✅ 1. 텍스트 벡터화 개념
- 자연어 텍스트를 머신러닝 모델에 입력 가능하도록 숫자 벡터 형태로 변환하는 과정임
- 대표적 방법:
➊ Count 기반 Bag of Words (BoW)
➋ TF-IDF (Term Frequency-Inverse Document Frequency) - 희소 행렬 형태로 변환하여 저장 공간과 계산 효율성 확보 가능함
✅ 2. CountVectorizer 개념
- 문서 안의 단어 출현 빈도(Frequency)를 기준으로 벡터화하는 방식임
- 단어의 출현 횟수를 그대로 사용함
- 단순하지만 자주 등장하는 의미 없는 단어(불용어)도 반영됨
- 높은 빈도를 가지는 단어는 중요도가 높다고 판단할 수 없기 때문에 주의 필요함
➡️ CountVectorizer 코드 예시
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(
max_df=0.95, # 전체 문서에서 95% 이상 등장하면 제외함 (너무 흔한 단어 제거)
min_df=2, # 2회 미만 등장하면 제외함 (너무 희귀한 단어 제거)
max_features=2000, # 빈도 높은 단어 2000개까지만 사용함
stop_words='english', # 영어 불용어 제거함
ngram_range=(1,2) # 단어 1개와 2개 연속된 조합 추출함
)
text_data = [
"Natural Language Processing is amazing!",
"I love learning about Machine Learning.",
"Deep Learning is a subset of Machine Learning."
]
X = vectorizer.fit_transform(text_data)
print("특성 이름:", vectorizer.get_feature_names_out())
print("DTM 행렬:\n", X.toarray())out:
특성 이름: ['learning' 'machine' 'machine learning']
DTM 행렬:
[[0 0 0]
[2 1 1]
[2 1 1]]- 결과: DTM (Document-Term Matrix) 형태로 변환함
- 행: 문서 / 열: 단어 / 값: 해당 단어의 빈도
✅ 3. CountVectorizer 직접 구현
- 사이킷런과 비슷한 기능을 수행하는
myCountVectorizer클래스 직접 구현 가능함 - 입력: 이미 토큰화된 리스트
- 출력: DTM 행렬 (numpy array 형태)
➡️ myCountVectorizer 클래스 예시
import numpy as np
class myCountVectorizer():
def __init__(self):
self.vocabulary_ = {}
def fit(self, docs):
for words in docs:
for word in words:
self.vocabulary_[word] = self.vocabulary_.get(word, len(self.vocabulary_))
return self
def transform(self, docs):
m = np.zeros((len(docs), len(self.vocabulary_)))
for i, words in enumerate(docs):
for word in words:
j = self.vocabulary_.get(word.lower())
if j is not None:
m[i, j] += 1
return m
def fit_transform(self, docs):
self.fit(docs)
return self.transform(docs)
documents = [
['Hello', 'world', 'hello'],
['machine', 'learning', 'is', 'fun'],
['hello', 'machine', 'learning']
]
vectorizer = myCountVectorizer()
X = vectorizer.fit_transform(documents)
print("단어 인덱스:", vectorizer.vocabulary_)
print("DTM:\n", X)- 각 단어마다 인덱스를 부여함
- 각 문서별 단어 등장 횟수로 DTM 생성함
✅ 4. 희소 행렬(Sparse Matrix)
- 대부분 값이 0인 벡터를 효율적으로 저장하기 위한 방식임
- COO 형식(좌표 리스트), CSR 형식(압축 행 방식) 있음
➡️ COO 형식 예시
from scipy import sparse
import numpy as np
# 0이 아닌 배열(Values)
data = np.array([3,4,5,7,6,8,9])
# 데이터가 위치한 행(Row) 인덱스
row_pos = np.array([0,1,2,2,3,4,4])
# 데이터가 위치한 열(Column) 인덱스
col_pos = np.array([2,4,0,3,1,2,4])
# COO 형식의 희소 행렬 생성 (COO Matrix)
sparse_coo = sparse.coo_matrix((data, (row_pos, col_pos)),shape=(5,5))
# 결과 출력
print("희소 행렬(Sparse Matrix) 타입", type(sparse_coo))
print("COO 형식 희소 행렬 : \n", sparse)
#희소행렬을 밀집 행렬(Dense Matrix)로 변환
dense_matrix = sparse_coo.toarray()
# 희소 행렬을 밀집 행렬(Dense Matrix)로 변환
print("\n 변환된 밀집 행렬(Dense Matrix) 타입", type(dense_matrix))
print("밀집 행렬: \n", dense_matrix)out:
희소 행렬(Sparse Matrix) 타입 <class 'scipy.sparse._coo.coo_matrix'>
COO 형식 희소 행렬 :
<module 'scipy.sparse' from 'c:\\Users\\user\\anaconda3\\Lib\\site-packages\\scipy\\sparse\\__init__.py'>
변환된 밀집 행렬(Dense Matrix) 타입 <class 'numpy.ndarray'>
밀집 행렬:
[[0 0 3 0 0]
[0 0 0 0 4]
[5 0 0 7 0]
[0 6 0 0 0]
[0 0 8 0 9]]- (행, 열, 값) 좌표로 0이 아닌 값만 저장함
➡️ CSR 형식 예시
from scipy import sparse
dense2 = np.array([[0,0,1,0,0,5],
[1,4,0,3,2,5],
[0,6,0,3,0,0],
[2,0,0,0,0,0],
[0,0,0,7,0,8],
[1,0,0,0,0,0]])
# 0 이 아닌 데이터 추출
data2 = np.array([1, 5, 1, 4, 3, 2, 5, 6, 3, 2, 7, 8, 1])
# 행 위치와 열 위치를 각각 array로 생성
row_pos = np.array([0, 0, 1, 1, 1, 1, 1, 2, 2, 3, 4, 4, 5])
col_pos = np.array([2, 5, 0, 1, 3, 4, 5, 1, 3, 0, 3, 5, 0])
# COO 형식으로 변환
sparse_coo = sparse.coo_matrix((data2, (row_pos,col_pos)))
# 행 위치 배열의 고유한 값들의 시작 위치 인덱스를 배열로 생성
#(인덱스의 시작점으로 보면 좋음.)
#0이 2개, 1이 5개, 2가 2개, 3이 1개, 4가 2개,5가 1 : 총 13개
row_pos_ind = np.array([0, 2, 7, 9, 10, 12, 13])
# CSR 형식으로 변환
sparse_csr = sparse.csr_matrix((data2, col_pos, row_pos_ind))
print('COO 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인')
print(sparse_coo.toarray())
print('CSR 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인')
print(sparse_csr.toarray())out:
COO 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인
[[0 0 1 0 0 5]
[1 4 0 3 2 5]
[0 6 0 3 0 0]
[2 0 0 0 0 0]
[0 0 0 7 0 8]
[1 0 0 0 0 0]]
CSR 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인
[[0 0 1 0 0 5]
[1 4 0 3 2 5]
[0 6 0 3 0 0]
[2 0 0 0 0 0]
[0 0 0 7 0 8]
[1 0 0 0 0 0]]- 압축 형태로 저장해 효율적임
row_pos_ind: 등차수열이라고 생각하셈
✅ 5. TF-IDF 개념
- TF (Term Frequency): 문서에서 특정 단어의 등장 빈도
- IDF (Inverse Document Frequency): 단어의 희귀도를 반영하는 지표
- 자주 등장하지만 모든 문서에 다 있는 단어는 중요도가 낮음
- 특정 문서에서만 자주 나타나는 단어는 중요도가 높음
- TF * IDF 값이 높을수록 중요한 단어로 간주함
✅ TF-IDF 공식
- : 단어 t의 문서 d에서의 빈도
- : 해당 단어가 등장한 문서 수
- : 전체 문서 수
➡️ TF-IDF 직접 구현 코드
import pandas as pd
from math import log
docs = [
'먹고 싶은 사과',
'먹고 싶은 바나나',
'길고 노란 바나나 바나나',
'저는 과일이 좋아요'
]
vocab = list(set(w for doc in docs for w in doc.split()))
vocab.sort()
vocabout :
['과일이', '길고', '노란', '먹고', '바나나', '사과', '싶은', '저는', '좋아요']TF, IDF, TF-IDF 함수 만들기
N = len(docs)
def tf(t,d):
return d.count(t)
def idf(t):
df = 0
for doc in docs:
df += t in doc
return log(N/(df+1))
def tfidf(t,d):
return tf(t,d)*idf(t)
TF 출력
# TF를 구해보자. -> DM, TDM을 데이터프레임에 저장하여 출력
result = []
for i in range(N): #각 문서에 대해서 for문을 작동
result.append([]) # 새로운 문서에 대한 리스트 생성
d = docs[i] # docs: 단어 리스트로 구성된 문서들의 리스트.
for j in range(len(vocab)): # vocab : 전체 문서에서 등장하는 고유한 단어들의 리스트
t = vocab[j] # 현재 단어 선택
result[-1].append(tf(t,d)) # 문서에서 해당 단어의 빈도를 계산하여 추가
tf_ = pd.DataFrame(result, columns = vocab)
print(tf_)out:
과일이 길고 노란 먹고 바나나 사과 싶은 저는 좋아요
0 0 0 0 1 0 1 1 0 0
1 0 0 0 1 1 0 1 0 0
2 0 1 1 0 2 0 0 0 0
3 1 0 0 0 0 0 0 1 1idf 구하기
#idf를 구해보자
result = []
for j in range(len(vocab)):
t = vocab[j]
result.append(idf(t))
idf_ = pd.DataFrame(result, index = vocab,columns=['IDF'])
print(idf_)out :
IDF
과일이 0.693147
길고 0.693147
노란 0.693147
먹고 0.287682
바나나 0.287682
사과 0.693147
싶은 0.287682
저는 0.693147
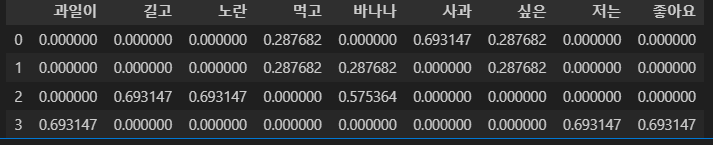
좋아요 0.693147tf-idf 행렬
# tf-idf 행렬 생성
result = []
for i in range(N):
result.append([])
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
result[-1].append(tfidf(t,d))
tfidf_ = pd.DataFrame(result, columns = vocab)
tfidf_out :
✅ 6. 직접 구현하기
def doc(*args):
doc_list = []
tf = pd.DataFrame()
idf = pd.DataFrame()
tf_idf = pd.DataFrame()
# 단어 리스트 생성
for i in args:
# 단어 분해
tmp_list = i.split(' ')
# 리스트 결합
doc_list += tmp_list
doc_list = list(set(doc_list))
# DF
df = []
for i in doc_list:
tmp = 0
for j in args:
# 단어 분해
tmp_list = list(set(j.split(' ')))
if i in tmp_list:
tmp += 1
df.append(tmp)
# TF(DTM), IDF, TF-IDF
for i in range(len(doc_list)):
tmp = []
tmp2 = []
tmp3 = []
for j in args:
# 단어 분해
tmp_list = j.split(' ')
# 단어 세기
tmp.append(tmp_list.count(doc_list[i]))
tmp2.append(log(len(args) / (df[i] + 1)))
tmp3.append((tmp_list.count(doc_list[i])) * (log(len(args) / (df[i] + 1))))
# 데이터 프레임 추가
tf[doc_list[i]] = tmp
idf[doc_list[i]] = tmp2
tf_idf[doc_list[i]] = tmp3
return tf, df, idf, tf_idf
tf, df, idf, tf_idf = doc(doc1, doc2, doc3)
- 자동으로 단어 분리, TF-IDF 계산 및 벡터화 진행함
✅ 정리
| 구분 | 설명 |
|---|---|
| CountVectorizer | 단어 빈도 기반으로 벡터화함. 등장 횟수가 중요함. |
| TF-IDF | 빈도 + 희귀도 반영함. 단어의 상대적 중요도 계산함. |
| Sparse Matrix | 대부분이 0인 데이터에서 메모리 절약 및 연산 효율성 확보 방법. |
| CSR / COO | 희소 행렬을 저장하는 방식임. |

gpt로 다시 배우는 개발