독립표본 t-검정
주요 개념
1. 독립된 두 표본
독립표본 t-검정에서 가장 중요한 가정은 두 표본이 서로 독립적
2. 정규성 가정
두 그룹의 데이터가 정규분포를 따른다는 가정
3. 등분산성 가정
두 그룹의 분산이 동일 하다는 가정
4. 귀무가설, 대립가설
- 귀무가설(H0): 두 그룹의 평균 차이가 없다 (동일한 모집단)
- 대립가설(H1): 두 그룹의 평균에 유의미한 차이가 있다
t-검정 공식
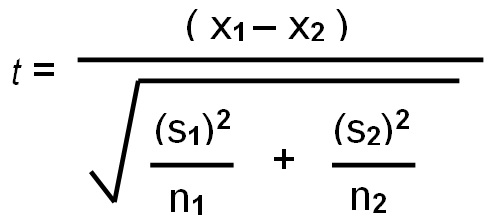
- X1, X2: 두 그룹의 평균
- s1^2, s2^2: 두 그룹의 분산
- n1, n2: 두 그룹의 표본 크기
t-값을 기반으로 p-값을 계산하고 p-값이 유의수준 보다 작으면 귀무가설을 기각하고 대립가설을 채택
문제풀기
문제
어떤 특정 약물을 복용한 사람들의 평균 체온이 복용하지 않은 사람들의 평균 체온과 유의미하게 다른지 검정해보려고 합니다.
가정:
- 약물을 복용한 그룹과 복용하지 않은 그룹의 체온 데이터가 각각 주어져 있다고 가정합니다.
- 각 그룹의 체온은 정규분포를 따른다고 가정합니다.
문제 풀기
가정
가정1: 독립된 두 표본
가정2: 정규성 가정
코드
from scipy import stats
# 데이터 수집
group1 = [36.8, 36.7, 37.1, 36.9, 37.2, 36.8, 36.9, 37.1, 36.7, 37.1]
group2 = [36.5, 36.6, 36.3, 36.6, 36.9, 36.7, 36.7, 36.8, 36.5, 36.7]
# 가설 설정
H0 = "약물을 복용한 그룹과 복용하지 않은 그룹의 평균 체온은 유의미한 차이가 없다."
H1 = "약물을 복용한 그룹과 복용하지 않은 그룹의 평균 체온은 유의미한 차이가 있다."
# 가설검정
t, p = stats.ttest_ind(group1, group2)
a = 0.05
if p < a:
print("귀무가설을 기각합니다. " + H1)
else:
print("귀무 가설을 채택합니다. " + H0)코드 설명
- H0, H1로 귀무가설과 대립가설 설정
- stats의 ttest_ind를 사용하여 독립표본 t검정 값과 p값 구함
- 유의수준 0.05로 설정
- p값이 유의수준보다 적냐 크냐에 따라 귀무가설 기각 or 채택
output

귀무가설 기각
참고자료: https://www.kaggle.com/datasets/agileteam/bigdatacertificationkr

gpt로 다시 배우는 개발