문제
'f4'컬럼의 값이 'ESFJ'인 데이터를 'ISFJ'로 대체하고, 'city'가 '경기'이면서 'f4'가 'ISFJ'인 데이터 중 'age'컬럼의 최대값을 출력하시오!
### 라이브러리 및 데이터 불러오기
import numpy as np
import pandas as pd
df = pd.read_csv('../input/bigdatacertificationkr/basic1.csv')
df.head()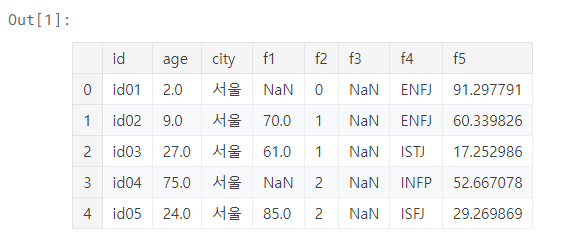
### 특정 값을 가진 데이터 확인
df[df['f4'] == 'ESFJ']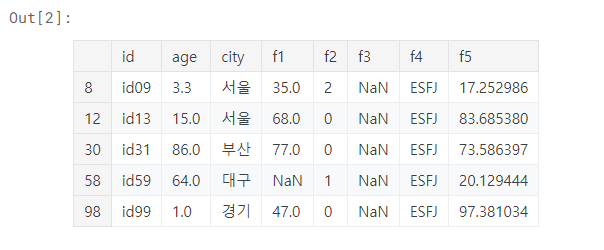
값 변경하기
#method 1
df = df.replace('ESFJ','ISFJ')df에서 .replace를 통해 ESFJ 값을 --> ISFJ로 바꾼다
#method 2
df['f4'] = df['f4'].replace('ESFJ', 'ISFJ')여기는 특정 칼럼을 지칭하여 특정 칼럼 값만 바꾼다.
2개의 조건이 맞는 데이터 확인
df[(df['f4'] == 'ISFJ') & (df['city'] == '경기')]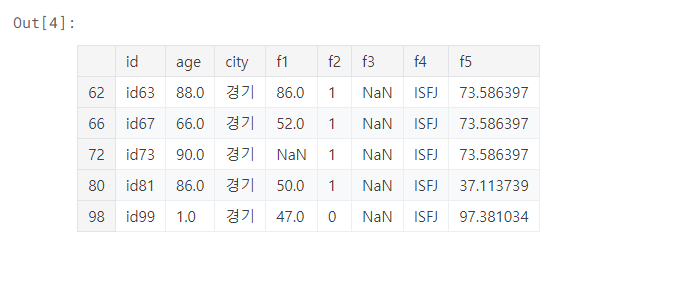
- &(엔드)를 통해 두개의 조건이 맞는 데이터 출력
2개의 조건이 맞는 값 중 age 컬럼 최댓값 확인
#method1
df[(df['f4'] == 'ISFJ') & (df['city'] == '경기')].sort_values(by='age', ascending=False)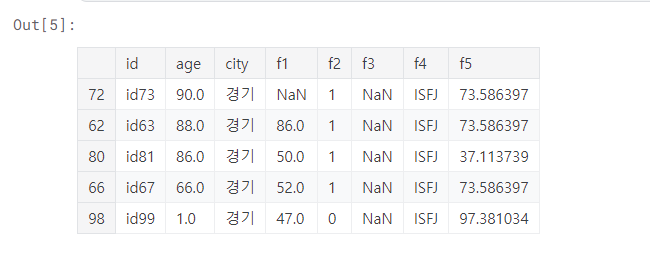
sort_value(by = 'age', ascending=False)를 통해, age 컬럼을 오름차순으로 정리하였다.
가장 위에있는 id73이 90.0세로 최댓값이다.
#method2
df[(df['f4'] == 'ISFJ') & (df['city'] == '경기')]['age'].max()['age'].max()로 최댓값만 구했다.
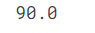
출처: https://www.kaggle.com/datasets/agileteam/bigdatacertificationkr

gpt로 다시 배우는 개발