
1. 서두
이전 포스트에서는 서울 지역 스타벅스 매장 정보를 웹 스크래핑하는 과정을 자세히 살펴보았습니다. 오늘은 그 연장선상에서 이디야 커피 매장 정보를 수집하는 fetch_ediya 함수에 대해 알아보겠습니다. 이 함수는 이디야 커피 매장의 위치 정보를 효율적으로 수집하기 위해 작성되었으며, 스타벅스 매장 정보를 수집하는 과정과 유사하게 진행됩니다.
이번 포스트에서는 이디야 커피 웹사이트의 구조를 분석하고, 어떻게 이를 통해 매장 정보를 추출할 수 있는지 살펴보겠습니다. 특히 fetch_ediya 함수의 코드를 중심으로 그 구조와 작동 방식을 세부적으로 분석하겠습니다.
얻은 데이터는 추후 다양한 분석과 시각화를 통해 별도의 포스트를 작성하겠습니다.이제 이디야 커피 매장 정보를 수집하는 fetch_ediya 함수를 살펴보겠습니다.
2. 이디야 웹사이트 분석
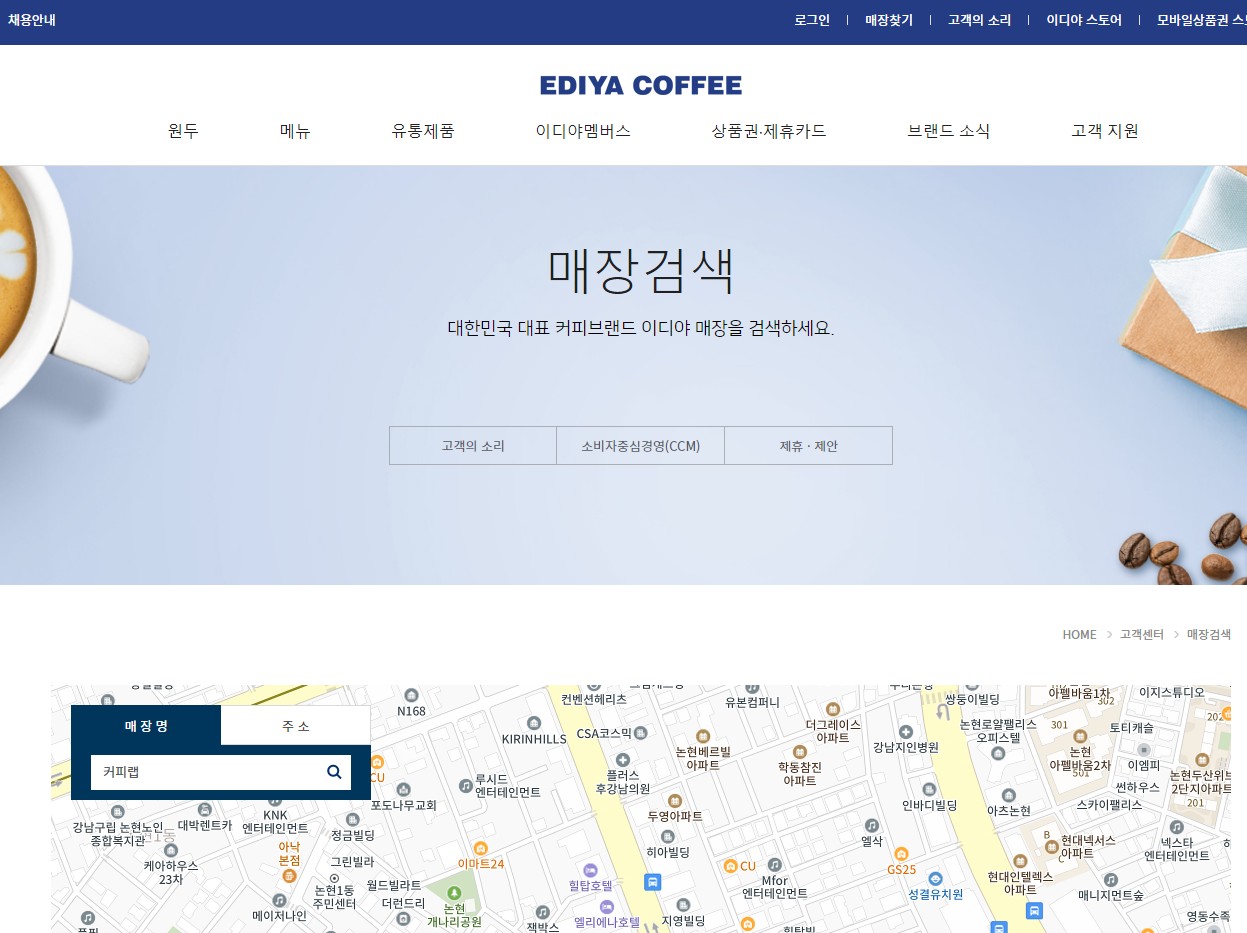
이디야 커피의 매장 정보를 수집하기 위해서는 홈페이지 상단의 '매장찾기' 메뉴를 통해 '매장 검색' 화면으로 진입해야 합니다. 매장 검색 화면에서 '주소' 탭을 선택하고, 여기에 서울시의 25개 구 이름을 하나씩 입력하면 해당 구에 위치한 이디야 매장 목록을 얻을 수 있습니다.
각 매장 목록은 주소와 함께 제공되며, 이 정보를 통해 스크래핑 과정에서 필요한 데이터를 추출할 수 있습니다. 매장 정보에는 이름, 주소, 연락처 등이 포함되어 있는데, 이를 적절히 추출하여 데이터베이스화하는 것이 목표입니다.

이디야 웹사이트의 구조는 매장 정보를 탐색하기 쉽게 잘 구성되어 있으며, 이를 통해 자동화된 스크래핑이 가능합니다. 다음 섹션에서는 이 웹사이트 구조를 기반으로 어떻게 fetch_ediya 함수를 작성하고 사용하는지에 대해 자세히 살펴보도록 하겠습니다.
3. fetch_ediya 함수 소개
fetch_ediya 함수는 이디야 매장 정보를 웹사이트에서 자동으로 스크래핑하는 데 사용됩니다. 이 함수는 주소 탭에서 서울시의 각 구를 검색하여 매장 리스트를 가져오는 방식으로 설계되었습니다. 함수의 주요 목적은 다음과 같습니다:
- 서울시 내에 있는 이디야 매장의 이름, 주소, 연락처 등의 정보를 수집합니다.
- 수집된 매장 정보는 데이터 프레임 형태로 정리되어, 추후 분석 및 시각화에 용이하도록 합니다.
- 매장 위치에 대한 데이터는 지리적 분석을 가능하게 하는 위도와 경도 정보를 포함할 수 있도록 합니다.
함수는 먼저 이디야 웹사이트에 접속하여 '매장찾기' 섹션으로 이동합니다. 이후, 사용자가 입력한 구 이름에 대응하는 매장 정보를 조회하고, BeautifulSoup과 같은 라이브러리를 사용하여 HTML 요소에서 필요한 데이터를 추출합니다.
이 과정에서 Selenium과 같은 웹 드라이버를 활용하여, 페이지에 동적으로 로드되는 매장 정보에 접근하고, 모든 필요한 정보가 수집될 때까지 페이지를 순회합니다. 마지막으로, 수집된 데이터는 후처리 과정을 거쳐 필요한 형태로 정제되고 저장됩니다.
4. 코드 리뷰
먼저 fetch_ediya 함수의 전체 코드를 살펴보겠습니다. 이 코드는 이디야 웹사이트에서 매장 정보를 스크래핑하고, 수집된 데이터를 데이터 프레임으로 변환하여 반환하는 작업을 자동화합니다.
def fetch_ediya(input_list):
ediya_url = 'https://ediya.com/'
ua = UserAgent()
user_agent = ua.chrome
options = webdriver.ChromeOptions()
options.add_argument(f'user-agent={user_agent}')
driver = webdriver.Chrome('./driver/chromedriver.exe', options=options)
driver.get(ediya_url)
driver.maximize_window()
# 매장찾기
time.sleep(1)
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.CSS_SELECTOR, 'body > header > div > div > div.gnb_wrap > div.top_util > ul.top_members > li.store > a'))).click()
# 주소탭
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a'))).click()
# 주소 입력창 선택
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#keyword'))).click()
# 매장정보를 담기 위한 빈 리스트
store_list = []
addr_list = []
lat_list = []
lng_list = []
# 주소 입력
for ele in tqdm(input_list):
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#keyword'))).click()
driver.find_element(By.CSS_SELECTOR, '#keyword').clear()
if ele == '중구':
driver.find_element(By.CSS_SELECTOR, '#keyword').send_keys('서울 ' + ele)
else:
driver.find_element(By.CSS_SELECTOR, '#keyword').send_keys(ele)
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#keyword_div > form > button'))).click()
# BeautifulSoup을 이용한 HTML 파싱
WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '#placesList > li')))
# 페이지가 갱신되었는지 확인
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#map > div:nth-child(1) > div > div:nth-child(6) > div:nth-child(1) > div > div > div.st_info_con > div.info_store_info > dl > dd:nth-child(1) > p')))
test_ele = driver.find_element(By.CSS_SELECTOR, '#map > div:nth-child(1) > div > div:nth-child(6) > div:nth-child(1) > div > div > div.st_info_con > div.info_store_info > dl > dd:nth-child(1) > p')
if test_ele.text == ele:
temp = driver.page_source
soup = BeautifulSoup(temp, 'html.parser')
stores = soup.find(id='placesList').find_all('li')
else:
time.sleep(2)
temp = driver.page_source
soup = BeautifulSoup(temp, 'html.parser')
stores = soup.find(id='placesList').find_all('li')
# 매장 정보 수집
for store in stores:
store_name = store.find('dl').find('dt').text
addr = store.find('dl').find('dd').text
map_raw = store.find('a').get('onclick')
pattern = re.compile(r"panLatTo\((.+?),(.+?),(.+?)\)")
if pattern.match(map_raw):
lng = pattern.match(map_raw).group(1)
lat = pattern.match(map_raw).group(2)
lng = lng.split("'")[1]
lng = float(lng)
lat = lat.split("'")[1]
lat = float(lat)
store_list.append(store_name)
addr_list.append(addr)
lat_list.append(lat)
lng_list.append(lng)
print(f'{ele} 수집 완료')
# 수집한 정보를 데이터 프레임으로 변환
df = pd.DataFrame({
'store': store_list,
'addr': addr_list,
'lat': lat_list,
'lng': lng_list,
})
driver.quit()
return df이제 주요 코드 블록을 하나씩 살펴보며, 각각이 어떤 역할을 하는지 설명하겠습니다.
-
웹 드라이버 초기화 및 웹사이트 접근:
driver = webdriver.Chrome('./driver/chromedriver.exe', options=options) driver.get(ediya_url)이 부분에서는 웹 드라이버를 초기화하고, 이디야 웹사이트로 이동합니다.
-
매장찾기 메뉴 클릭:
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.CSS_SELECTOR, '...'))).click()'매장찾기' 메뉴를 클릭하여 매장 검색 탭으로 이동합니다.
-
주소 탭 클릭 및 주소 입력:
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#keyword'))).click() driver.find_element(By.CSS_SELECTOR, '#keyword').clear() driver.find_element(By.CSS_SELECTOR, '#keyword').send_keys(ele)주소 탭을 클릭하고, 각 구 이름을 입력하여 매장 정보를 검색합니다.
-
매장 정보 수집:
for store in stores: store_name = store.find('dl').find('dt').text addr = store.find('dl').find('dd').text # ... store_list.append(store_name) addr_list.append(addr) lat_list.append(lat) lng_list.append(lng)검색된 매장 목록에서 매장 이름과 주소, 위치 정보를 추출하고 리스트에 저장합니다.
-
데이터 프레임 생성 및 반환:
df = pd.DataFrame({ 'store': store_list, 'addr': addr_list, 'lat': lat_list, 'lng': lng_list, })수집된 정보를 데이터 프레임으로 변환하여 작업의 최종 결과물로 반환합니다.
5. 마무리
이디야 커피 매장 정보를 스크래핑하는 과정을 fetch_ediya 함수와 함께 자세히 살펴보았습니다. 이 함수를 통해 우리는 서울시 내의 이디야 매장들에 대한 데이터를 수집하고, 이를 데이터 프레임으로 정리할 수 있었습니다. 이 데이터들을 활용해 분석한 내용들은 별도의 포스트로 작성하도록 하겠습니다.
