf
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
%matplotlib inline
from plotly.offline import download_plotlyjs, init_notebook_mode, plot
init_notebook_mode(connected=True)
cf.go_offline()전처리
- 데이터 분석을 위해 먼저 데이터를 적절히 전처리합니다. 이 과정에는 데이터 불러오기, 필요한 열 선택, 인덱스 설정 등이 포함됩니다. 이를 통해 데이터를 분석하기 좋은 형태로 만듭니다.
df = pd.read_excel('../data/2000이후_시군구_모의_연령별_출산율.xlsx', usecols='B:G')
df.head()| 시점 | 20-24세 | 25-29세 | 30-34세 | 35-39세 | 40-44세 | |
|---|---|---|---|---|---|---|
| 0 | 2022 | 4.1 | 24.0 | 73.5 | 44.1 | 8.0 |
| 1 | 2021 | 5.0 | 27.5 | 76.1 | 43.5 | 7.6 |
| 2 | 2020 | 6.2 | 30.6 | 78.9 | 42.3 | 7.1 |
| 3 | 2019 | 7.1 | 35.7 | 86.2 | 45.0 | 7.0 |
| 4 | 2018 | 8.2 | 41.0 | 91.4 | 46.1 | 6.4 |
df.set_index('시점', inplace=True)| 20-24세 | 25-29세 | 30-34세 | 35-39세 | 40-44세 | |
|---|---|---|---|---|---|
| 시점 | |||||
| 2022 | 4.1 | 24.0 | 73.5 | 44.1 | 8.0 |
| 2021 | 5.0 | 27.5 | 76.1 | 43.5 | 7.6 |
| 2020 | 6.2 | 30.6 | 78.9 | 42.3 | 7.1 |
| 2019 | 7.1 | 35.7 | 86.2 | 45.0 | 7.0 |
| 2018 | 8.2 | 41.0 | 91.4 | 46.1 | 6.4 |
| 2017 | 9.6 | 47.9 | 97.7 | 47.2 | 6.0 |
| 2016 | 11.5 | 56.4 | 110.1 | 48.7 | 5.9 |
| 2015 | 12.5 | 63.1 | 116.7 | 48.3 | 5.6 |
| 2014 | 13.1 | 63.4 | 113.8 | 43.2 | 5.2 |
| 2013 | 14.0 | 65.9 | 111.4 | 39.5 | 4.8 |
| 2012 | 16.0 | 77.4 | 121.9 | 39.0 | 4.9 |
| 2011 | 16.4 | 78.4 | 114.4 | 35.4 | 4.6 |
| 2010 | 16.5 | 79.7 | 112.4 | 32.6 | 4.1 |
| 2009 | 16.5 | 80.4 | 100.8 | 27.3 | 3.4 |
| 2008 | 18.2 | 85.6 | 101.5 | 26.5 | 3.2 |
| 2007 | 19.7 | 95.9 | 102.0 | 25.9 | 3.1 |
| 2006 | 17.8 | 89.9 | 90.0 | 21.5 | 2.7 |
| 2005 | 18.0 | 92.1 | 82.1 | 19.0 | 2.5 |
| 2004 | 20.8 | 105.0 | 83.7 | 18.6 | 2.6 |
| 2003 | 23.9 | 112.2 | 79.7 | 17.4 | 2.6 |
| 2002 | 26.8 | 111.4 | 75.0 | 16.9 | 2.5 |
| 2001 | 31.7 | 129.8 | 78.1 | 17.3 | 2.6 |
| 2000 | 39.2 | 150.3 | 84.1 | 17.6 | 2.7 |
df.info()<class 'pandas.core.frame.DataFrame'>
Index: 23 entries, 2022 to 2000
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 20-24세 23 non-null float64
1 25-29세 23 non-null float64
2 30-34세 23 non-null float64
3 35-39세 23 non-null float64
4 40-44세 23 non-null float64
dtypes: float64(5)
memory usage: 1.1 KBdf.columnsIndex(['20-24세', '25-29세', '30-34세', '35-39세', '40-44세'], dtype='object')df = df[['20-24세', '25-29세', '30-34세', '35-39세']]| 20-24세 | 25-29세 | 30-34세 | 35-39세 | |
|---|---|---|---|---|
| 시점 | ||||
| 2022 | 4.1 | 24.0 | 73.5 | 44.1 |
| 2021 | 5.0 | 27.5 | 76.1 | 43.5 |
| 2020 | 6.2 | 30.6 | 78.9 | 42.3 |
| 2019 | 7.1 | 35.7 | 86.2 | 45.0 |
| 2018 | 8.2 | 41.0 | 91.4 | 46.1 |
| 2017 | 9.6 | 47.9 | 97.7 | 47.2 |
| 2016 | 11.5 | 56.4 | 110.1 | 48.7 |
| 2015 | 12.5 | 63.1 | 116.7 | 48.3 |
| 2014 | 13.1 | 63.4 | 113.8 | 43.2 |
| 2013 | 14.0 | 65.9 | 111.4 | 39.5 |
| 2012 | 16.0 | 77.4 | 121.9 | 39.0 |
| 2011 | 16.4 | 78.4 | 114.4 | 35.4 |
| 2010 | 16.5 | 79.7 | 112.4 | 32.6 |
| 2009 | 16.5 | 80.4 | 100.8 | 27.3 |
| 2008 | 18.2 | 85.6 | 101.5 | 26.5 |
| 2007 | 19.7 | 95.9 | 102.0 | 25.9 |
| 2006 | 17.8 | 89.9 | 90.0 | 21.5 |
| 2005 | 18.0 | 92.1 | 82.1 | 19.0 |
| 2004 | 20.8 | 105.0 | 83.7 | 18.6 |
| 2003 | 23.9 | 112.2 | 79.7 | 17.4 |
| 2002 | 26.8 | 111.4 | 75.0 | 16.9 |
| 2001 | 31.7 | 129.8 | 78.1 | 17.3 |
| 2000 | 39.2 | 150.3 | 84.1 | 17.6 |
데이터를 살펴보면 2000년부터 2022년까지 모의 연령별 출산율을 나타낸 자료입니다. 단위는 해당연령 여자인구 1천명당 출생아수입니다.
시각화
전처리를 마친 데이터를 Plotly를 사용해 히트맵과 막대 그래프로 시각화합니다. 이 과정에서 plotly.subplots.make_subplots 함수를 사용해 여러 개의 그래프를 하나의 플롯에 통합합니다. 이렇게 함으로써, 데이터의 다양한 측면을 한 눈에 볼 수 있습니다.
첫 번째 그래프는 연도별, 연령대별 출생아 수를 나타내는 히트맵입니다. 이 히트맵은 연도와 연령대에 따른 출산율의 변화를 직관적으로 보여줍니다. 히트맵의 색상은 출생아 수의 많고 적음을 나타내며, 연령대별 출산율의 변화와 경향을 쉽게 파악할 수 있게 해줍니다.
두 번째 그래프는 연도별 출생아 수를 나타내는 막대 그래프입니다. 이 그래프는 시간이 지남에 따라 출생아 수가 어떻게 변화하는지 보여줍니다. 각 막대는 특정 연도의 출생아 수를 나타내며, 시간에 따른 추세를 한눈에 파악할 수 있게 합니다.
마지막으로, 세 번째 그래프는 연령대별 출생아 수를 나타내는 수평 막대 그래프입니다. 이 그래프는 다양한 연령대에서 출생아 수가 어떻게 분포하는지 보여줍니다. 수평 막대 그래프를 통해 각 연령대의 출산율을 쉽게 비교하고 이해할 수 있습니다.
이러한 시각화를 통해, 연도별 및 연령대별 출산율의 중요한 인사이트를 얻을 수 있으며, 데이터에 숨겨진 패턴과 경향을 더 명확하게 파악할 수 있습니다.
# make_subplots를 사용하여 서브플롯 레이아웃 생성
# 여기서는 2x2 그리드를 설정합니다. 이를 통해 서로 다른 유형의 그래프를 함께 표시할 수 있습니다.
fig = make_subplots(
rows=2, cols=2,
shared_xaxes=True, # x축을 서로 공유합니다.
shared_yaxes=True, # y축을 서로 공유합니다.
vertical_spacing=0.02, # 세로 간격을 설정합니다.
horizontal_spacing=0.02, # 가로 간격을 설정합니다.
column_widths=[0.7, 0.3], # 열 너비 조정
row_heights=[0.3, 0.7] # 행 높이 조정
)
# 히트맵 추가
# 여기서는 연도별, 연령대별 출생아 수를 히트맵으로 표시합니다.
fig.add_trace(
go.Heatmap(
x=df.index,
y=df.columns,
z=df.values.T,
colorscale='Viridis',
),
row=2, col=1
)
# X축 방향 바 차트 추가
# 여기서는 각 연도별 출생아 수의 합계를 바 차트로 표시합니다.
fig.add_trace(
go.Bar(x=df.index, # x축에는 연도를 표시합니다.
y=df.sum(axis=1), # x축에는 연도를 표시합니다.
marker=dict(color='blue'),
name='연도별 출생아수',
),
row=1, col=1
)
# Y축 방향 바 차트 추가
# 여기서는 각 연령대별 출생아 수의 합계를 수평 바 차트로 표시합니다.
fig.add_trace(
go.Bar(
x=df.sum(), # x축에는 각 연령대의 출생아 수 합계를 표시합니다.
y=df.columns, # y축에는 연령대를 표시합니다.
orientation='h', # 바의 방향을 수평으로 설정합니다.
marker=dict(color='red'),
name='연령대별 출생아수'
),
row=2, col=2
)
# 레이아웃 조정
# 최종적으로 레이아웃을 조정하여 그래프의 제목, 크기, 범례 표시 여부를 설정합니다.
fig.update_layout(
height=800,
width=800,
title_text="2000년 이후 모 연령별 출산율",
title_font_size=20,
showlegend=False # 범례를 표시하지 않습니다.
)
fig.show()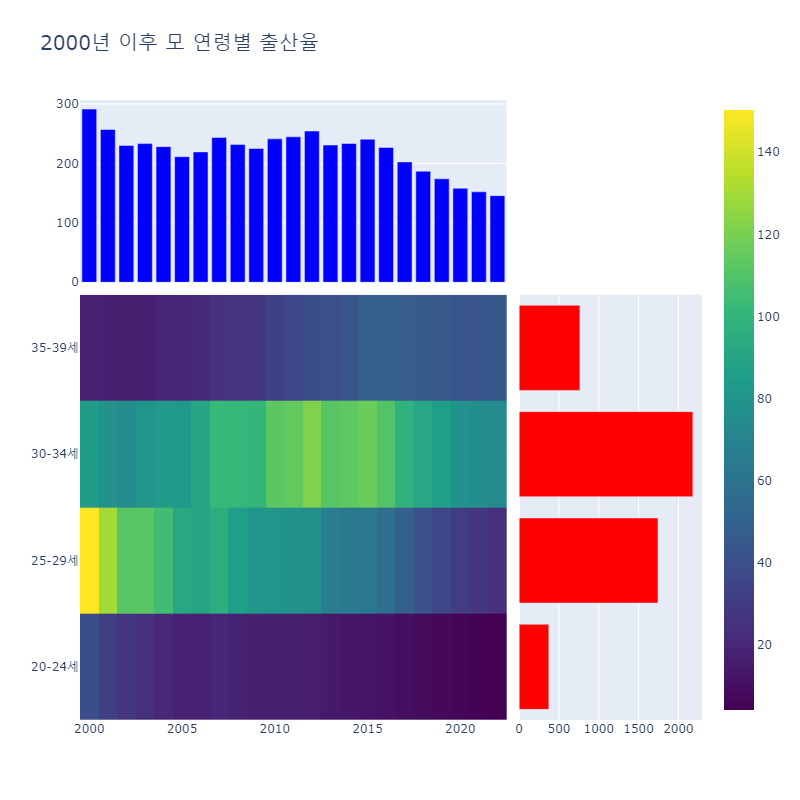
상단의 막대 그래프는 연도별 모 연령 20~39세의 출생아 수 합계를 나타냅니다. 시간이 흐름에 따라 출생아가 감소하는 모습이 보이고, 특히 최근의 감소폭이 심한 것을 확인할 수 있습니다.
우측의 막대그래프는 분석기간 동안의 연령대별 출생아 수 합계를 나타나냅니다. 20대에 비해 30대의 출생아수가 더 많습니다.
히트맵을 확인하면 25-29세 연령대의 출생아수가 시간이 흐름에 따라 큰 폭으로 감소하고 있습니다. 30-34세 구간은 2010년 중반 일시적으로 증가하다가 다시 감소하고 있습니다. 특이하게도 35-39세 구간은 출생아수가 늘어났습니다. 전반적으로 산모의 출산연령이 높아지고 있음을 확인할 수 있습니다.
정리
다양한 시각화 기법을 연습하고 있습니다. 데이터에 맞게 커스터마이징하는 과정이 쉽지 않습니다. 시각화를 위한 전처리 과정에도 시간이 적잖이 소요됩니다.
앞으로는 이러한 시각화 기법을 더욱 숙달하여, 데이터를 보다 명확하고 직관적으로 표현하는 데 집중할 계획입니다. 최종 목표는 데이터의 전반적인 경향을 한눈에 파악할 수 있는 대시보드를 작성하는 것입니다. 이를 통해 데이터 분석의 효율성을 높이고, 보다 깊이 있는 인사이트를 제공할 수 있기를 기대합니다.
