LG DX SCHOOL
1.HTML

HTML: 문장의 구조를 만드는 것CSS: HTML 요소의 스타일을 선택적으로 지정하는데 사용JS(JavaScript): 웹 브라우저 내 동적 요소 구현HTML은 태그들로 이루어짐태그에 정보가 들어가 있음태그는 계층적인 구조태그 = <시작태그> + 하위태그(or
2.CSS
:html로 뼈대를 잡아 문서에 style을 입혀 줌웹문서와 스타일 시트 따로 작성, 따로 수정/관리 가능PC, 태블릿, 모바일 등 다양한 환경에서 스타일 시트만 수정해주면 되므로 반응형 웹사이트 제작 가능: 특정 HTML 태그에 스타일을 적용하는 법: 특정 클래스에
3.회귀분석1
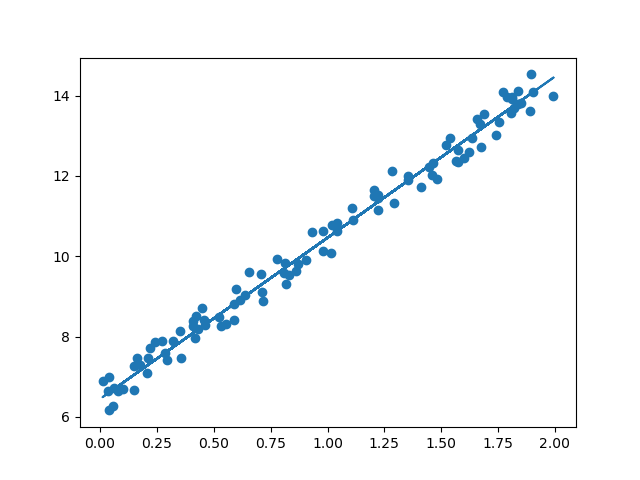
회귀분석(Regression Analysis)은 독립 변수(X)와 종속 변수(Y) 간의 관계를 수학적으로 모델링하여 예측하는 기법특히, 선형 회귀(Linear Regression)는 데이터를 가장 잘 설명하는 직선을 찾는 것단순 선형 회귀는 하나의 독립 변수$X$와 하
4.회귀분석2
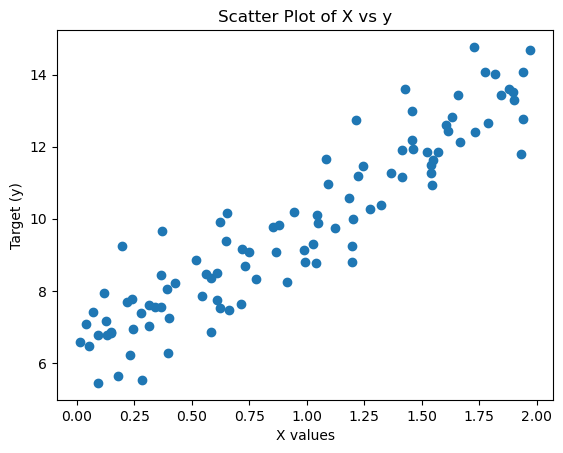
우선 Gradient Descent를 복습해보자out: out: out: out: out: out: out: 상관계수가 높은 LSTAT, RM선별상관계수가 낮은 DIS 선별out: out: :out: out: out: out: out: out:
5.회귀분석 3

다항 회귀를 적용하기 특징(feature)들을 다항식 형태로 확장Scikit-Learn의 PolynomialFeatures 같은 기능을 사용$$x_1, x_2$$degree = 2로 변환 -> 2차항 및 상호작용 항(interaction term) 도 추가$$1, x_
6.분류 성과 지표
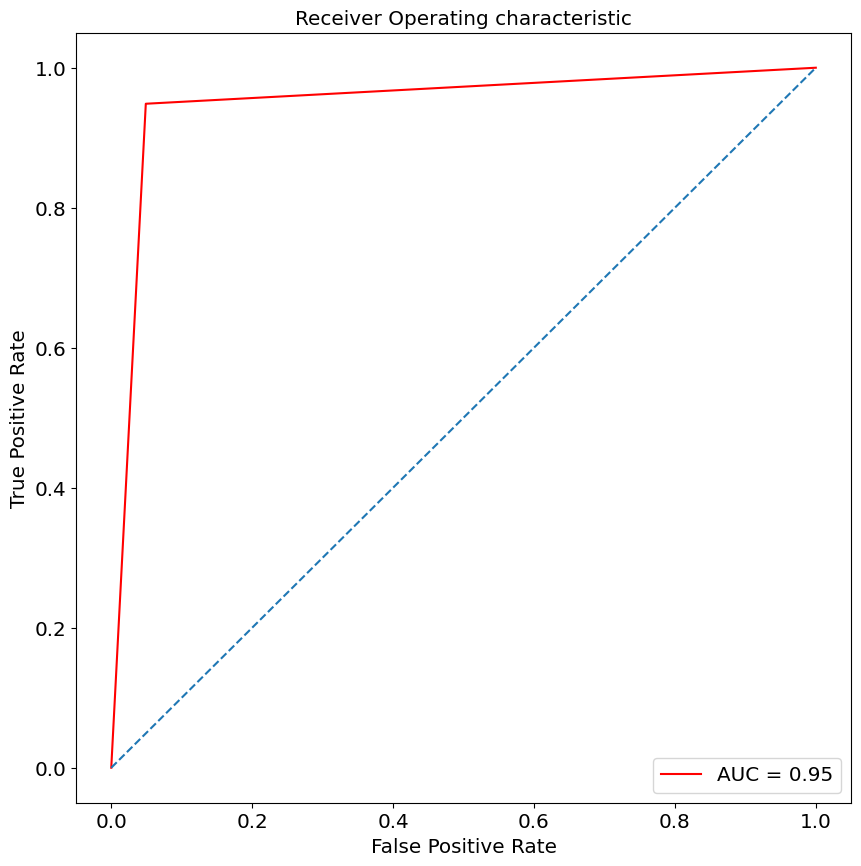
Confusion MatrixAccuracyPrecisionRecallSpecificityF1 ScoreROC-AUC CurveConfusion Matrix는 분류 모델의 예측 결과를 정리한 표TP(참 양성), TN(참 음성), FP(거짓 양성), FN(거짓 음성)으로
7.KNN (K-Nearest Neighbors)
KNN(K-Nearest Neighbors)은 지도 학습(Supervised Learning) 알고리즘새로운 데이터가 들어왔을 때 가장 가까운 K개의 데이터를 참고하여 분류(Classification) 또는 회귀(Regression)를 수행하는 방식거리를 기반으로 판단
8.Logistic Regression
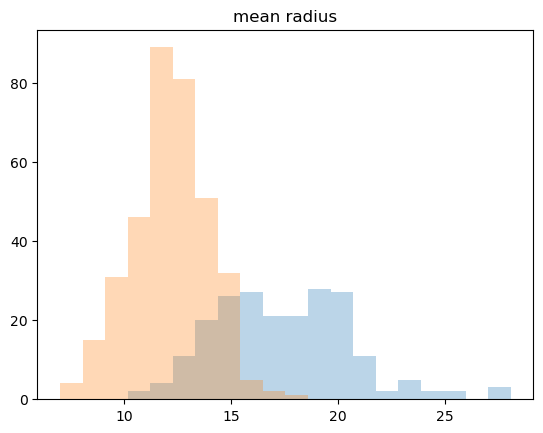
이진 분류(Binary Classification)를 수행하는 지도 학습(Supervised Learning) 알고리즘 일반적인 선형 회귀(Linear Regression)를 기반으로 결과를 확률값(0~1 사이)로 변환하여 분류 문제에 적용됩니다. 📌 특징입력 데
9.Naive Bayes
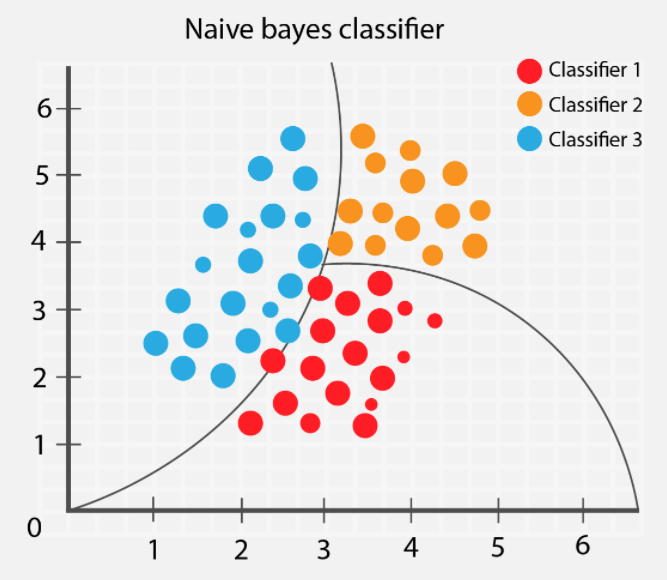
나이브 베이즈(Naive Bayes)는 확률 기반의 분류 알고리즘베이즈 정리(Bayes' Theorem)를 기반으로 동작 각 특징(feature)이 서로 독립이라는 "나이브(naive, 순진한)" 가정을 \-> 계산이 빠르고 간단한 모델 📌 특징확률 모델(Proba
10.Decision Tree
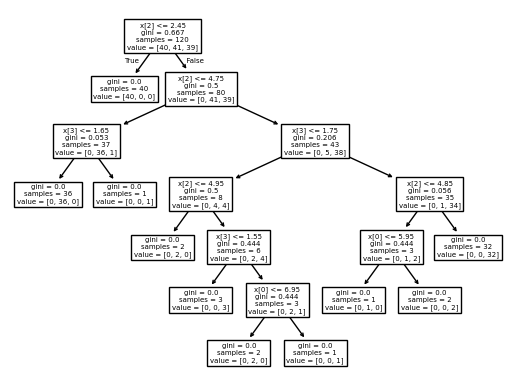
의사 결정 트리(Decision Tree)는 데이터를 계층적으로 분할하여 예측을 수행하는 트리 기반 머신러닝 알고리즘 주어진 데이터를 여러 개의 분할 기준(규칙)을 사용하여 나누고, 트리 구조를 통해 최종 예측을 수행 ✅ 특징 해석이 쉬운 모델 → 사람이 이해하기
11.Boosting 1
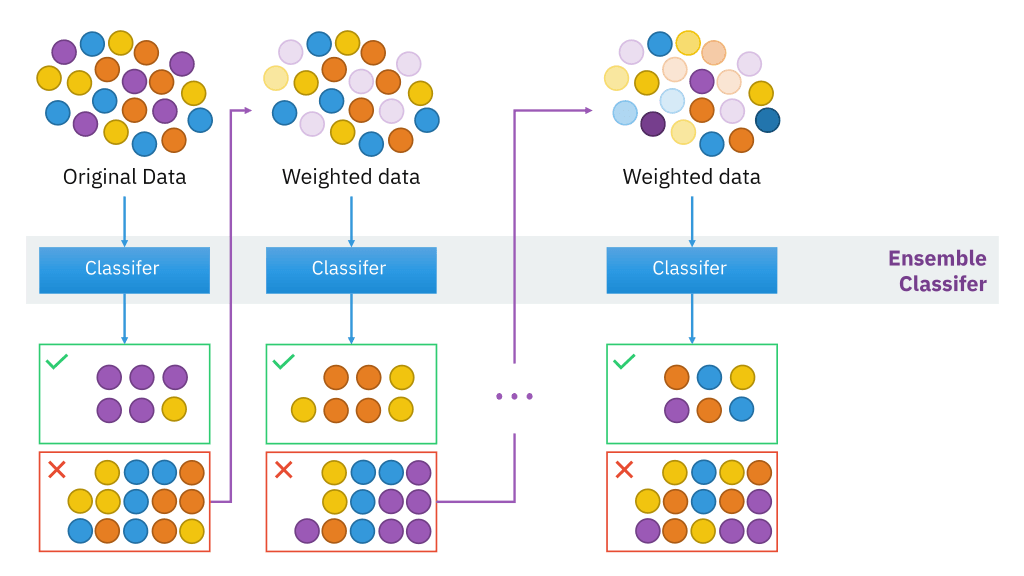
BoostingBoosting ModelBagging VS BoostingAda BoostingGradient BoostingXgboost, A Scalable Tree Boosting SystemLightGBM, A highly Efficient Gradient Bo
12.CatBoost
범주형 데이터(categorical features) 처리에 강점을 가짐. Gradient Boosting 알고리즘들은 반복적으로 트리를 학습하면서 성능을 향상시키는 방식으로 동작함. 기존 부스팅 모델(XGBoost, LightGBM 등)은 Target Leakage(
13.Sampling 개념
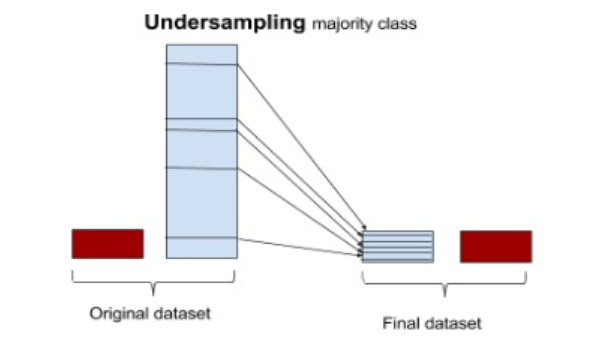
불균형 데이터를 처리하는 방법에는 크게 언더샘플링(Under Sampling), 오버샘플링(Over Sampling), 그리고 합성 데이터 생성(SMOTE, ADASYN 등)이 있다.각 기법의 특징과 장단점을 자세히 살펴보자.💡 개념:다수 클래스(majority cl
14.PCA 개념
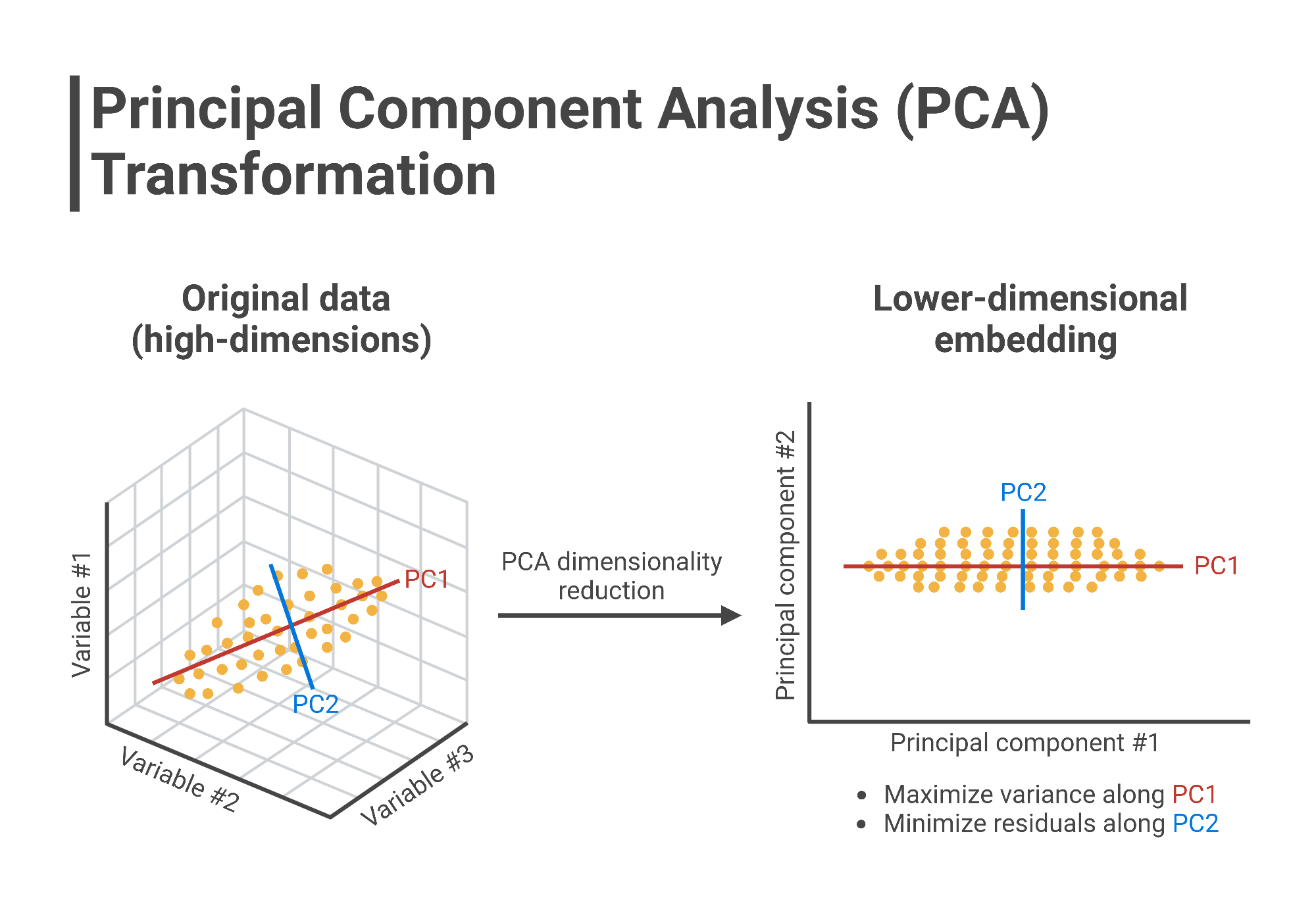
PCA(Principal Component Analysis, 주성분 분석)는 고차원 데이터를 저차원으로 변환하는 차원 축소 기법 데이터의 중요한 특성을 유지하면서도 차원을 줄여 분석의 효율성을 높이고, 시각화를 용이하게 하는 데 사용 PCA는 비지도 학습(Unsupe
15.Olivetti Faces 데이터셋을 활용한 PCA 분석
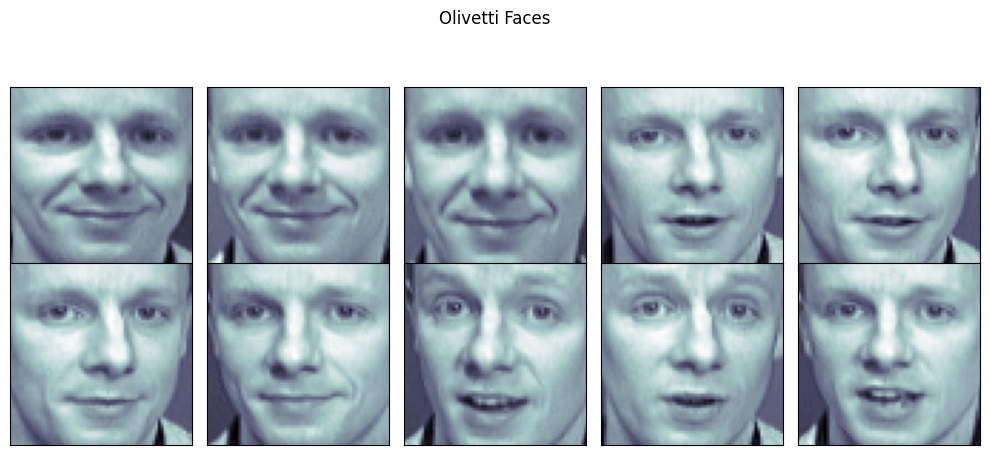
fetch_olivetti_faces()를 사용해 데이터 로드out: 특정 인물(k=20)의 이미지만 필터링하여 2x5 형식으로 출력plt.subplots_adjust()를 활용해 subplot 간격 조정ax.imshow()를 사용하여 얼굴 이미지 표시out: PCA(
16.Kernel PCA – 비선형 데이터 차원 축소
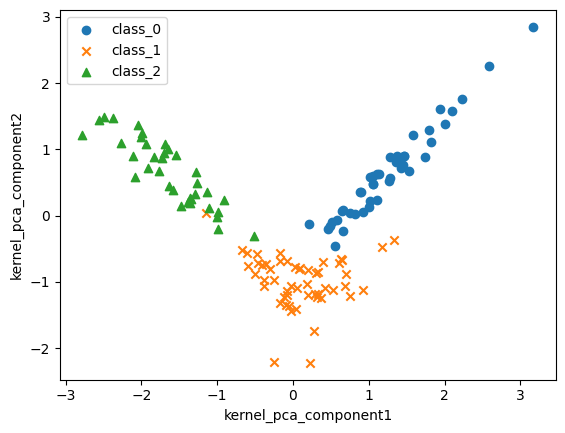
고차원 데이터 분석에서 PCA(주성분 분석) 는 가장 많이 쓰이는 차원 축소 기법. 하지만 비선형 데이터에는 한계가 있음. 이를 해결하는 방법이 Kernel PCA. PCA는 직선적인 구조에서 강력, Kernel PCA는 비선형 패턴까지 반영 가능 커널 함수를
17.K-Means 클러스터링
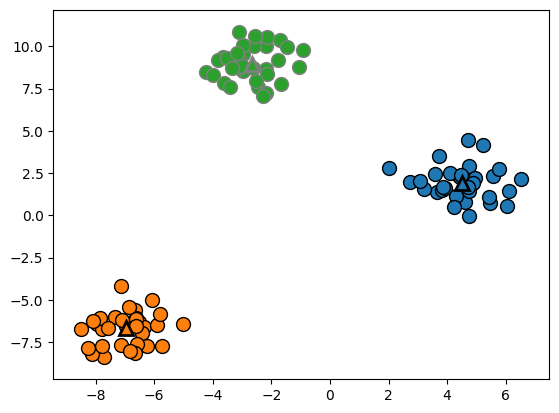
K-Means는 데이터를 K개의 그룹으로 묶는 비지도 학습 알고리즘임 클러스터 중심(centroid)을 기준으로 데이터를 군집화함 초기 중심점 설정이 중요하며, k-means++ 방식이 일반적임 클러스터 개수를 바꾸면 결과가 달라짐 3개 vs 5개 클러스터 비교
18.Clustering
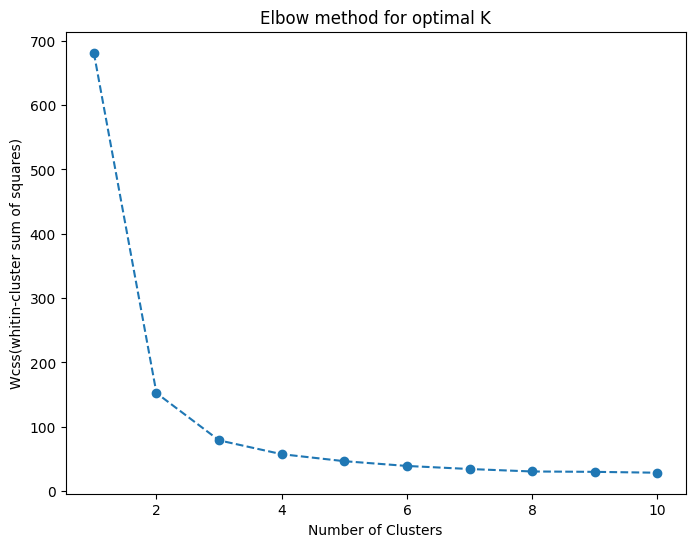
비지도 학습 알고리즘으로 데이터를 K개의 그룹으로 묶음 각 데이터 포인트를 가장 가까운 클러스터 중심(centroid)으로 할당 k-means++ 초기화 방식이 성능이 좋음 elbow method: 급격한 감소가 완만해지는 지점이 최적의 클러스터 수 비지도 학습
19.엘보우 기법 vs 실루엣 스코어
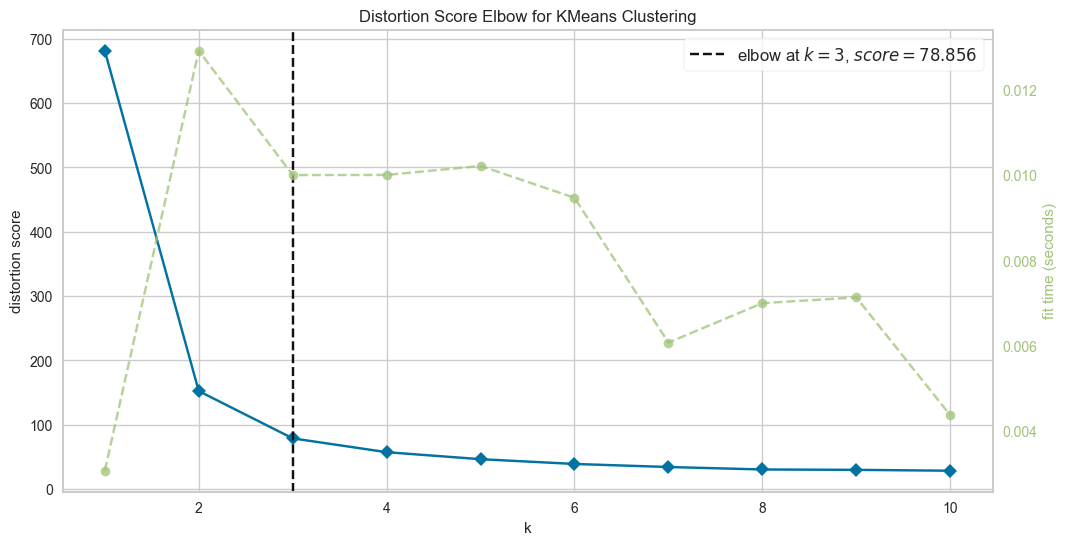
클러스터링에서 최적의 군집 개수(k)를 찾는 것은 중요한 문제임대표적인 방법으로 엘보우 기법과 실루엣 스코어가 있음K-means를 활용하여 두 방법을 비교하고 최적의 k를 결정하는 과정 정리K-means는 비지도 학습 알고리즘으로 데이터를 k개의 클러스터로 나눔각 데이
20.K-Medoids - GMM - K-Means 클러스터링 비교
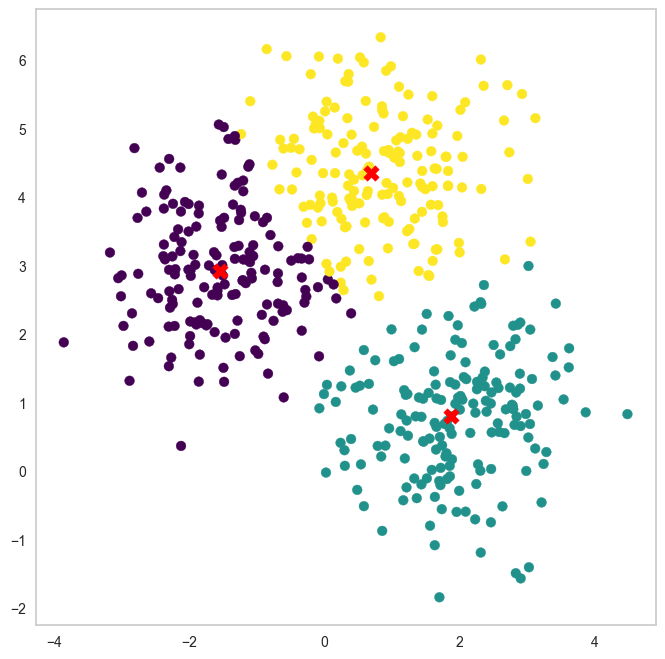
비지도 학습 기법 중 하나로 유사한 데이터 포인트를 그룹으로 묶는 방법데이터의 패턴을 분석하고 구조를 발견하는 데 사용됨대표적인 알고리즘으로 K-Means - K-Medoids - GMM 등이 존재함K-Means와 유사하지만 중심을 데이터 포인트 중 하나로 선택하는 방
21.비지도학습 알고리즘 비교
1. 알고리즘 특징 | 알고리즘 | 원리 | 장점 | 단점 | 언제 사용하면 좋은가? | |----------|------|------|------|--------------------| | K-Means | k개의 중심점을 설정하고, 가장 가까운 중심점으로 데이터들을 군집화. 이후 중심점을 업데이트하며 반복 | 계산 속도가 빠르고 대용량 데이터에 적합 ...
22.영화 리뷰 긍부정 학습하기
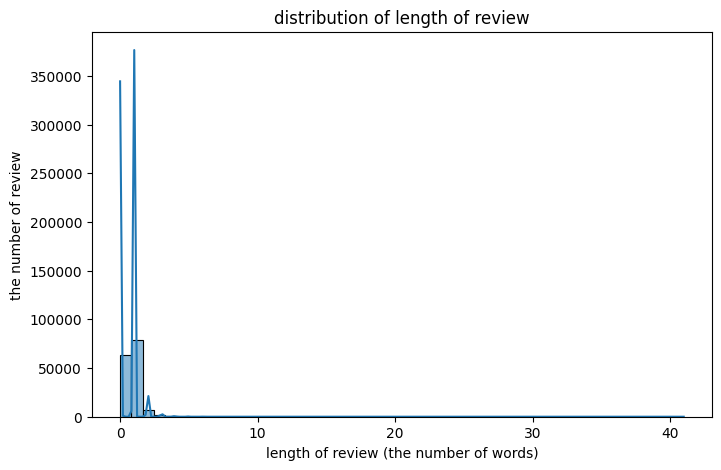
한국 영화 리뷰 데이터로 감성 분석Bow 벡터화 + 로지스틱 회귀 => classification한 문장을 벡터로 변환하는 가장 기초적인 방법임.단어의 순서는 무시하고, 존재 여부나 등장 횟수만 세서 벡터에 기록.특징매우 간단함.대규모 연산 전에 빠르게 피처를 만들 수
23.CountVectorizer부터 TF-IDF까지, 텍스트 벡터화 (개념 + 코드)
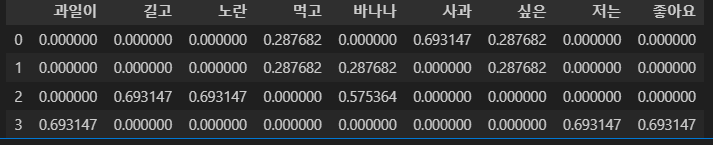
자연어 텍스트를 머신러닝 모델에 입력 가능하도록 숫자 벡터 형태로 변환하는 과정임 대표적 방법: ➊ Count 기반 Bag of Words (BoW) ➋ TF-IDF (Term Frequency-Inverse Document Frequency) 희소 행렬 형태로 변
24.연관규칙 분석 특성 선택, 분류 경계 시각화
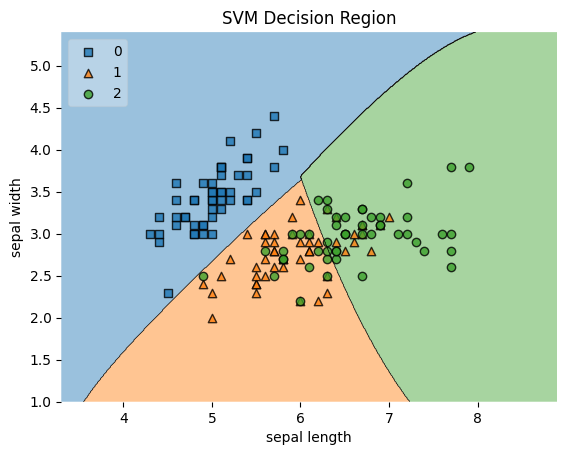
연관규칙 분석은 항목 간 관계를 발견하는 방법임 장바구니 분석(Market Basket Analysis) 대표 예시임 핵심 지표: ➊ Support (지지도) : 전체 거래 중 해당 항목이 포함된 비율 $$ Support = P(A {\\cap} B) $$ ➋
25.추천 시스템 (TF-IDF기반)
surprise의 Reader 객체는 평점 범위를 지정함(0.5~5)ratings DataFrame에서 userId, movieId, rating 컬럼만 추출하여 surprise Dataset에 변환사용자와 아이템 간의 평점 행렬에 숨겨진 잠재요인(latent fact
26.추천 시스템 총정리 (SGD, KNN, ALS)
개념:사용자-아이템 평점 행렬 $R$을 두 개의 저차원 행렬 $P, Q$로 분해$$R \\approx P \\times Q^T$$$P$: 사용자 잠재 요인 행렬 ($m \\times k$), $Q$: 아이템 잠재 요인 행렬 ($n \\times k$)$k$는 잠재 요인
27.잠재요인 기반 필터링 (SGD, SVD)
추천 시스템에서 사용자(user)와 아이템(item) 간의 숨겨진 관계(잠재요인) 를 찾아내어, 비어 있는 평점을 예측하는 방법. R: 사용자-아이템 평점 행렬 P: 사용자-잠재요인 행렬 (user x factor) Q: 아이템-잠재요인 행렬 (item x fac
28.KNN 기반 협업 필터링 정리
협업 필터링(Collaborative Filtering)은 다른 사용자 또는 다른 아이템의 평점을 바탕으로 내가 평가하지 않은 항목의 점수를 예측 KNN 기반 협업 필터링은 그중에서도 비슷한 사용자 또는 비슷한 아이템(K개의 이웃)을 찾아 그들의 평가를 바탕으로 평점
29.ALS (Alternating Least Squares)
협업 필터링의 대표적인 잠재요인 기반 행렬 분해 알고리즘 사용자-아이템 평점 행렬 $R$을 두 개의 저차원 행렬 $P$ (사용자 잠재 요인), $Q$ (아이템 잠재 요인)으로 분해 $R \\approx P \\cdot Q^T$ 한 행(사용자) 또는 열(아이템)을
30.딥러닝으로 패션 아이템 분류하기 - Fashion MNIST 이미지 분류 모델 구현

Fashion MNIST 데이터셋을 활용하여 10종류의 의류 이미지를 분류하는 딥러닝 모델을 구현 TensorFlow와 Keras의 Sequential API를 사용하여 전처리, 학습, 평가, 시각화까지 일련의 분류 과정 수행 모델의 성능을 시각적으로 확인하고, 과
31.CNN(Convolutional Neural Network)
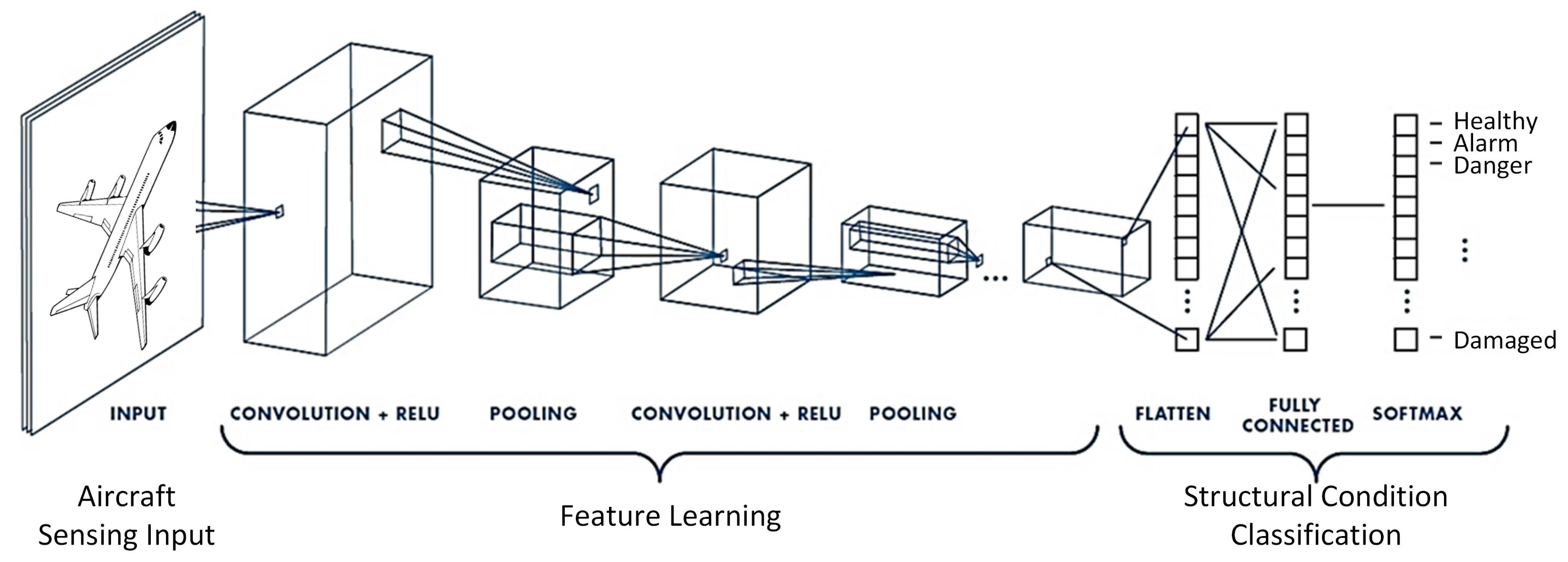
CNN(Convolutional Neural Network)이미지나 영상 처리의 특화된 딥러닝 신경망 구조인간의 시각 피질 기능 모방이미지의 공간적/지역적 정보 보존하면서 특징 추출MLP 구조MLP는 모든 레이어가 DENSE LAYER와 모든 연결이 Fully Conn
32.데이터 증강으로 과적합 줄이기 - Cats vs Dogs 실험 2편
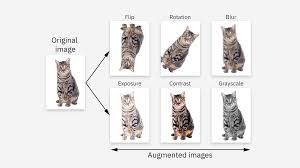
기본 CNN 모델에서 훈련 정확도는 높으나, 검증 정확도는 일정 시점 이후 정체이는 과적합(overfitting) 가능성을 시사 해결책 중 하나는 데이터 증강(data augmentation) 적용 데이터 증강이란 기존 이미지를 회전, 이동, 반전 등 변형하여 훈련
33.사전학습된 VGG16 모델로 전이학습하기 - Cats vs Dogs 실험 3편
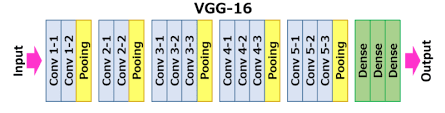
전이학습(Transfer Learning)을 적용 특히, VGG16이라는 잘 훈련된 CNN 모델의 특징 추출기를 활용하여적은 학습 데이터로도 높은 성능 이번 글에서는 VGG16 개념 설명과 함께,사전학습된 weight를 활용한 이미지 분류 실습을 정리전이학습은 다른