불균형 데이터 처리 기법 자세한 설명
불균형 데이터를 처리하는 방법에는 크게 언더샘플링(Under Sampling), 오버샘플링(Over Sampling), 그리고 합성 데이터 생성(SMOTE, ADASYN 등)이 있다.
각 기법의 특징과 장단점을 자세히 살펴보자.
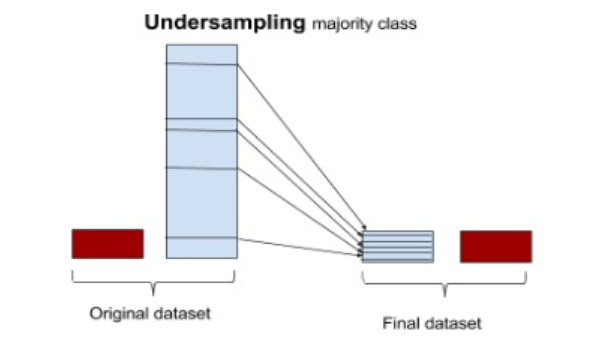
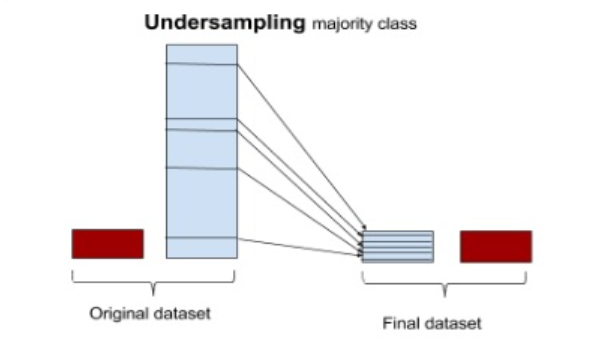
📌 1. 언더샘플링(Under Sampling)
💡 개념:
다수 클래스(majority class)의 데이터 수를 줄여서 소수 클래스(minority class)와 비율을 맞추는 기법이다.
📌 방법:
- 무작위 언더샘플링: 정상 데이터를 랜덤하게 선택하여 줄이는 방식
- 유의미한 정보 기반 샘플링: 데이터의 분포를 고려하여 대표적인 데이터만 남기는 방식
- NearMiss: 소수 클래스와 가장 가까운 다수 클래스 데이터만 남기는 방식
📌 장점:
✅ 데이터 중복이 없어서 과적합(overfitting) 위험이 낮음
✅ 샘플링 속도가 빠름
📌 단점:
❌ 정상 데이터가 많이 손실될 가능성이 있음
❌ 일부 중요한 데이터를 잃을 수도 있음
📌 Python 코드 예제:
from imblearn.under_sampling import NearMiss
# 언더샘플링 적용
X_under, y_under = NearMiss().fit_resample(X, y)
print(f"Before UnderSampling: {Counter(y)}")
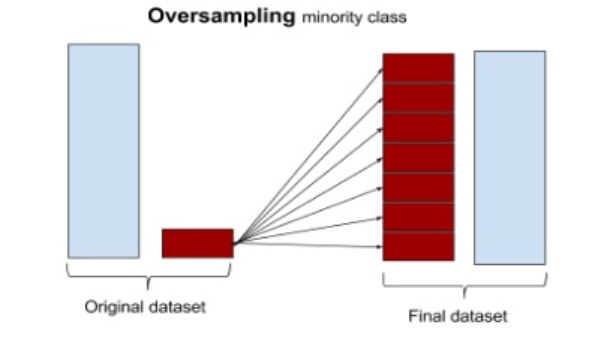
print(f"After UnderSampling: {Counter(y_under)}")📌 2. 오버샘플링(Over Sampling)
💡 개념:
소수 클래스(minority class)의 데이터를 늘려서 데이터 불균형을 해소하는 방법이다.
📌 방법:
- 무작위 오버샘플링: 소수 클래스를 단순 복제하여 데이터 개수를 증가
- 유의미한 샘플링: 특정 기준에 따라 소수 클래스를 복제
- 합성 데이터 생성: 기존 데이터를 기반으로 새로운 데이터를 생성 (SMOTE, ADASYN 등)
📌 장점:
✅ 데이터 손실 없이 소수 클래스를 보강할 수 있음
✅ 언더샘플링보다 정보 손실 위험이 적음
📌 단점:
❌ 단순 복제 방식은 과적합(overfitting) 위험이 높음
❌ 오버샘플링을 잘못하면 일부 샘플이 중복되어 모델 성능이 낮아질 수도 있음
📌 Python 코드 예제:
from imblearn.over_sampling import RandomOverSampler
# 오버샘플링 적용
X_over, y_over = RandomOverSampler().fit_resample(X, y)
print(f"Before OverSampling: {Counter(y)}")
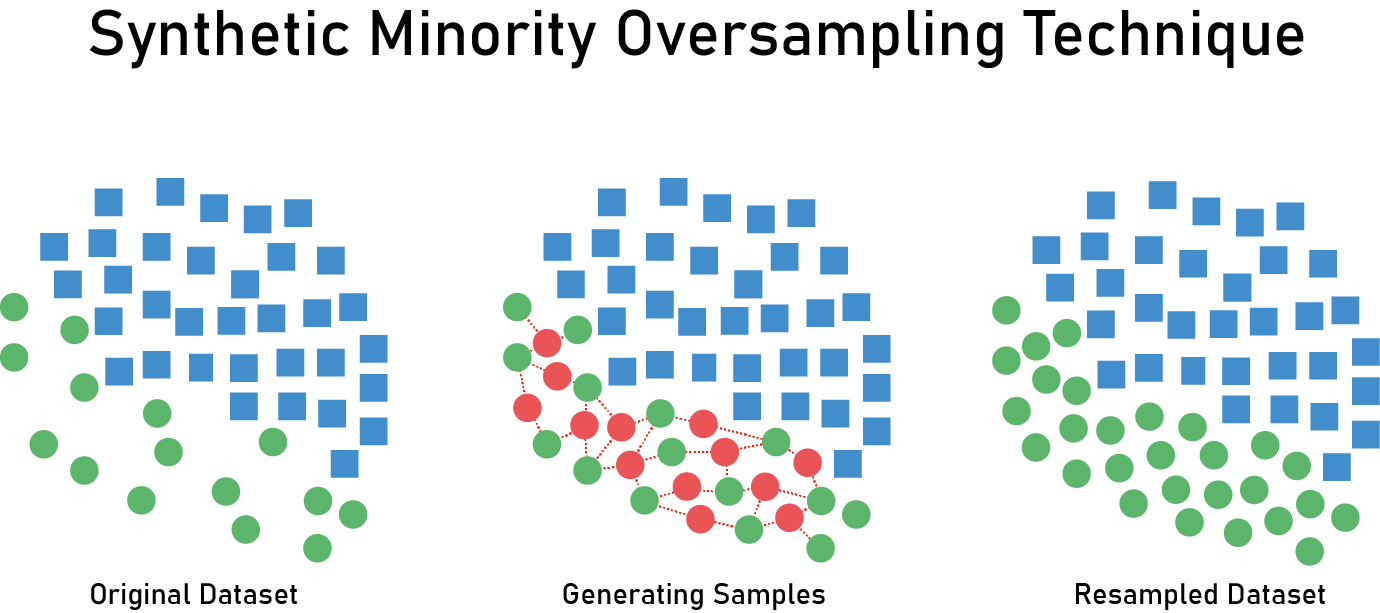
print(f"After OverSampling: {Counter(y_over)}")📌 3. SMOTE (Synthetic Minority Over-sampling Technique)
💡 개념:
소수 클래스를 단순 복제하는 것이 아니라, 소수 클래스의 데이터를 기반으로 새로운 데이터를 생성하는 방식이다.
즉, 기존 데이터를 기반으로 K-최근접 이웃(KNN) 방식으로 새로운 데이터를 생성한다.
📌 특징:
- 기존 소수 클래스 데이터를 랜덤하게 복제하지 않고, 새로운 데이터를 생성
- KNN을 활용하여 소수 클래스 사이의 새로운 데이터를 합성
📌 장점:
✅ 단순 복제 방식보다 오버피팅 위험이 낮음
✅ 소수 클래스의 분포를 더 자연스럽게 만듦
📌 단점:
❌ 새로운 데이터를 생성하기 때문에 노이즈가 포함될 가능성이 있음
❌ 다수 클래스와 경계가 모호해질 수도 있음
📌 Python 코드 예제:
from imblearn.over_sampling import SMOTE
# SMOTE 적용
X_smote, y_smote = SMOTE().fit_resample(X, y)
print(f"Before SMOTE: {Counter(y)}")
print(f"After SMOTE: {Counter(y_smote)}")📌 SMOTE 적용 전후 비교:
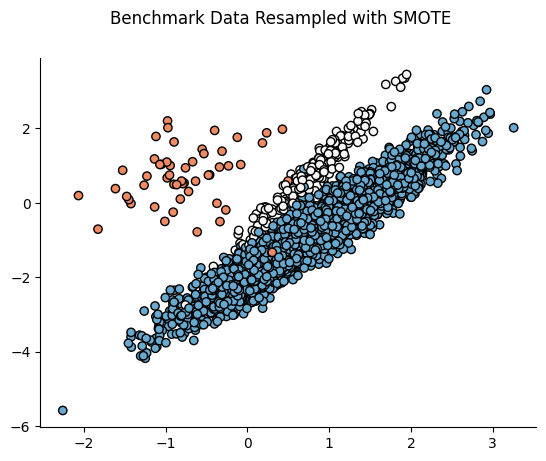
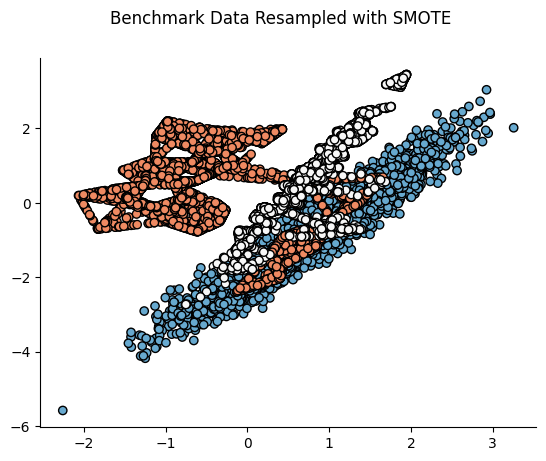
📌 4. ADASYN (Adaptive Synthetic Sampling Approach)
💡 개념:
SMOTE와 비슷하지만, 더 어려운(밀도가 낮은) 샘플에 대해 더 많은 synthetic 데이터를 생성하는 방식이다.
📌 특징:
- 새로운 데이터를 생성할 때, 소수 클래스의 데이터 밀도를 고려
- 밀도가 낮은 곳에서는 더 많은 데이터를 생성하고, 밀도가 높은 곳에서는 적게 생성
📌 장점:
✅ 더 어려운 데이터를 중심으로 학습을 강화할 수 있음
✅ SMOTE보다 모델 성능이 향상될 가능성이 있음
📌 단점:
❌ 새로운 데이터를 무작위로 생성하므로 노이즈가 많아질 위험이 있음
❌ 데이터 분포가 왜곡될 가능성이 있음
📌 시각적 예시:
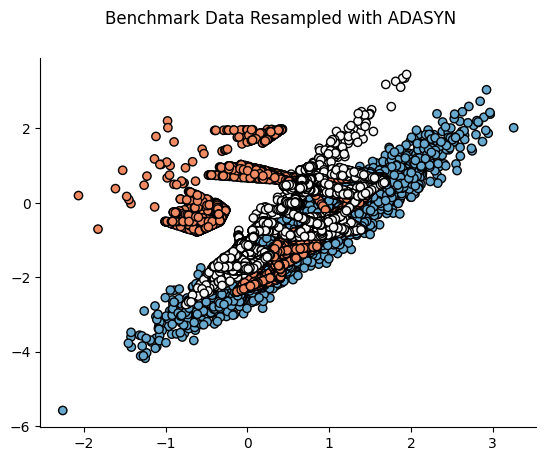
📌 Python 코드 예제:
from imblearn.over_sampling import ADASYN
# ADASYN 적용
X_adasyn, y_adasyn = ADASYN().fit_resample(X, y)
print(f"Before ADASYN: {Counter(y)}")
print(f"After ADASYN: {Counter(y_adasyn)}")🎯 결론: 언제 어떤 기법을 써야 할까?
| 기법 | 데이터 손실 | 오버피팅 위험 | 계산 비용 | 노이즈 발생 가능성 |
|---|---|---|---|---|
| 언더샘플링 | 있음(다수 클래스 일부 삭제) | 낮음 | 낮음 | 낮음 |
| 오버샘플링 | 없음 | 높음(단순 복제 시) | 낮음 | 낮음 |
| SMOTE | 없음 | 낮음(새로운 데이터 생성) | 중간 | 중간 |
| ADASYN | 없음 | 낮음(새로운 데이터 생성) | 높음 | 높음 |
✅ 데이터가 충분하다면? → SMOTE, ADASYN 사용
✅ 데이터가 부족하다면? → 오버샘플링 추천
✅ 데이터가 너무 많아서 학습 시간이 오래 걸린다면? → 언더샘플링 고려
