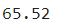map 함수 with GPT
Pandas의 .map() 함수는 주로 Series 객체에 있는 데이터의 각 요소를 변환할 때 사용되는 매우 유용한 메서드입니다. 이 함수는 각 요소를 주어진 규칙에 따라 다른 값으로 매핑하거나 변환할 수 있습니다. map()은 데이터 변환 작업에서 빈번하게 사용되며, 특히 데이터 전처리 과정에서 매우 유용합니다.
.map() 함수의 특징과 사용법
map() 함수는 다음과 같이 사용할 수 있습니다:
1. 딕셔너리(Dictionary)와 함께 사용하여 값 매핑하기
2. 함수(Function)를 적용하여 값 변환하기
3. 시리즈(Series)를 이용하여 값 매핑하기
1. 딕셔너리(Dictionary)로 값 매핑
.map()을 사용하면 시리즈의 각 값을 딕셔너리에 정의된 규칙에 따라 다른 값으로 대체할 수 있습니다. 이 방식은 카테고리 데이터를 다른 값으로 변환하는 데 매우 유용합니다.
예시:
import pandas as pd
# 시리즈 생성
data = pd.Series(['apple', 'banana', 'cherry', 'banana', 'cherry'])
# 딕셔너리를 이용한 매핑
fruit_to_color = {'apple': 'red', 'banana': 'yellow', 'cherry': 'red'}
# 시리즈의 값 변환
data_mapped = data.map(fruit_to_color)
print(data_mapped)결과:
0 red
1 yellow
2 red
3 yellow
4 red
dtype: object위 예시에서 apple, banana, cherry라는 문자열이 fruit_to_color 딕셔너리에 따라 각각 'red' 또는 'yellow'로 변환되었습니다.
특징:
- 딕셔너리에 없는 값이 있으면 결과는
NaN이 됩니다. - 딕셔너리의 키와 시리즈 값이 일치하는 경우에만 값을 대체할 수 있습니다.
2. 함수(Function) 적용하여 값 변환
map()에 사용자 정의 함수를 전달할 수도 있습니다. 이때 함수는 시리즈의 각 요소에 대해 적용되어 새로운 값을 반환합니다. 이를 통해 복잡한 변환 작업을 간단하게 처리할 수 있습니다.
예시:
import pandas as pd
# 시리즈 생성
data = pd.Series([1, 2, 3, 4, 5])
# 값에 10을 더하는 함수 적용
data_mapped = data.map(lambda x: x + 10)
print(data_mapped)결과:
0 11
1 12
2 13
3 14
4 15
dtype: int64특징:
- 함수는 시리즈의 각 요소에 대해 개별적으로 적용됩니다.
- 함수는 인자로 시리즈의 각 값을 받으며, 그 값을 변환해 반환합니다.
3. 시리즈(Series)로 값 매핑
.map()은 다른 시리즈(Series)를 이용하여 값을 매핑할 수도 있습니다. 이때 두 시리즈 간의 값이 매칭되면 해당 시리즈의 값을 새로운 값으로 변환할 수 있습니다.
예시:
import pandas as pd
# 두 시리즈 생성
data = pd.Series(['apple', 'banana', 'cherry'])
fruit_colors = pd.Series({'apple': 'red', 'banana': 'yellow', 'cherry': 'red'})
# 시리즈의 값 매핑
data_mapped = data.map(fruit_colors)
print(data_mapped)결과:
0 red
1 yellow
2 red
dtype: object여기서는 fruit_colors라는 또 다른 시리즈를 이용해 data의 값을 매핑했습니다. 시리즈 간의 값 매칭이 일어나면 해당 값을 기준으로 데이터를 변환합니다.
4. 결측값 처리 (NaN)
.map()은 매핑되지 않은 값에 대해 NaN 값을 반환합니다. 만약 딕셔너리나 시리즈에서 찾을 수 없는 값이 있다면, 그 값은 NaN으로 대체됩니다.
예시:
import pandas as pd
data = pd.Series(['apple', 'banana', 'grape'])
fruit_to_color = {'apple': 'red', 'banana': 'yellow'}
# 딕셔너리 매핑 (grape는 딕셔너리에 없으므로 NaN)
data_mapped = data.map(fruit_to_color)
print(data_mapped)결과:
0 red
1 yellow
2 NaN
dtype: object여기서 grape는 fruit_to_color 딕셔너리에 없기 때문에, 그 값은 NaN으로 변환됩니다.
사용 시 주의점 및 성능
- 성능:
.map()은 시리즈의 각 요소에 대해 반복적으로 적용되기 때문에 대규모 데이터셋에서는 성능에 주의해야 합니다. 많은 양의 데이터를 처리할 때는.apply()나 벡터화된 연산을 고려하는 것이 좋습니다. - 시리즈와 데이터프레임:
.map()은 시리즈에만 적용됩니다. 데이터프레임 전체에 적용하려면.applymap()을 사용해야 합니다.
요약
- 딕셔너리 매핑: 시리즈 값들을 딕셔너리에 정의된 값으로 변환.
- 함수 적용: 시리즈의 각 요소에 대해 사용자 정의 함수를 적용.
- 다른 시리즈와 매핑: 시리즈 간 매핑을 통해 값 변환.
- 결측치 처리: 매핑되지 않은 값은
NaN으로 처리.
.map()은 데이터 전처리와 변환 작업에서 매우 유용하며, 특히 데이터의 재구성, 범주형 데이터의 변환, 결측값 처리 등에 자주 사용됩니다.
문제
결측치 처리
주어진 데이터에서 결측치가 80%이상 되는 컬럼은(변수는) 삭제하고, 80% 미만인 결측치가 있는 컬럼은 'city'별 중앙값으로 값을 대체하고 'f1'컬럼의 평균값을 출력하세요!
라이브러리 및 데이터 불러오기
import numpy as np
import pandas as pd
df = pd.read_csv('../input/bigdatacertificationkr/basic1.csv')
dfoutput
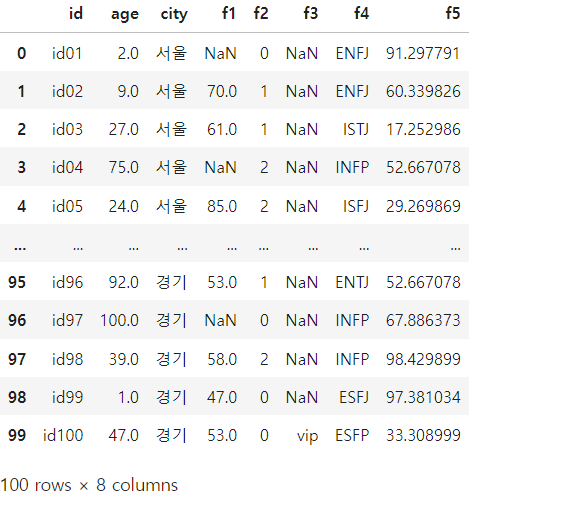
EDA - 결측값 확인
- method1
p = df.isnull().mean()
p- method2
df.isnull().sum()/df.shape[0]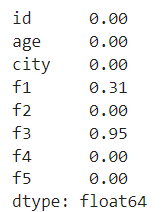
80%이상 결측치 칼럼, 삭제
- method1
df = df.drop(columns=(p[p>=0.8].index))-
p 값이 0.8 이상, 즉 결측치 비율이 80%가 이상이되는(p>=0.8)의 p의 인덱스 추출.(p[p>=0.8].index) 열 이름이 필요하기 때문에 .index 필요
-
drop 함수 안에 있는 파라미터인 columns 중 = 0.8이상의 인덱스를 가진 컬럼 제거
-
method2
# f3 컬럼 삭제
print("삭제 전:", df.shape)
df = df.drop(['f3'], axis=1)
print("삭제 후:", df.shape)f3 제거
- method3
df.drop(columns=['f3'])도시 확인
df['city'].unique()
도시별 중앙값 찾기
s = df[df['city']=='서울']['f1'].median()
b = df[df['city']=='부산']['f1'].median()
d = df[df['city']=='대구']['f1'].median()
k = df[df['city']=='경기']['f1'].median()
s,b,d,k- s,b,d,k 값에 median()을 이용해 중앙값 넣기
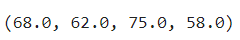
80%미만 결측치 컬럼, city 별 중앙값으로 대체
df['f1'] = df['f1'].fillna(df['city'].map({'서울':s,'경기':k,'부산':b,'대구':d}))- fillna 함수를 이용해 결측치에 값 넣기
- map을 활용해 서울은 s 값, 경기는 k 값... 넣기
결측치 확인
df.isnull().sum()
결측치가 사라진 것을 볼 수 있음
f1 평균값 결과 출력
df['f1'].mean()