'제로베이스 데이터스쿨'의 첫번재 EDA 과제는 서울지역 스타벅스와 이디야 매장의 위치에 대한 분석이었습니다. 이번 포스트에서는 그 중에서 스타벅스의 매장정보를 웹 스크래핑하는 코드를 살펴보고 , 제가 공부한 내용을 정리해보겠습니다.
1. 들어가며
데이터 분석을 시작하기 전에, 먼저 분석할 데이터를 수집하는 것이 중요합니다. 이번 과제에서는 스타벅스 매장 정보를 직접 수집해야 했습니다. 그러나 스타벅스 공식 홈페이지에는 매장 정보가 일목요연하게 정리되어 있지 않기 때문에, 웹 스크래핑이 필요했습니다.
이번 과제에서는 selenium과 BeautifulSoup을 주로 사용했습니다. selenium은 웹 브라우저의 자동화를 돕고, BeautifulSoup은 HTML 문서에서 데이터를 추출하는 데 사용됩니다.
이 포스트에서는 fetch_starbucks라는 함수를 통해 어떻게 서울 지역의 스타벅스 매장 정보를 수집했는지, 그 과정을 단계별로 살펴보겠습니다. 이 함수는 스타벅스 홈페이지에 접속하여 서울 지역 매장의 이름, 주소, 위도, 경도 정보를 추출하고, 이를 데이터 프레임 형태로 저장합니다.
2. fetch_starbucks 함수 분석 - 웹사이트 접속
이제 fetch_starbucks 함수의 첫 부분을 살펴보며, 스타벅스 웹사이트에 어떻게 접속하는지 알아보겠습니다.
def fetch_starbucks():
starbucks_url = 'https://www.starbucks.co.kr/index.do'
ua = UserAgent()
user_agent = ua.chrome
options = webdriver.ChromeOptions()
options.add_argument(f'user-agent={user_agent}')
driver = webdriver.Chrome('./driver/chromedriver.exe', options=options)
driver.get(starbucks_url)
driver.maximize_window()
...이 코드의 핵심은 selenium 라이브러리를 사용하여 웹 브라우저를 제어하는 것입니다. 먼저 스타벅스의 홈페이지 주소(starbucks_url)를 정의합니다. 이 주소는 나중에 브라우저를 통해 접속할 대상입니다.
UserAgent()를 이용해 사용자 에이전트를 생성합니다. 사용자 에이전트는 웹 브라우저가 서버에 자신을 어떻게 식별할지 결정하는 문자열입니다. 이를 통해 웹 스크래핑을 할 때 일반 브라우저 사용자처럼 보이도록 설정할 수 있습니다.
webdriver.ChromeOptions()는 크롬 브라우저를 실행할 때 다양한 옵션을 설정할 수 있게 해줍니다. 여기서는 앞서 만든 사용자 에이전트를 옵션에 추가합니다.
이후, webdriver.Chrome을 사용하여 크롬 브라우저를 실행하고, driver.get 메서드로 스타벅스 홈페이지에 접속합니다. driver.maximize_window()는 브라우저 창을 최대화하는 명령입니다. 이렇게 해서 웹사이트에 접속하는 첫 단계가 완료됩니다.
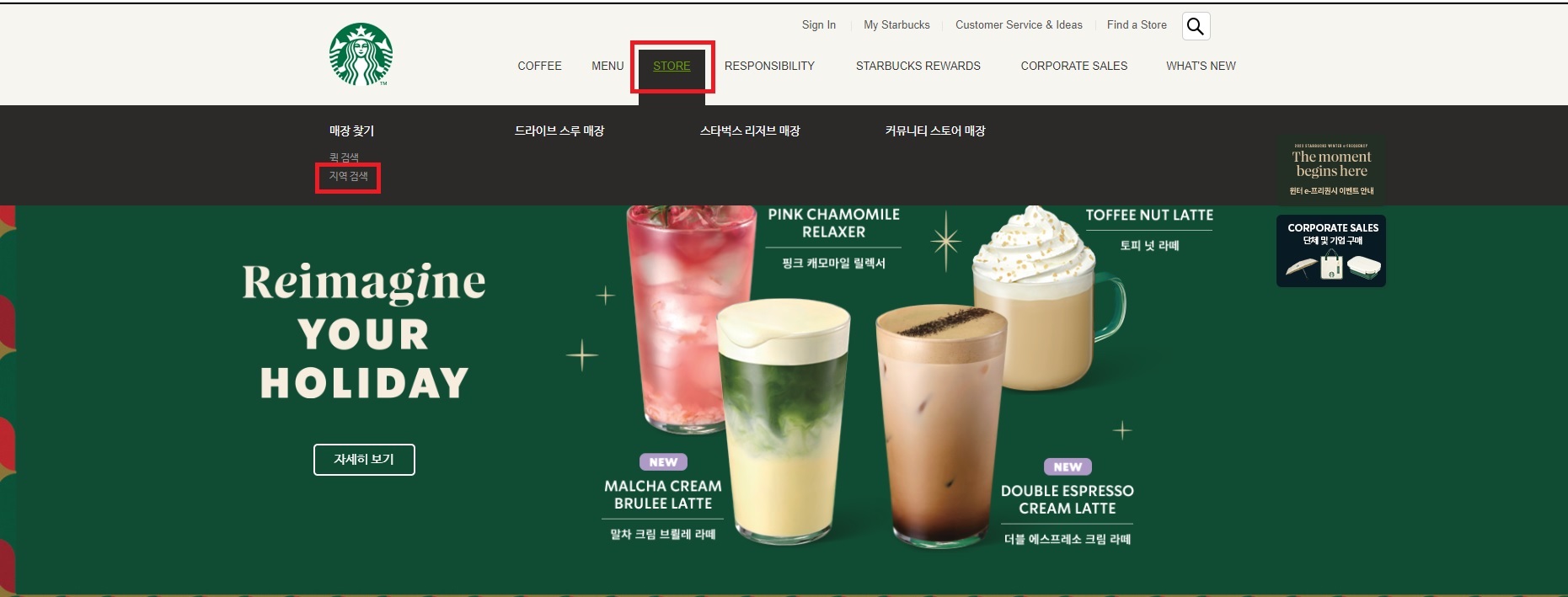
3. fetch_starbucks 함수 분석 - 매장 찾기
...
# 매장찾기 -> 지역검색
time.sleep(1)
action = ActionChains(driver)
first_tag = driver.find_element(By.CSS_SELECTOR, '#gnb > div > nav > div > ul > li.gnb_nav03')
second_tag = driver.find_element(By.CSS_SELECTOR, '#gnb > div > nav > div > ul > li.gnb_nav03 > div > div > div > ul:nth-child(1) > li:nth-child(3) > a')
action.move_to_element(first_tag).move_to_element(second_tag).click().perform()
...이 코드 부분은 스타벅스 웹사이트에서 매장 찾기 섹션으로 이동하는 작업을 자동화합니다. ActionChains는 selenium에서 제공하는 기능으로, 마우스를 움직이거나 클릭하는 등의 연속된 동작을 자동으로 수행할 수 있게 해줍니다.
먼저, time.sleep(1)은 코드 실행을 1초 동안 멈추게 하여 웹 페이지가 완전히 로드될 시간을 제공합니다. 그 후, ActionChains(driver)를 사용하여 브라우저에서의 연속된 동작을 시작합니다.
driver.find_element는 CSS 선택자를 사용하여 웹 페이지에서 특정 요소를 찾습니다. 여기서는 스타벅스 홈페이지의 메뉴에서 '매장 찾기' 섹션을 찾기 위해 두 개의 태그(first_tag와 second_tag)를 정의합니다. 이 태그들은 각각 화면 상단의 'STORE' 메뉴와 '지역 검색' 옵션을 나타냅니다.
마지막으로, action.move_to_element(first_tag)은 첫 번째 태그('STORE')로 마우스를 이동시킵니다. 그리고 move_to_element(second_tag).click().perform()은 두 번째 태그(지역 검색)로 이동하여 클릭합니다. 이렇게 하여 스타벅스 웹사이트에서 서울 지역의 매장 찾기 섹션으로 이동하는 자동화 과정을 완성합니다.
이 단계는 웹사이트 내에서 원하는 정보가 있는 부분으로 정확하게 이동하는 방법을 보여줍니다. 다음 항목에서는 이 매장 찾기 섹션에서 실제로 매장 정보를 어떻게 추출하는지 살펴보겠습니다.
4. fetch_starbucks 함수 분석 - 데이터 추출
함수의 다음 단계는 스타벅스 매장 정보를 웹 페이지에서 실제로 추출하는 과정입니다. 이를 위해 BeautifulSoup 라이브러리를 사용합니다.
...
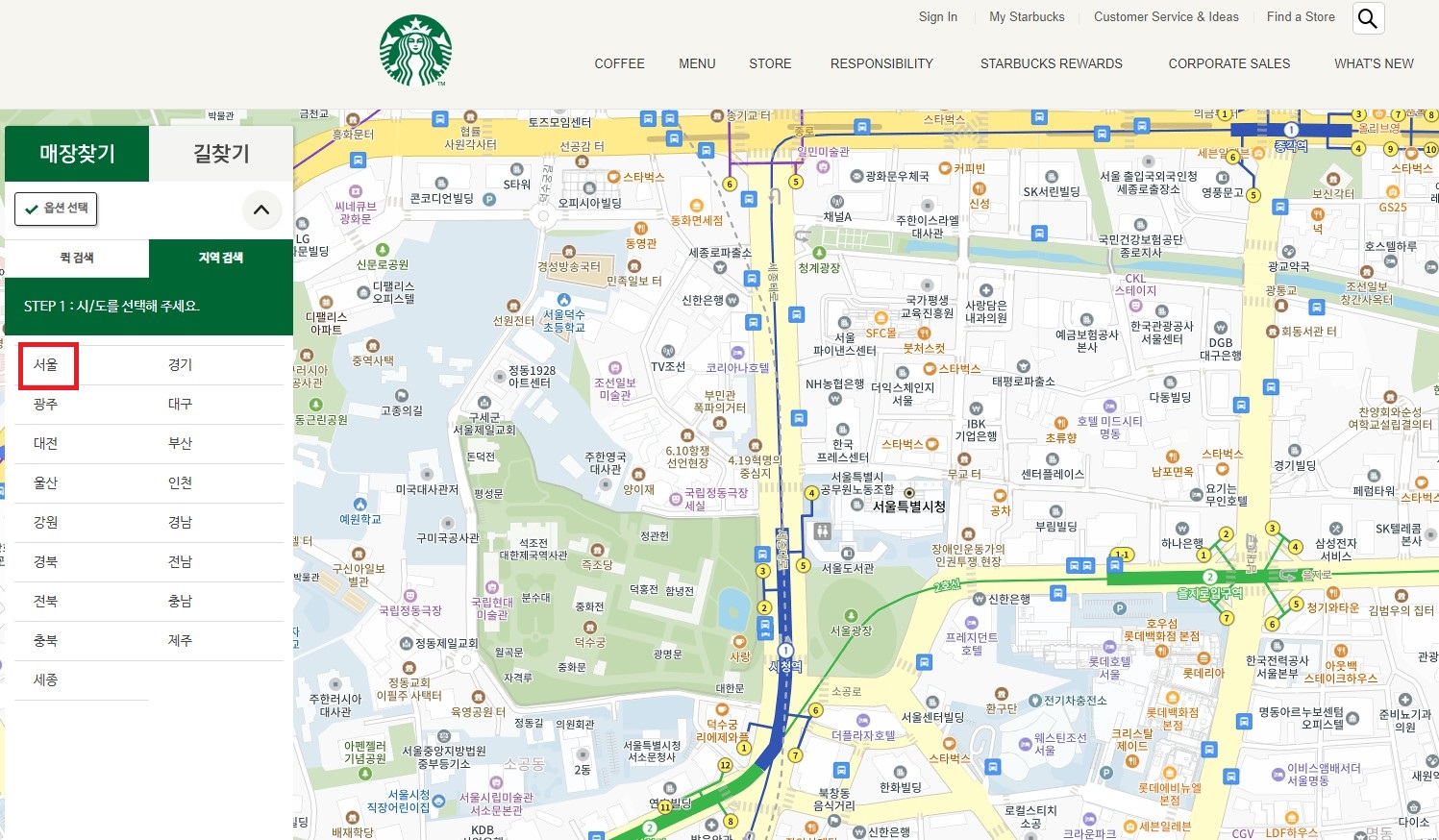
# 시도선택 - 서울
seoul_tag = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a')))
seoul_tag.click()
WebDriverWait(driver, 5).until(EC.presence_of_all_elements_located((By.CLASS_NAME, 'set_gugun_cd_btn')))
# 매장정보를 담기 위한 빈 리스트
store_list = []
addr_list = []
lat_list = []
lng_list = []
# 서울시 - 전체 선택
WebDriverWait(driver, 5).until(EC.presence_of_all_elements_located((By.CLASS_NAME, 'set_gugun_cd_btn')))
gu_elements = driver.find_elements(By.CLASS_NAME, 'set_gugun_cd_btn')
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.CSS_SELECTOR, f'#mCSB_2_container > ul > li:nth-child(1) > a')))
gu_elements[0].click()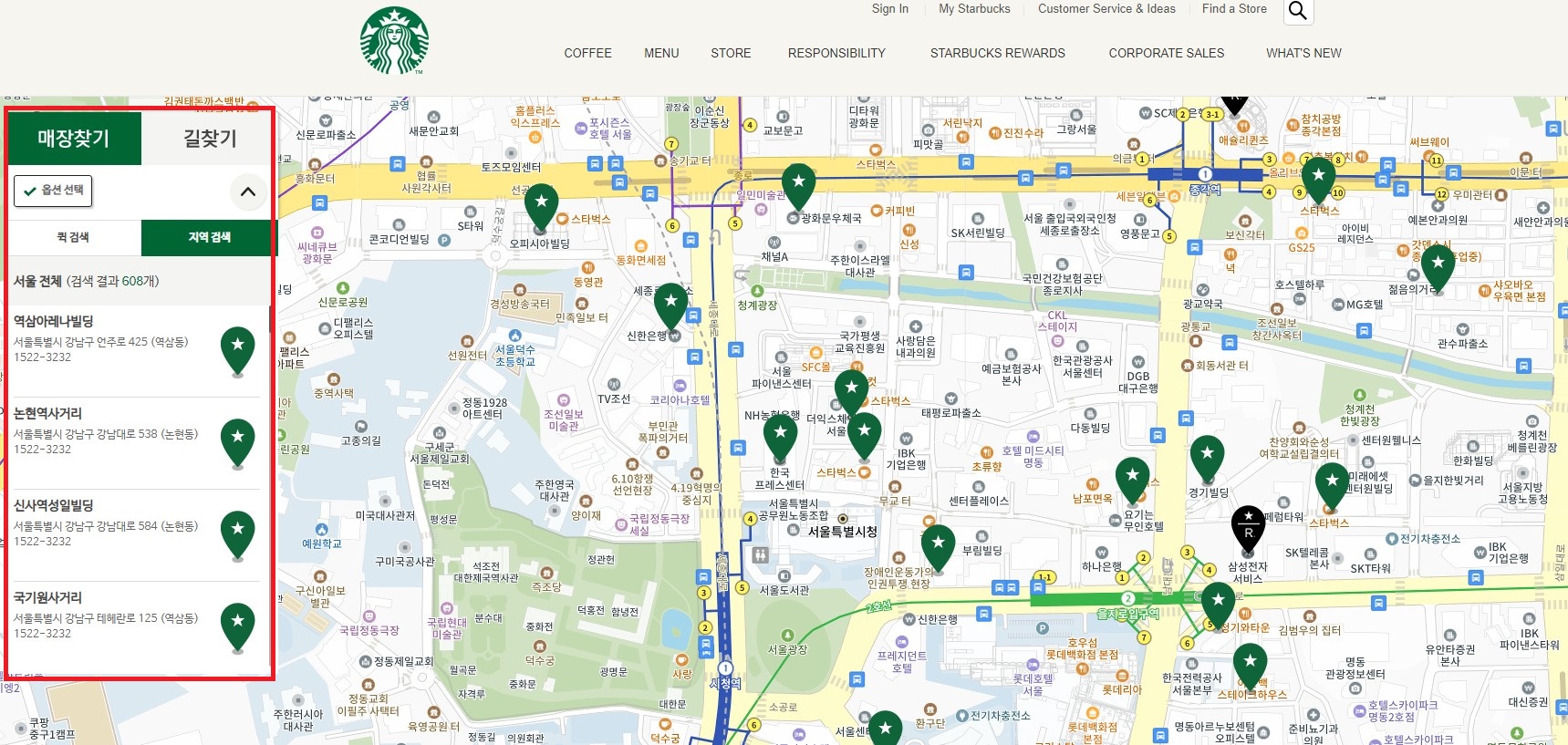
# 매장정보가 뜨기까지 대기
WebDriverWait(driver, 5).until(EC.presence_of_all_elements_located((By.CLASS_NAME, 'quickResultLstCon')))
# 뷰티풀숲을 이용해 스크래핑 하기
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
stores = soup.find('ul', 'quickSearchResultBoxSidoGugun').find_all('li')
# 매장이름, 주소, 위도, 경도
for store in stores:
store_name = store.find('strong').text
store_addr = store.find('p').text
store_lat = store['data-lat']
store_lng = store['data-long']
store_list.append(store_name)
addr_list.append(store_addr)
lat_list.append(store_lat)
lng_list.append(store_lng)
...먼저 WebDriverWait와 element_to_be_clickable을 사용해 서울 지역을 선택합니다. 이는 웹 페이지에서 특정 요소가 클릭 가능해질 때까지 기다리는 것을 의미합니다. 이후, 서울의 모든 구를 나타내는 '전체'(set_gugun_cd_btn)이 나타날 때까지 기다립니다.
다음으로 driver.page_source를 사용하여 현재 페이지의 HTML 소스를 가져옵니다. BeautifulSoup를 이용해 HTML을 파싱하고, 필요한 매장 정보를 포함하고 있는 li 태그를 찾습니다.
for 루프를 사용하여 각 매장의 이름, 주소, 위도, 경도 정보를 추출합니다. 이렇게 추출한 데이터는 미리 생성한 리스트(store_list, addr_list, lat_list, lng_list)에 각각 추가됩니다.
이 과정은 웹 페이지에서 원하는 데이터를 정확하게 추출하는 방법을 보여주며, 추출된 데이터를 구조화하는 방식을 설명합니다. 다음 항목에서는 이렇게 수집한 데이터를 pandas DataFrame으로 변환하는 과정을 살펴보겠습니다.
5. fetch_starbucks 함수 분석 - 데이터 정리 및 장점
fetch_starbucks 함수에서 스크래핑한 데이터를 데이터 프레임으로 정리하는 과정을 살펴보겠습니다.
...
# 수집한 정보를 데이터 프레임으로 변환
df = pd.DataFrame({
'store': store_list,
'addr': addr_list,
'lat': lat_list,
'lng': lng_list,
})
driver.quit()
return df
...함수의 이 부분에서는 store_list, addr_list, lat_list, lng_list라는 네 개의 리스트에 저장된 데이터를 데이터 프레임으로 변환합니다. pd.DataFrame 함수를 사용하여 이 리스트들을 데이터 프레임의 열로 지정합니다. 여기서 각 열은 각각 매장 이름, 주소, 위도, 경도를 나타냅니다.
selenium을 사용하기 위해 활성화한 브라우저를 종료하고 데이터 프레임으로 정리한 웹 스크래핑 결과를 반환합니다.
6. 결과 확인
함수의 전체 코드는 이렇습니다.
def fetch_starbucks():
starbucks_url = 'https://www.starbucks.co.kr/index.do'
ua = UserAgent()
user_agent = ua.chrome
options = webdriver.ChromeOptions()
options.add_argument(f'user-agent={user_agent}')
driver = webdriver.Chrome('./driver/chromedriver.exe', options=options)
driver.get(starbucks_url)
driver.maximize_window()
# 매장찾기 -> 지역검색
time.sleep(1)
action = ActionChains(driver)
first_tag = driver.find_element(By.CSS_SELECTOR, '#gnb > div > nav > div > ul > li.gnb_nav03')
second_tag = driver.find_element(By.CSS_SELECTOR, '#gnb > div > nav > div > ul > li.gnb_nav03 > div > div > div > ul:nth-child(1) > li:nth-child(3) > a')
action.move_to_element(first_tag).move_to_element(second_tag).click().perform()
# 시도선택 - 서울
seoul_tag = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a')))
seoul_tag.click()
WebDriverWait(driver, 5).until(EC.presence_of_all_elements_located((By.CLASS_NAME, 'set_gugun_cd_btn')))
# 매장정보를 담기 위한 빈 리스트
store_list = []
addr_list = []
lat_list = []
lng_list = []
# 서울시 - 전체 선택
WebDriverWait(driver, 5).until(EC.presence_of_all_elements_located((By.CLASS_NAME, 'set_gugun_cd_btn')))
gu_elements = driver.find_elements(By.CLASS_NAME, 'set_gugun_cd_btn')
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.CSS_SELECTOR, f'#mCSB_2_container > ul > li:nth-child(1) > a')))
gu_elements[0].click()
# 매장정보가 뜨기까지 대기
WebDriverWait(driver, 5).until(EC.presence_of_all_elements_located((By.CLASS_NAME, 'quickResultLstCon')))
# 뷰티풀숲을 이용해 스크래핑 하기
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
stores = soup.find('ul', 'quickSearchResultBoxSidoGugun').find_all('li')
# 매장이름, 주소, 위도, 경도
for store in stores:
store_name = store.find('strong').text
store_addr = store.find('p').text
store_lat = store['data-lat']
store_lng = store['data-long']
store_list.append(store_name)
addr_list.append(store_addr)
lat_list.append(store_lat)
lng_list.append(store_lng)
# 수집한 정보를 데이터 프레임으로 변환
df = pd.DataFrame({
'store': store_list,
'addr': addr_list,
'lat': lat_list,
'lng': lng_list,
})
driver.quit()
return df반환된 데이터 프레임을 확인해 보겠습니다.
| store | addr | lat | lng | |
|---|---|---|---|---|
| 0 | 역삼아레나빌딩 | 서울특별시 강남구 언주로 425 (역삼동)1522-3232 | 37.501087 | 127.043069 |
| 1 | 논현역사거리 | 서울특별시 강남구 강남대로 538 (논현동)1522-3232 | 37.510178 | 127.022223 |
| 2 | 신사역성일빌딩 | 서울특별시 강남구 강남대로 584 (논현동)1522-3232 | 37.5139309 | 127.0206057 |
| 3 | 국기원사거리 | 서울특별시 강남구 테헤란로 125 (역삼동)1522-3232 | 37.499517 | 127.031495 |
| 4 | 대치재경빌딩R | 서울특별시 강남구 남부순환로 2947 (대치동)1522-3232 | 37.494668 | 127.062583 |
| ... | ... | ... | ... | ... |
| 602 | 사가정역 | 서울특별시 중랑구 면목로 3101522-3232 | 37.579594 | 127.087966 |
| 603 | 상봉역 | 서울특별시 중랑구 망우로 307 (상봉동)1522-3232 | 37.59689 | 127.08647 |
| 604 | 묵동 | 서울특별시 중랑구 동일로 952 (묵동, 로프트원 태릉입구역) 1층1522-3232 | 37.615368 | 127.076633 |
| 605 | 양원역 | 서울특별시 중랑구 양원역로10길 3 (망우동)1522-3232 | 37.6066536267232 | 127.106359790053 |
| 606 | 중화역 | 서울특별시 중랑구 봉화산로 35 1522-3232 | 37.60170912407773 | 127.07841136432036 |
607 rows × 4 columns
서울시 전체 607개 매장의 정보가 수집되었습니다. 매장명, 주소, 위도, 경도 정보가 데이터 프레임으로 정리되었습니다.
7. 정리
이번 포스트를 통해 fetch_starbucks 함수의 각 단계를 살펴보며 스타벅스 서울 지역 매장 정보를 웹 스크래핑하는 과정을 자세히 분석해보았습니다. 이 함수는 웹사이트에 접속하여 필요한 데이터를 추출하고, 이를 구조화된 형태인 데이터 프레임으로 변환하는 과정을 포함합니다.
웹사이트에 접근하기 위해 selenium을 사용하는 방법, 특정 페이지 요소를 찾아 이동하는 방법, 그리고 BeautifulSoup을 이용하여 웹 페이지에서 원하는 데이터를 추출하는 방법을 배웠습니다. 또한, 추출된 데이터를 향후 데이터 분석에 활용하기 위해 데이터 프레임으로 변환하여 반환하도록 하였습니다.
별도의 포스트에서 이디야 매장 정보를 수집하는 부분, 수집한 스타벅스와 이디야 데이터를 활용해 시각화하고 분석하는 부분도 다루도록 하겠습니다.
