1. 연관규칙 분석 (Association Rule)
-
연관규칙 분석은 항목 간 관계를 발견하는 방법임
-
장바구니 분석(Market Basket Analysis) 대표 예시임
-
핵심 지표:
➊ Support (지지도) : 전체 거래 중 해당 항목이 포함된 비율➋ Confidence (신뢰도) : A → B일 때 A가 발생하면 B가 함께 발생할 확률
➌ Lift (향상도) : 두 항목의 독립성 비교 지표 (1보다 크면 양의 상관관계)
-
Apriori 알고리즘을 사용해 빈발 항목 집합 찾음
-
mlxtend라이브러리 사용
연관규칙 분석 코드 예제
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
import pandas as pd
# Transaction: 하나의 작업 단위로 수행되는 연산들의 집합. 주로 database나 분산 시스템, 금융 시스템에서 사용함
# 원자적인 작업 단위
# 특징: ACID 속성 (Atomicity, Consistency, Isolation, Durablility)
dataset = [
['우유', '빵', '계란'],
['우유', '기저귀', '맥주'],
['우유', '기저귀', '맥주', '콜라'],
['빵', '우유'],
['빵', '계란']
]
te = TransactionEncoder()
te_result = te.fit(dataset).transform(dataset)
df=pd.DataFrame(te_result, columns=te.columns_)
df = pd.DataFrame(te_result, columns = te.columns_)
print("이진 형태의 거래 데이터: ")
print(df)
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
print("\n 빈발 항목 집합 (최소 지지도=50%):")
print(frequent_itemsets)
# 연관 규칙 추출 (최소 신뢰도: 0.7)
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)
print("\n 생성된 연관규칙 (최소 신뢰도=70%):")
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])out:
이진 형태의 거래 데이터:
계란 기저귀 맥주 빵 우유 콜라
0 True False False True True False
1 False True True False True False
2 False True True False True True
3 False False False True True False
4 True False False True False False
빈발 항목 집합 (최소 지지도=50%):
support itemsets
0 0.6 (빵)
1 0.8 (우유)
생성된 연관규칙 (최소 신뢰도=70%):
Empty DataFrame
Columns: [antecedents, consequents, support, confidence, lift]
Index: []2. 특성 선택 (Feature Selection)
-
머신러닝 모델의 성능과 과적합 방지를 위해 필요함
-
너무 많은 변수 → 과적합 / 계산 비용 증가 문제 발생
-
Sequential Feature Selector (SFS) 사용 가능
-
방향:
➊ Forward Selection : 하나씩 추가
➋ Backward Selection : 하나씩 제거 -
mlxtend및sklearn둘 다 가능함
mlxtend 라이브러리로 순차 특성 선택
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
iris = load_iris()
X, y = iris.data, iris.target
knn = KNeighborsClassifier(n_neighbors=3)
sfs = SFS(knn, k_features=2, forward=True, scoring='accuracy', cv=5)
sfs = sfs.fit(X, y)
print('선택된 특성:', sfs.k_feature_names_)
print('정확도:', sfs.k_score_)out:
선택된 특성: ('0', '3')
정확도: 0.9533333333333334sklearn SequentialFeatureSelector 사용 (Backward)
from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.model_selection import cross_val_score
import numpy as np
iris = load_iris()
X, y = iris.data, iris.target
knn = KNeighborsClassifier(n_neighbors=3)
# Backward 방식으로 2개 특성 선택
sfs = SequentialFeatureSelector(knn, n_features_to_select=2, direction='backward', cv=5)
sfs = sfs.fit(X, y)
selected_features = sfs.get_support(indices=True)
print('선택된 특성 인덱스:', selected_features)
print('선택된 특성 이름:', [iris.feature_names[i] for i in selected_features])
# 선택된 특성으로 교차검증 정확도 확인
X_selected = X[:, selected_features]
accuracy = np.mean(cross_val_score(knn, X_selected, y, cv=5))
print('선택된 특성의 KNN 정확도:', accuracy)out:
선택된 특성: [2 3]
선택된 특성 이름 ['petal length (cm)', 'petal width (cm)']
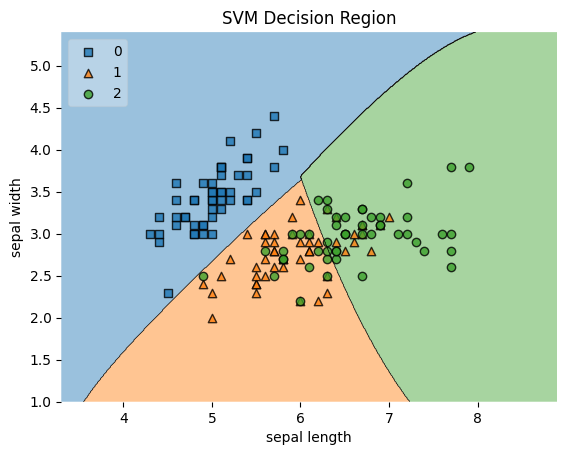
정확도 0.95333333333333343. 분류 경계 시각화 (Decision Boundary Visualization)
- 분류 모델이 데이터를 어떻게 구분하는지 시각화하는 방법
- 2차원 데이터에서 유용하게 활용됨
mlxtend.plotting.plot_decision_regions사용
SVM 분류 경계 시각화
from sklearn.datasets import load_iris
from sklearn.svm import SVC
from mlxtend.plotting import plot_decision_regions
import matplotlib.pyplot as plt
iris = load_iris()
X = iris.data[:, :2] # 시각화를 위해 2개 특성 선택
y = iris.target
svm = SVC()
svm.fit(X, y)
# 시각화
plot_decision_regions(X, y, clf=svm, legend=2)
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.title('SVM Decision Region')
plt.show()out:
✅ 정리
| 구분 | 설명 |
|---|---|
| 연관규칙 분석 | 항목 간의 관계를 찾는 분석 방법, 지지도(support), 신뢰도(confidence), 향상도(lift) 사용 |
| 특성 선택 | 불필요한 변수를 제거해 모델 성능 향상 및 과적합 방지 |
| 분류 경계 시각화 | 모델이 데이터를 어떻게 구분하는지 시각적으로 확인하는 방법 |

gpt로 다시 배우는 개발