웹 스크래핑을 통한 데이터 수집에 대해 공부하였고 그 연장선상에서 API를 이용해 데이터를 수집하고 저장하는 방법에 대해 공부하고 그 결과를 포스트로 정리하도록 하겠습니다. 포스트의 내용은 '제로베이스 데이터스쿨' 강의를 참고하여 일부 내용을 보완/수정하였습니다.
1. 들어가며
온라인 쇼핑 데이터는 시장 동향 분석, 소비자 행동 연구, 경쟁사 분석 등에 유용하게 사용될 수 있습니다. 이런 데이터를 효율적으로 수집하는 방법 중 하나로 네이버 쇼핑 API를 활용할 수 있습니다.
네이버 쇼핑 API를 사용하면 네이버 쇼핑에서 제공하는 상품 정보를 쉽게 가져올 수 있습니다. 이를 통해 특정 상품의 가격, 판매처, 상품 평점 등 다양한 정보를 수집할 수 있습니다. 이 글에서는 '몰스킨' 다이어리 상품 정보를 예로 들어 네이버 쇼핑 API를 사용하여 데이터를 수집하고 엑셀 파일로 저장하는 과정을 설명하겠습니다.
이 과정을 통해 어떻게 API를 활용하여 원하는 상품 정보를 자동으로 수집하고, 이를 체계적으로 정리하는 방법을 배울 수 있습니다. 또한, 수집된 데이터를 엑셀 파일로 저장함으로써 데이터를 보다 편리하게 분석하고 관리하는 방법에 대해서도 알아볼 것입니다.
2. 네이버 API 키 발급
데이터 수집을 위한 첫 번째 단계는 네이버 API 키를 발급받는 것입니다. 네이버 개발자 센터에서 API 사용 신청을 하고, 필요한 인증 정보인 클라이언트 ID와 클라이언트 시크릿을 받을 수 있습니다.
네이버 API 키 발급 과정은 여기에 자세히 설명되어 있습니다.
3. API 요청 및 응답 처리
네이버 쇼핑 API를 활용해 상품 정보를 수집하는 과정은 API 요청을 보내고 응답을 받아 처리하는 것으로 시작됩니다. 이를 위해 Python의 urllib.request 모듈을 사용하여 네이버 API 서버로 HTTP 요청을 보낼 수 있습니다. 요청을 보낼 때는 이전 단계에서 발급받은 클라이언트 ID와 클라이언트 시크릿을 헤더에 포함시켜야 합니다.
다음은 네이버 쇼핑 API에 '몰스킨'이라는 키워드로 상품 검색을 요청하고, 응답을 받는 예제 코드입니다:
import urllib.request
# 발급받은 클라이언트 ID와 시크릿
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"
# 검색 요청 URL
url = "https://openapi.naver.com/v1/search/shop.json?query=" + urllib.parse.quote("몰스킨")
# 요청 객체 생성
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id", client_id)
request.add_header("X-Naver-Client-Secret", client_secret)
# API 요청 및 응답 받기
response = urllib.request.urlopen(request)
rescode = response.getcode()
# 응답 코드가 200이면 정상 응답
if rescode == 200:
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)이 코드는 '몰스킨'에 대한 검색 결과를 요청하고, 네이버 API 서버로부터 받은 응답을 출력합니다. 응답은 JSON 형식으로 반환되며, 이 데이터에는 검색된 상품들의 정보가 포함되어 있습니다.
API 응답을 받은 후에는 이 데이터를 파싱하고 필요한 정보를 추출하는 과정이 이어집니다. 이 과정에서 얻은 데이터는 이후 단계에서 상세하게 분석하고 처리할 예정입니다.
4. URL 생성 함수
네이버 쇼핑 API를 통해 특정 조건에 맞는 데이터를 수집하기 위해서는 검색 조건에 부합하는 URL을 생성하는 기능이 필요합니다. 이를 위해 gen_search_url이라는 함수를 정의하겠습니다. 이 함수는 검색어, 검색 시작 위치, 표시할 결과의 수, 정렬 방식 등의 인자를 받아 해당하는 API 요청 URL을 생성합니다.
gen_search_url 함수는 검색어(search_text)와 함께 여러 선택적 인자들을 받을 수 있도록 설계되었습니다. 이 함수는 기본적으로 네이버 쇼핑 API의 'shop' 노드에 대한 검색을 수행하며, 정렬 방식에는 'asc'(오름차순) 또는 'dsc'(내림차순)을 지정할 수 있습니다.
다음은 gen_search_url 함수의 예제 구현입니다:
import urllib.parse
def gen_search_url(search_text, **kwargs):
api_node = kwargs.get("api_node", 'shop')
start_num = kwargs.get("start_num", 1)
disp_num = kwargs.get("disp_num", 40)
sorting = kwargs.get("sorting", None)
valid_sortings = ['asc', 'dsc']
base = 'https://openapi.naver.com/v1/search'
node = '/' + api_node + '.json'
param_query = '?query=' + urllib.parse.quote(search_text)
param_start = '&start=' + str(start_num)
param_disp = '&display=' + str(disp_num)
url = base + node + param_query + param_start + param_disp
if sorting is not None:
if sorting in valid_sortings:
param_sort = '&sort=' + sorting
url += param_sort
else:
raise ValueError("Invalid sorting value. Choose from 'asc' or 'dsc'.")
return url
이 함수는 검색어와 함께 다양한 검색 옵션을 유연하게 조정할 수 있게 해줍니다. 생성된 URL은 네이버 쇼핑 API에 요청을 보내는 데 사용됩니다.
5. API 요청 및 JSON 데이터 수집
생성된 URL을 통해 JSON 형식의 데이터를 얻어올 수 있습니다. 이를 위해 urllib.request 모듈을 사용하여 네이버 API 서버로 HTTP 요청을 보내고, 응답을 받습니다. 요청을 보낼 때는 발급받은 클라이언트 ID와 클라이언트 시크릿을 헤더에 포함시켜야 합니다.
다음은 get_result_onpage라는 함수를 통해 API 요청을 보내고 JSON 형식으로 응답을 받는 과정을 구현한 예제입니다:
import urllib.request
import json
import datetime
def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id", client_id)
request.add_header("X-Naver-Client-Secret", client_secret)
response = urllib.request.urlopen(request)
print('[%s] Url Request Success' % datetime.datetime.now())
return json.loads(response.read().decode('utf-8'))
이 함수는 주어진 URL을 통해 네이버 쇼핑 API에 요청을 보내고, 성공적으로 응답을 받으면 현재 시각과 함께 성공 메시지를 출력합니다. 반환된 JSON 데이터는 상품에 대한 다양한 정보를 포함하고 있으며, 이 정보는 추후 데이터 추출 및 정제 과정에서 사용됩니다.
6. 데이터 추출 및 정제
네이버 쇼핑 API의 응답은 다양한 상품 정보를 포함한 JSON 형식으로 반환됩니다. 검색 결과에는 다양한 카테고리의 상품이 포함될 수 있습니다. 여기서 예제로 사용하고 있는 '몰스킨'의 경우에도, '다이어리', '노트'가 아닌 다른 카테고리의 상품이 포함되어 있습니다.
{'title': '올젠 남성 <b>몰스킨</b> 스판 바지 ZOC3PP1312',
'link': 'https://search.shopping.naver.com/gate.nhn?id=42934495004',
'image': 'https://shopping-phinf.pstatic.net/main_4293449/42934495004.20231015070059.jpg',
'lprice': '34790',
'hprice': '',
'mallName': '네이버',
'productId': '42934495004',
'productType': '1',
'brand': '',
'maker': '',
'category1': '패션의류',
'category2': '남성의류',
'category3': '바지',
'category4': ''}검색결과를 이용해 어떤 카테고리의 상품들이 포함되어 있는지 확인해 보겠습니다.
category_list = [each['category2'] for each in json_result['items']]
set(category_list)출력결과를 확인해 보면 2종류입니다.
{'남성의류', '문구/사무용품'}검색결과 중, '문구/사무용품'만 추출하도록 합니다. 또, 검색 결과에서 제목, 링크, 가격, 판매처 등 필요한 정보만을 추출하여 사용하기 위해 get_fields 함수를 구현합니다.
get_fields 함수는 JSON 데이터와 함께 선택적으로 특정 카테고리를 필터링하는 인자를 받습니다. 이를 통해 특정 카테고리에 해당하는 상품 정보만을 추출할 수 있습니다. 또한, 상품 제목에서 HTML 태그를 제거하기 위한 delete_tag 함수도 구현합니다.
다음은 get_fields 함수와 delete_tag 함수의 예제 구현입니다:
def delete_tag(input_str):
input_str = input_str.replace('<b>', '')
input_str = input_str.replace('</b>', '')
return input_str
def get_fields(json_data, **kwargs):
category = kwargs.get('category', None)
# 원하는 카테고리에 따라 상품 정보 필터링
filtered_items = json_data['items'] if category is None else [item for item in json_data['items'] if item['category2'] == category]
# 필요한 정보 추출
title = [delete_tag(each['title']) for each in filtered_items]
link = [each['link'] for each in filtered_items]
price = [each['lprice'] for each in filtered_items]
mall_name = [each['mallName'] for each in filtered_items]
# 추출된 정보를 DataFrame으로 정리
result_pd = pd.DataFrame({
'title': title,
'link': link,
'price': price,
'mall': mall_name
}, columns=['title', 'price', 'link', 'mall'])
return result_pd이 함수는 주어진 JSON 데이터에서 필요한 정보를 추출하고, HTML 태그가 제거된 깔끔한 텍스트 형태로 데이터를 정리합니다. 필터링 기능을 통해 특정 카테고리에 속하는 상품 정보만을 선택적으로 추출할 수 있습니다.
7. '몰스킨' 검색 및 결과 처리
이제 앞서 정의한 함수들을 활용하여 실제 데이터 수집 및 처리 과정을 진행해 보겠습니다. '몰스킨'이라는 키워드를 사용하여 네이버 쇼핑 API로부터 데이터를 수집하고, 이를 '문구/사무용품' 카테고리로 필터링하여 가격이 낮은 순으로 정렬해 보겠습니다.
먼저, gen_search_url 함수를 사용하여 '몰스킨'에 대한 검색 URL을 생성합니다. 여기서는 시작 번호(start_num), 표시할 결과의 수(disp_num), 정렬 방식(sorting)을 지정하여 URL을 생성합니다. 다음으로, get_result_onpage 함수를 사용하여 생성된 URL을 통해 네이버 쇼핑 API에 요청을 보내고, 응답으로 받은 JSON 데이터를 수집합니다.
그 후, get_fields 함수를 통해 JSON 데이터에서 '문구/사무용품' 카테고리에 해당하는 상품 정보만 추출합니다. 이 과정을 반복하여 1000개의 상품 데이터를 수집합니다. 수집한 데이터는 Pandas DataFrame으로 변환되고, 인덱스를 재설정하여 깔끔하게 정리합니다. 또한, 'price' 필드는 숫자 형태로 형변환하여 분석에 용이하게 만듭니다.
if __name__ == "__main__":
result_mol = []
for n in range(1, 1000, 100):
url = gen_search_url('몰스킨', start_num=n, disp_num=100, sorting='asc')
json_result = get_result_onpage(url)
pd_result = get_fields(json_result, category='문구/사무용품')
result_mol.append(pd_result)
result_mol = pd.concat(result_mol)
result_mol.reset_index(drop=True, inplace=True)
result_mol['price'] = result_mol['price'].astype('float')8. 데이터 저장 및 엑셀 파일 작성
수집하고 정제한 데이터를 체계적으로 관리하고 분석하기 위해 ExcelWriter를 사용하여 데이터를 엑셀 파일로 저장할 수 있습니다. ExcelWriter를 사용하면 열 너비를 조정하거나 조건부 서식을 적용할 수 있습니다.
다음은 수집한 데이터를 엑셀 파일로 저장하는 과정을 구현한 예제입니다:
# 엑셀 파일로 저장
excel_file_path = 'naver_shopping_data.xlsx'
with pd.ExcelWriter(excel_file_path, engine='xlsxwriter') as writer:
result_mol.to_excel(writer, sheet_name='molskin_diary')
# 엑셀 파일 서식 설정
worksheet = writer.sheets['molskin_diary']
worksheet.set_column('A:A', 4)
worksheet.set_column('B:B', 60)
worksheet.set_column('C:C', 10)
worksheet.set_column('D:D', 10)
worksheet.set_column('E:E', 50)
worksheet.set_column('F:F', 10)
# 조건부 서식 적용
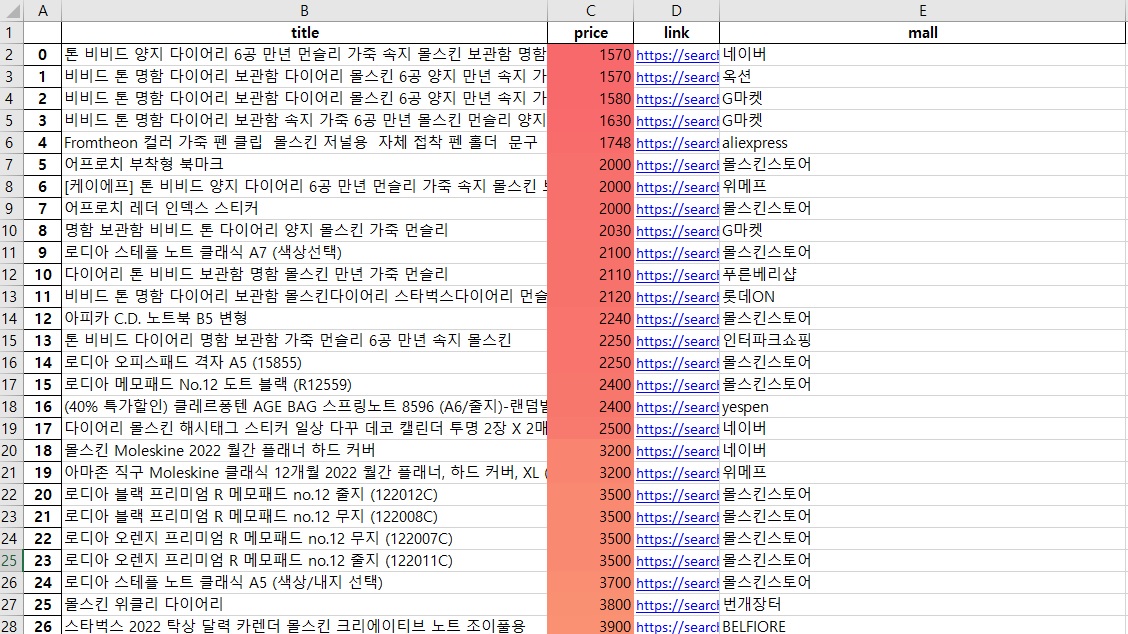
worksheet.conditional_format('C2:C1001', {'type': '3_color_scale'})8. 결과 저장 및 시각화
수집한 데이터를 정리한 후, result_mol라는 데이터 프레임을 'naver_shopping_data.xlsx' 파일로 저장했습니다. 엑셀 파일에서는 각 열의 너비를 조정하고, 'price' 열에 조건부 서식을 적용하여 데이터의 가독성을 높였습니다. 저장된 엑셀 파일을 열어보면, 상품들이 낮은 가격 순으로 정렬되어 있으며, 가격에 따라 'price' 열의 색상이 변하는 것을 확인할 수 있습니다.
이렇게 정리된 데이터를 기반으로 간단한 시각화도 진행했습니다. Seaborn 라이브러리의 countplot을 이용해 판매 상점별 상품 수를 시각화한 결과, yes24에서 제공하는 상품이 가장 많았으며, 이어서 '몰스킨스토어', '쿠팡', '네이버' 순으로 상품이 많은 것을 확인할 수 있습니다. 이런 시각화는 판매 분포에 대한 인사이트를 제공해줍니다.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(15, 6))
sns.countplot(
x='mall',
data=result_mol,
palette='RdYlGn',
order=result_mol['mall'].value_counts().index
)
plt.xticks(rotation=90)
plt.show()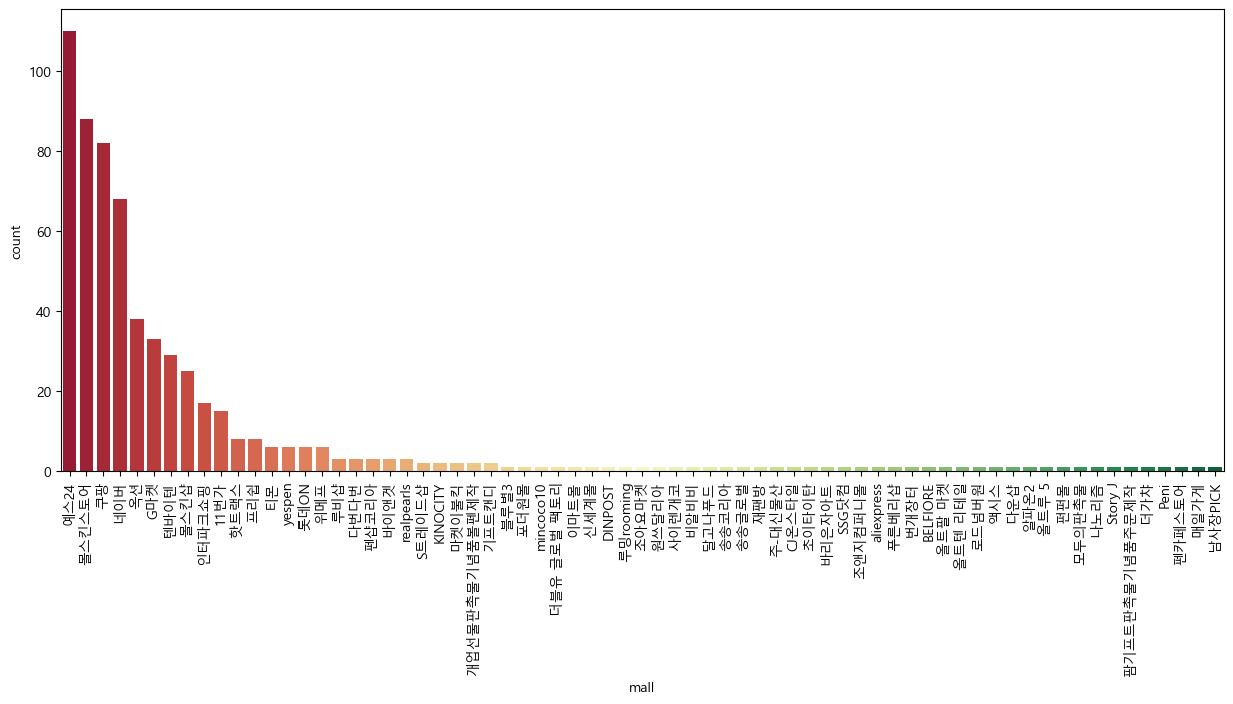
10개 이상의 상품을 판매하고 있는 상점들의 가격 분포를 확인하기 위해 boxplot을 그려보겠습니다. 먼저 10개 이상 판매하고 있는 상점들을 확인해서 마스킹합니다.
count_df = result_mol.pivot_table(index='mall', values='price', aggfunc='count')
count_df.rename(columns={'price': '상품집계'}, inplace=True)
count_df[count_df['상품집계']>10]| 상품집계 | |
|---|---|
| mall | |
| 11번가 | 15 |
| G마켓 | 33 |
| 네이버 | 68 |
| 몰스킨샵 | 25 |
| 몰스킨스토어 | 88 |
| 예스24 | 110 |
| 옥션 | 38 |
| 인터파크쇼핑 | 17 |
| 쿠팡 | 82 |
| 텐바이텐 | 29 |
more_than_10_list = count_df[count_df['상품집계']>10].index
filtered_shops = result_mol[result_mol['mall'].isin(more_than_10_list)]| title | price | link | mall | |
|---|---|---|---|---|
| 0 | 톤 비비드 양지 다이어리 6공 만년 먼슬리 가죽 속지 몰스킨 보관함 명함 | 1570.0 | https://search.shopping.naver.com/gate.nhn?id=... | 네이버 |
| 1 | 비비드 톤 명함 다이어리 보관함 다이어리 몰스킨 6공 양지 만년 속지 가죽 먼슬리 | 1570.0 | https://search.shopping.naver.com/gate.nhn?id=... | 옥션 |
| 2 | 비비드 톤 명함 다이어리 보관함 다이어리 몰스킨 6공 양지 만년 속지 가죽 먼슬리 | 1580.0 | https://search.shopping.naver.com/gate.nhn?id=... | G마켓 |
| 3 | 비비드 톤 명함 다이어리 보관함 속지 가죽 6공 만년 몰스킨 먼슬리 양지 | 1630.0 | https://search.shopping.naver.com/gate.nhn?id=... | G마켓 |
| 5 | 어프로치 부착형 북마크 | 2000.0 | https://search.shopping.naver.com/gate.nhn?id=... | 몰스킨스토어 |
| ... | ... | ... | ... | ... |
| 604 | 미도리 MD노트 라이트 L (3권세트) | 12600.0 | https://search.shopping.naver.com/gate.nhn?id=... | 몰스킨스토어 |
| 605 | 미도리 트래블러스 노트 리필 (프리주간+메모다이어리) | 12600.0 | https://search.shopping.naver.com/gate.nhn?id=... | 몰스킨스토어 |
| 606 | 미도리 트래블러스 노트 리필 (프리주간다이어리) | 12600.0 | https://search.shopping.naver.com/gate.nhn?id=... | 몰스킨스토어 |
| 608 | 1000523357 영어판 Moleskine Moleskine 2021 Monthl... | 12780.0 | https://search.shopping.naver.com/gate.nhn?id=... | 인터파크쇼핑 |
| 609 | 미도리 2024 MD 캘린더 트윈 | 12800.0 | https://search.shopping.naver.com/gate.nhn?id=... | 몰스킨스토어 |
505 rows × 4 columns
filtered_shops 데이터 프레임을 이용해 boxplot을 그릴 수 있습니다.
plt.figure(figsize=(15, 6))
sns.boxplot(
data=filtered_shops,
x='mall',
y='price',
palette='RdYlGn')
plt.xticks(rotation=90)
plt.show()
