이상치란?
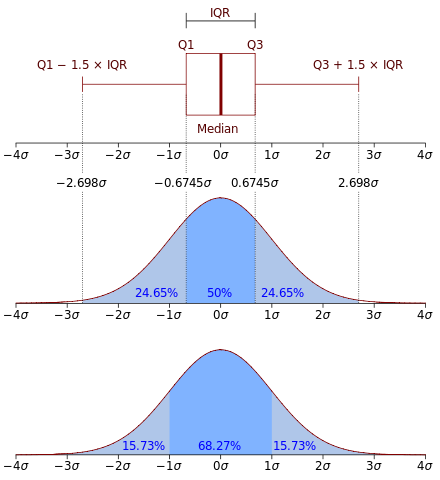
IQR (사분위수 범위)
IQR은 데이터 세트를 사분위수로 나누어 표시 여부를 정한 것
위 그림과 같이 IQR은 Q1~Q3의 값이다.
Q3는 전체 데이터의 75% 값을 의미하고, Q1은 전체 데이터의 25% 값을 의미한다.
즉
IQR = Q3 - Q1
이상치
일반적인 데이터 분포를 따르지 않는 값으로, 다른 데이터와 차이가 매우 큰 값이다. 즉 전체 데이터 분포에서 크게 벗어나는 값들이다.
따라서 크게 벗어난 값 중에 매우 적은 값과 매우 큰 값이 존재할 수 있다.
Lower bound = Q1- 1.5 * IQR
Upper bound = Q3 + 1.5 * IQR
로 Lower bound보다 적은값과, Upper bound보다 큰 값이 이상치라고 본다.
그럼 본격적으로 문제를 풀어보자
이상치를 찾아라
문제: 데이터에서 IQR을 활용해 Fare컬럼의 이상치를 찾고, 이상치 데이터의 여성 수를 구하시오
우선 데이터를 먼저 불러오자.
import numpy as np
import pandas as pd
df = pd.read_csv('../input/titanic/train.csv')- numpy와 pandas를 불러오고
- 데이터를 불러왔다.
간단한 데이터 분석
# 간단한 탐색적 데이터 분석 (EDA)
print(df.shape) #데이터의 크기
print(df.isnull().sum()) # 결측치 합을통한 확인 -> Age, Cabin, Embarked에 존
df.head()- 데이터의 크기를 확인하고
- 결측치를 확인하는 isnull과 그 값들을 sum으로 합쳐 결측치를 쉽게 확인
- df.head()를 통해 데이터들을 출력
IQR 구하기
Q1 = np.percentile(df['Fare'], 25)
Q3 = np.percentile(df['Fare'], 75)
IQR = Q3 - Q1
Q1 - 1.5 * IQR, Q3 + 1.5 * IQR- np.percentile은 값 중에서 특정 백분위수에 해당하는 값을 구해준다.
- 즉 Q1은 np.percentile(df['Fare'], 25)로 Fare 컬럼이 25%에 해당하는 백분위수 값
- Q3는 np.percentile(df['Fare'], 75)로 Fare 컬럼이 75%해당하는 값
- IQR은 Q3-Q1
- 마지막 줄은 Upper bound와, Lower bound를 확인한다.

이때 Lower bound가 음수가 나왔는데, Fare은 요금이므로 Lower bound 및에 있는 값은 존재할 수 없게 된다
이상치 구하기
# 이상치 데이터 구하기
outdata1 = df[df['Fare'] < (Q1 - 1.5 * IQR)]
outdata2 = df[df['Fare'] > (Q3 + 1.5 * IQR)]
len(outdata1), len(outdata2)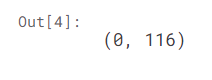
보다 싶이 output에서도 upper bound를 넘는 이상치만 나왔다.
이상치 데이터에서 여성 수 구하기
print(sum(outdata2['Sex'] =='female'))
따라서 답은 70이다.
참고자료:

gpt로 다시 배우는 개발