Data
- A set of samples
- (D={xi}i=1...N,D={(xi,yi)i=1...N})
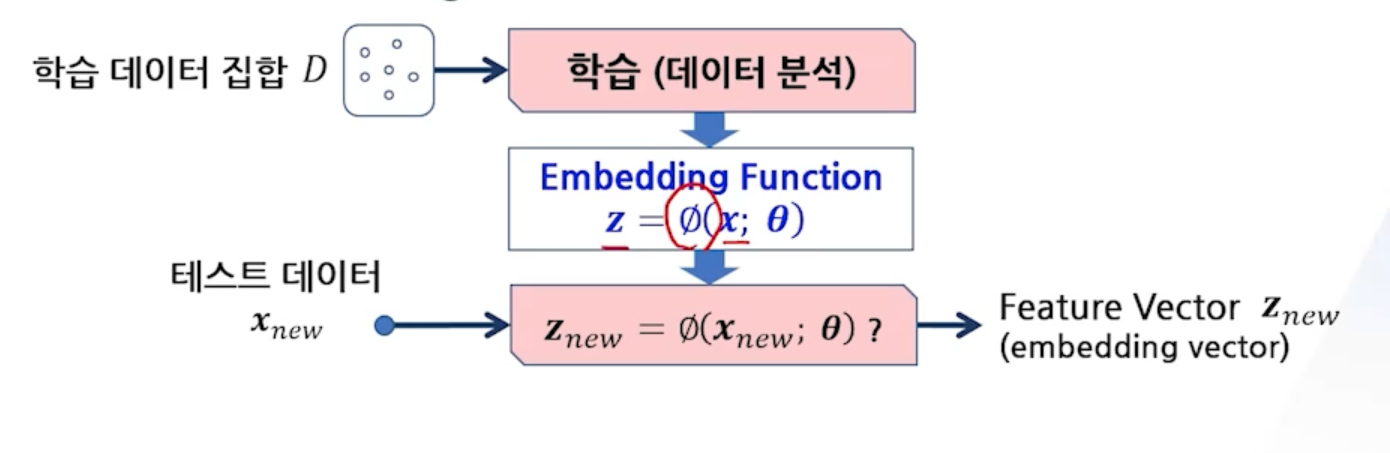
- Goal of Learning
- 분석에 필요한 정보만 추출 (구체적 분석 목적에 따라 달라짐)
A) 변환 함수의 종류
- y=ϕ(x)=WTx
- m차원 열벡터 x에 변환행렬 W(m×d)를 곱하여 d차원 특징을 획득
- 통계적 방법
- 특징벡터 y가 원하는 분포가 되도록 하는 W를 찾음
- 복잡한 비선형 함수 ϕ(x)를 이용하여 m차원 벡터를 d차원 벡터로 매핑
2. 선형변환에서의 특징 추출
A) 차원 축소 관점에서의 특징 추출
- m차원 데이터 x를 행렬 W(m×d)에 의해 d차원 특징 y로 매핑 (m>d)
⎣⎢⎢⎢⎢⎢⎢⎢⎡y1y2y3......yd⎦⎥⎥⎥⎥⎥⎥⎥⎤ = ⎣⎢⎢⎢⎢⎢⎢⎢⎡w1Txw2Txw3Tx......wdTx⎦⎥⎥⎥⎥⎥⎥⎥⎤ = ⎣⎢⎢⎢⎢⎢⎢⎢⎡w1Tw2Tw3T......wdT⎦⎥⎥⎥⎥⎥⎥⎥⎤x =
[w1,w2,w3,......wd] = WxT
B) 전체 데이터 집합 X에 대한 특징 추출
- X=[x1,x2.....xN] (m×N)행렬
- Y=[y1,y2.....yN] (d×N)행렬
Y=WTX=[Wx1T,Wx2T,WxNT]
즉, 선형변환 특징추출이란
주어진 데이터를 변환행렬 W에 의해 정해지는 방향으로 사영함으로 저차원의 특징값을 얻는 것
C) 선형 변환 방법
PCA (주성분 분석)
- 클래스 정보 미사용
- 차원을 축소할 때 손실되는 데이터를 최소화하는 것이 목표
LDA (선형판별분석)
- 클래스 정보 사용
- 분류가 잘 될 수 있도록 변환행렬을 만드는 것이 목표
3. PCA
목적
데이터의 공분산 행렬의 고유치와 고유벡터를 찾아,
고유치가 가장 큰 값부터 순서대로 이에 대응하는
d개의 고유벡터를 찾아서 행렬 W를 구성
수행 단계
1. 입력 데이터 집합 X의 평균과 공분산 계산
2. 고유치 분석을 통해 공분산의 고유치 행렬과 고유벡터 행렬을 계산
3. 고유치가 큰 것부터 순서대로 d개의 고유치를 선택
4. 선택한 고유치에 대응되는 고유벡터를 열벡터로 가지는 변환행렬 W를 생성
5. W 에 의한 선형변환으로 특징 데이터 Y를 얻음
