
이전 포스팅:
테스트 범위
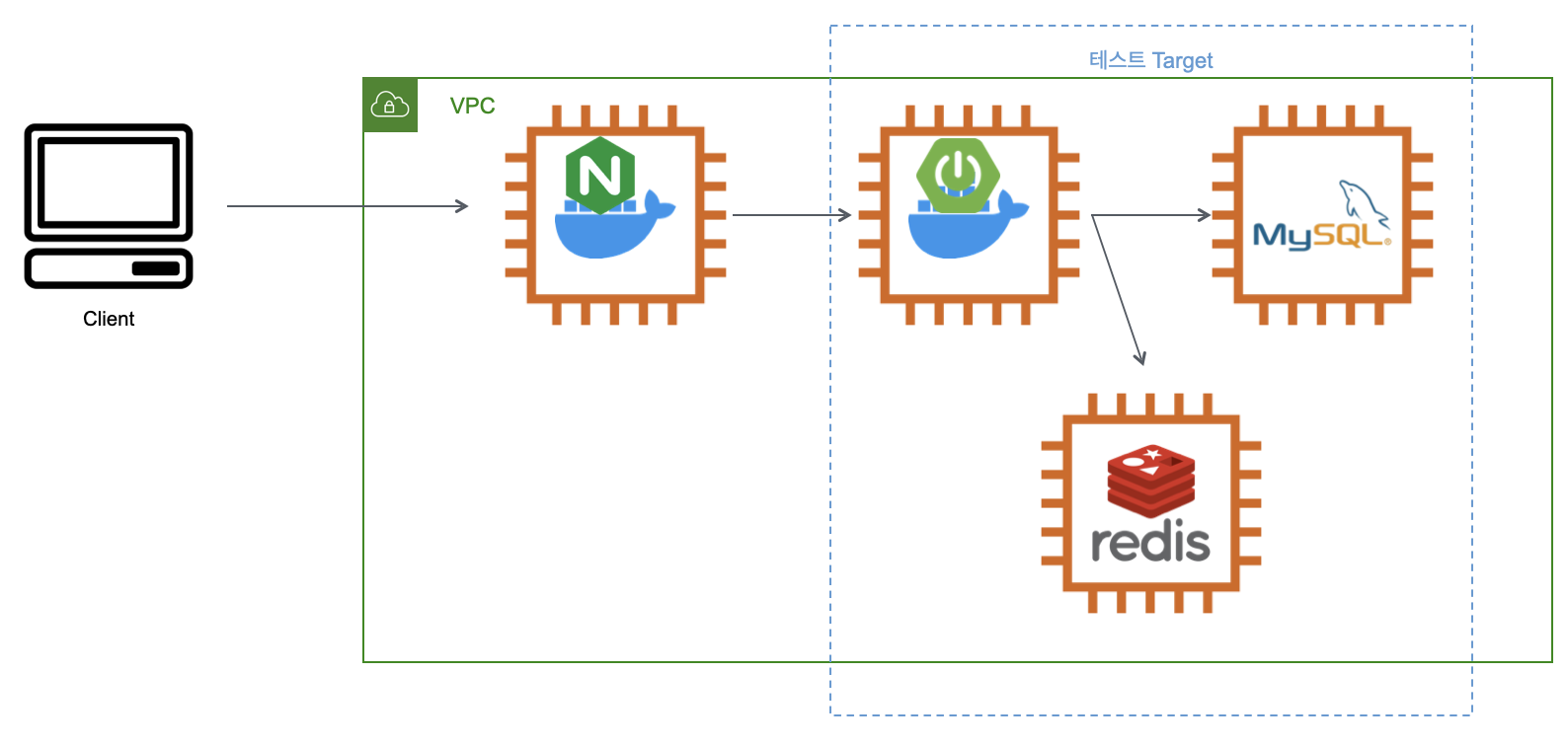
데이터 개수
- 각 테이블 당 20만개
🔎 사전 지식
nGrinder를 통해 테스트를 진행하면 아래와 같은 형식의 그래프를 결과값으로 볼 수 있습니다.
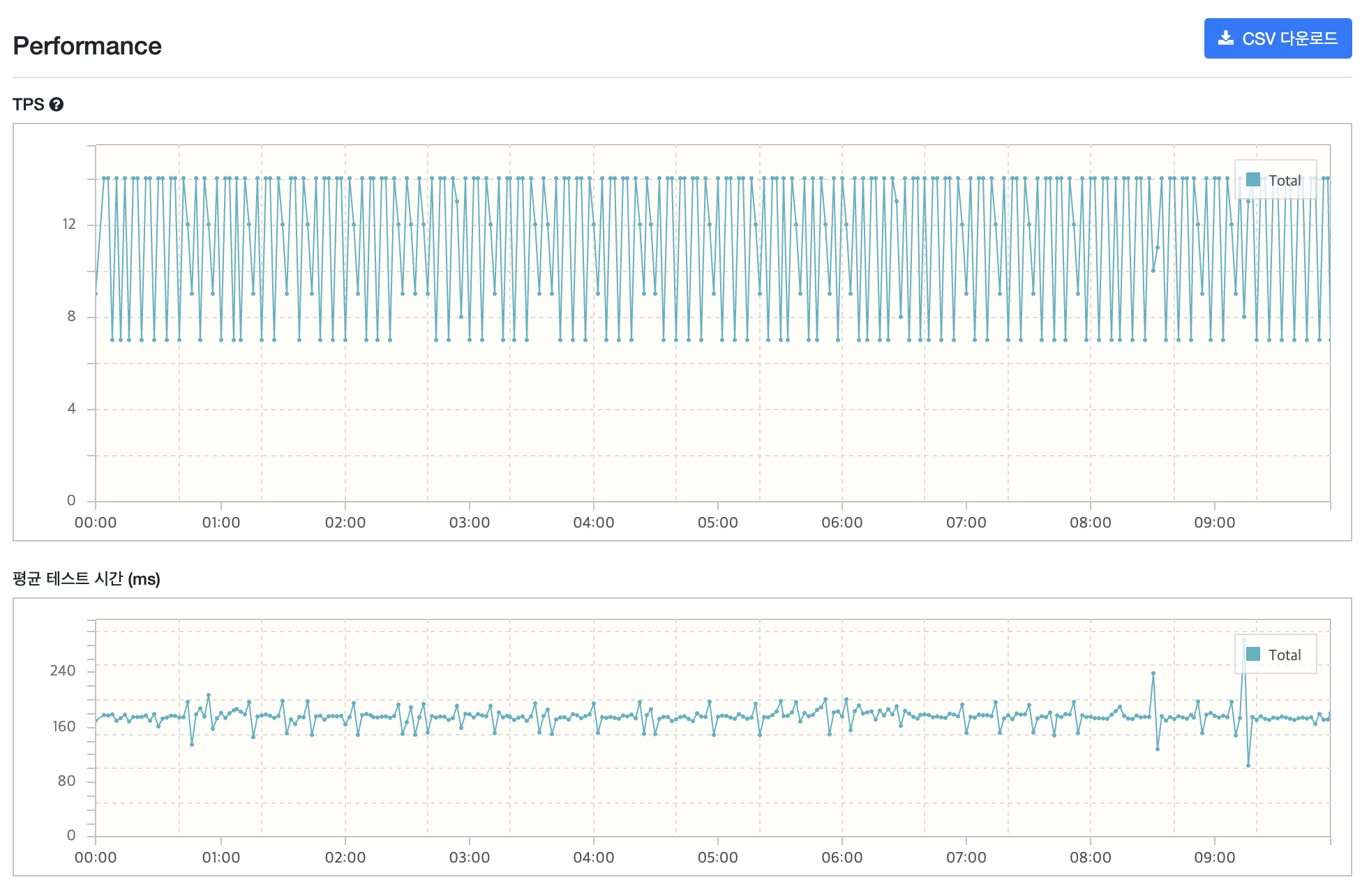
nGrinder의 TPS는 Test Per Seconds의 약자로 초당 몇 번의 테스트가 일어났는지를 뜻합니다.
위의 그래프 중 TPS 그래프는 초당 몇번의 테스트가 일어났는지를 나타냅니다.
이상적으로 TPS는 VUser가 증가하는 것에 비례해서 늘어납니다. 그러다가 어느 시점에 TPS가 더 이상 증가하지 않게 되는데 이 지점에 도달하는 순간 사용자의 응답시간에 영향을 미칩니다.(이 지점에서 오히려 TPS가 떨어질 수도 있는데 이 경우 서버 튜닝이 제대로 되지 않은 것입니다.) 처리해야할 요청은 늘어나는데 처리량은 멈춰있기 때문입니다.
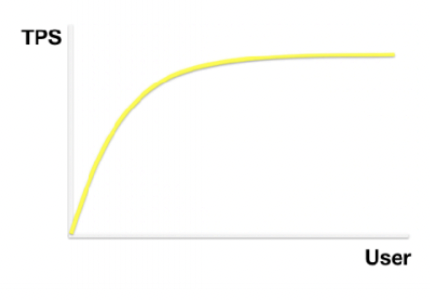
이런경우 scale up이나 scale out으로 TPS를 증가시킬 수 있습니다.
두번째 그래프인 평균 테스트 시간 그래프는 한 번의 요청부터 응답까지 몇 초가 걸렸는지를 나타냅니다.
이 두 가지 요소를 중점적으로 살펴보면 됩니다.
하지만 이 그래프에는 문제가 하나 있습니다. 위의 그래프들은 시나리오에 포함된 모든 요청에 대한 평균값을 나타냅니다. 따라서 제 시나리오를 예시로 들면 시나리오 안에 총 7개의 요청이 있기 때문에 7개 요청의 평균값을 그래프로 나타낸 것입니다. 따라서 특정 요청에 대한 결과를 보기는 힘듭니다.
이는 로그 파일이나 CSV 파일을 통해 파악할 수 있습니다.
로그 파일 & CSV 파일 활용하기
로그 파일은 테스트가 끝난 후 확인할 수 있습니다.

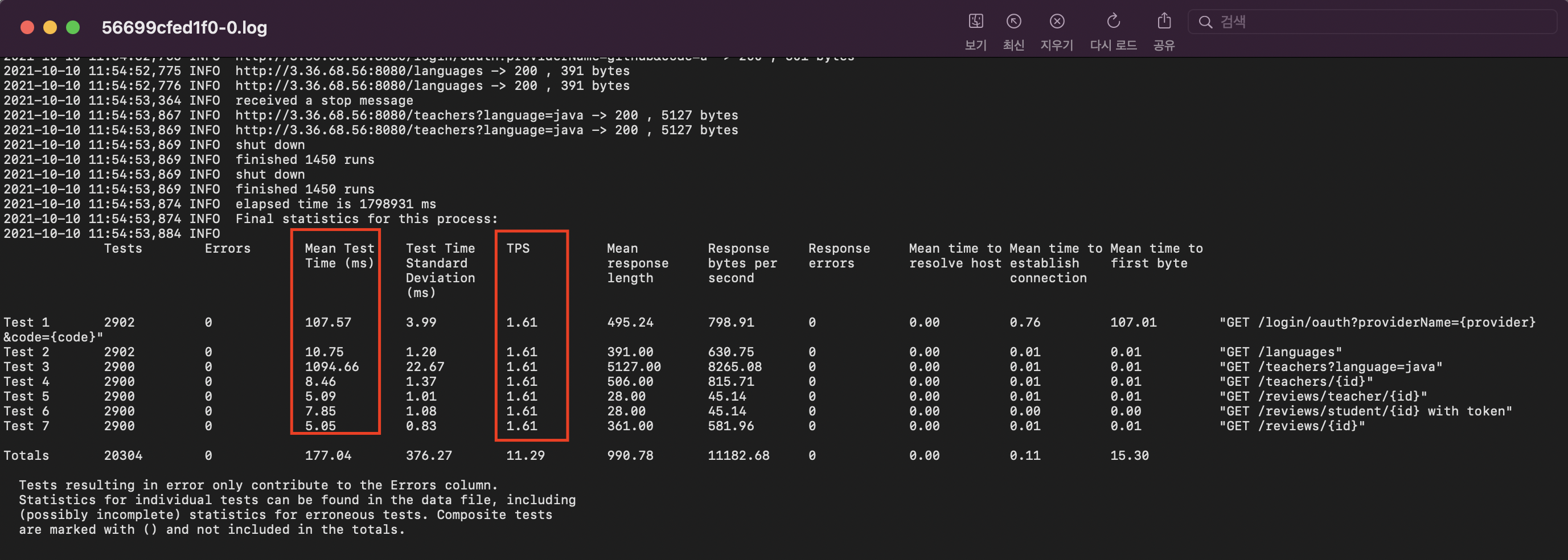
좀 더 자세한 정보는 CSV 파일로 확인할 수 있습니다. CSV파일은 상세보고서를 클릭 하신 후, 우측 상단의 CSV 다운로드를 누르시면 다운받을 수 있습니다.
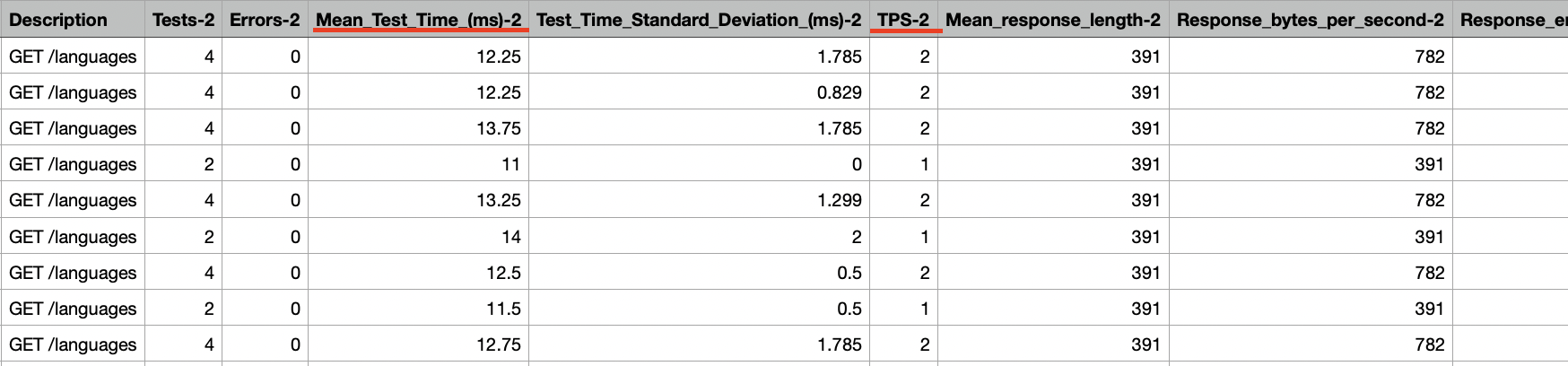
CSV 파일은 각 가로로 각 요청당 결과값을 볼 수 있습니다. Description부터 다음 요청의 Description 전까지가 해당 요청의 결과값입니다. TPS-${요청번호}, Mean_Test_Time_(ms)-${요청번호}와 같은 형식으로 해당 요청의 결과를 볼 수 있습니다. CSV의 세로는 시간을 나타냅니다.
Pinpoint 활용하기
각 요청에 대한 처리 시간은 Pinpoint를 활용하여 자세히 확인할 수 있습니다.
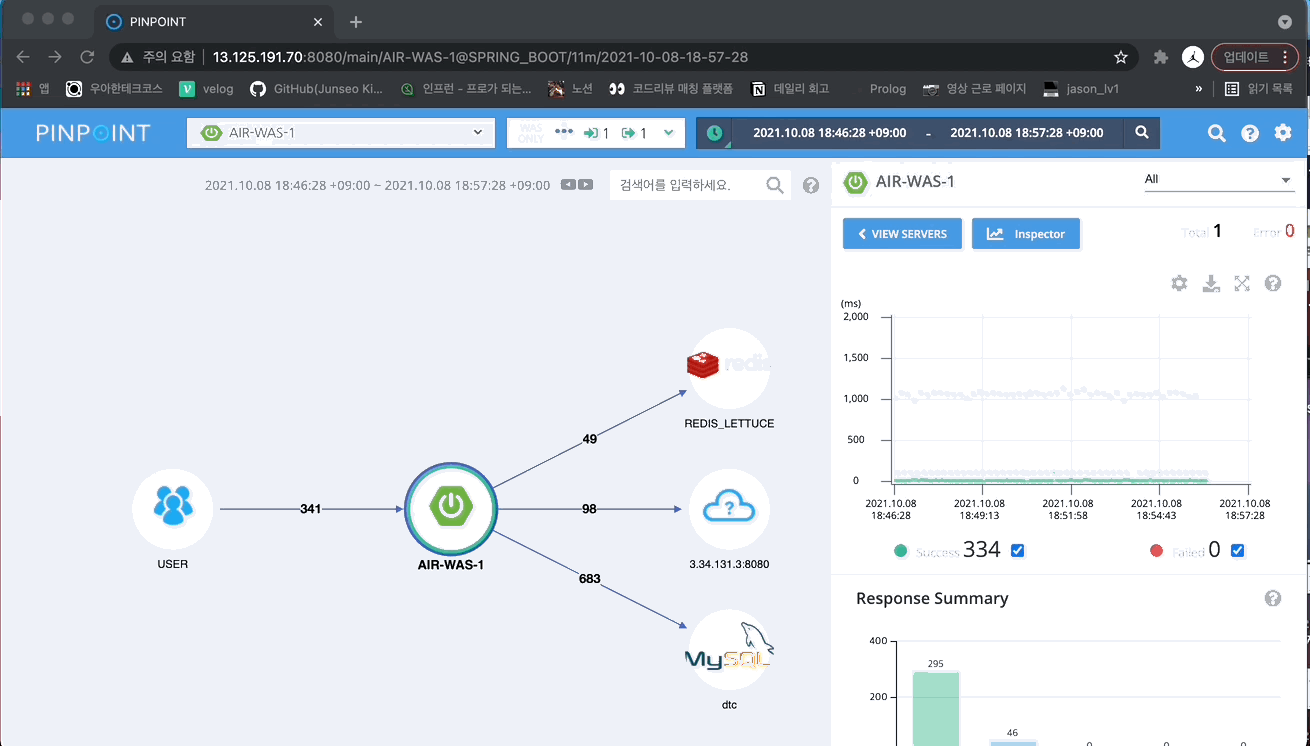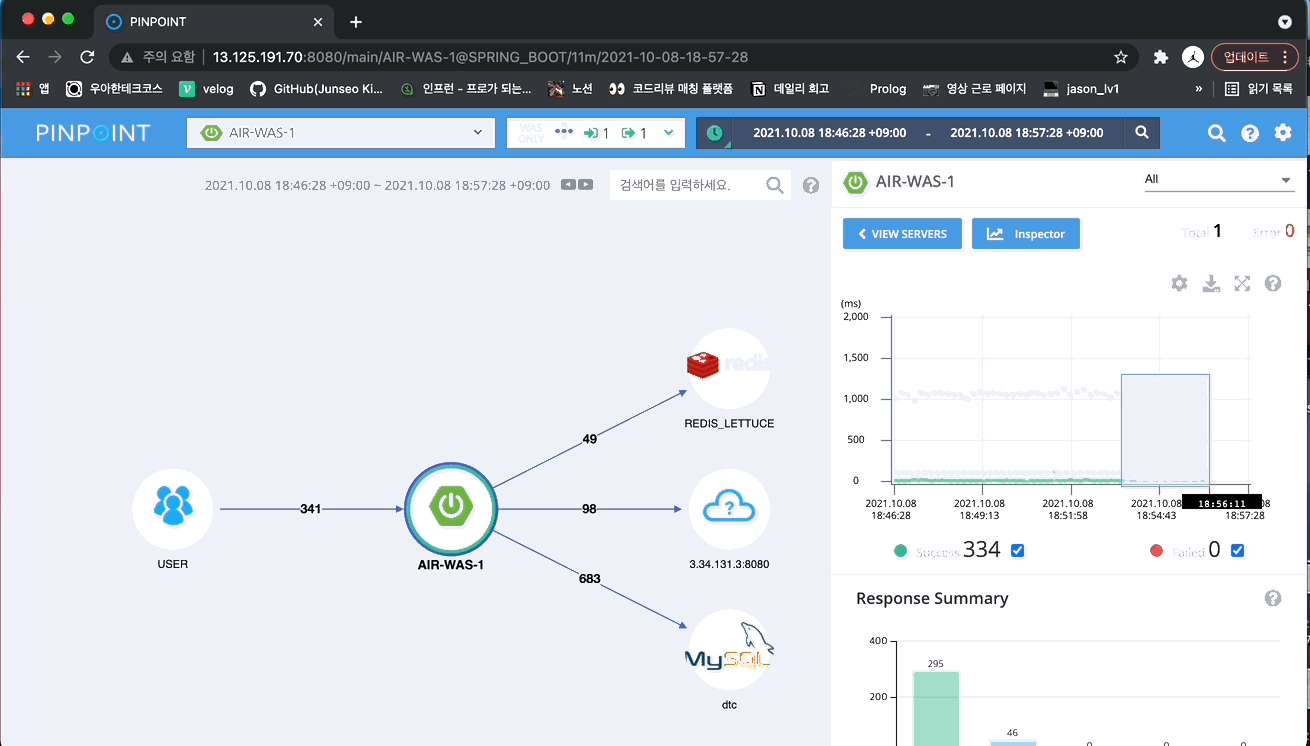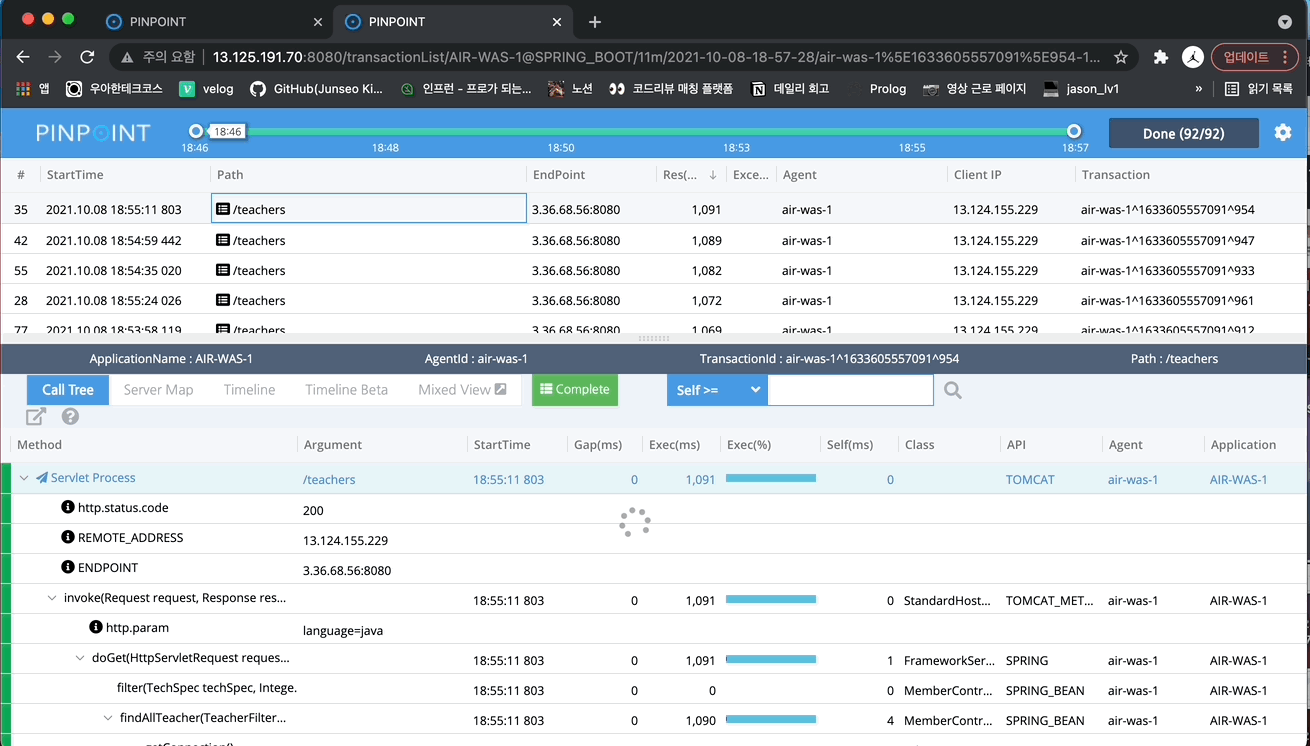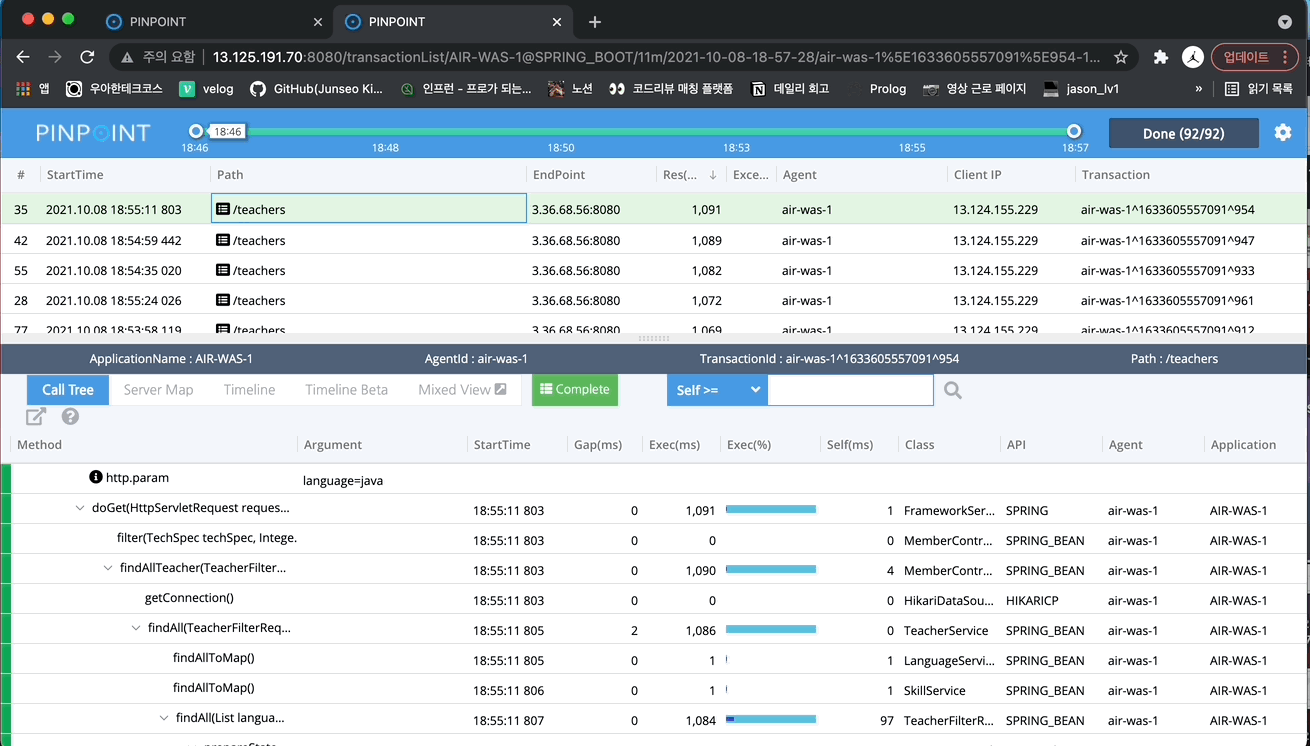
부하 테스트를 진행한 시간대를 설정해주면 아래와 같이 시간대에 따른 요청을 초록색 점으로 나타냅니다. 하나의 점이 하나의 요청입니다.
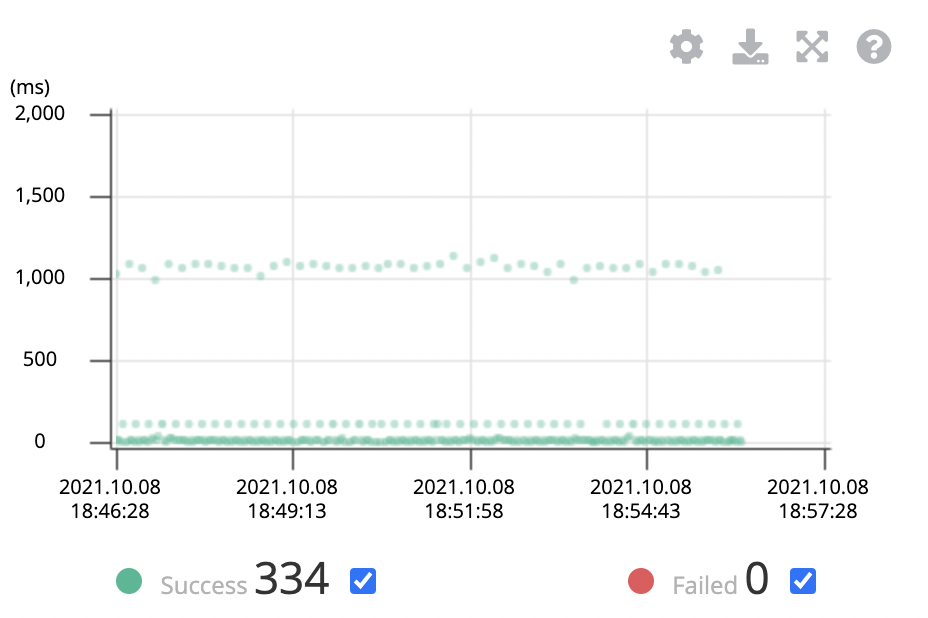
초록색 점들을 드래그 해보면 각 요청에 대한 세부 정보(각 메서드 당 실행 시간 등)를 확인할 수 있습니다.
📈 Smoke Test
최소한의 부하를 견딜 수 있는지 smoke 테스트를 먼저 진행해보겠습니다. 최소한의 부하이므로 테스트 시간은 10분 정도만 진행하겠습니다. 스크립트는 이전 포스팅에서 작성한 스크립트를 이용합니다.
- VUser: 2
- 테스트 시간: 10분
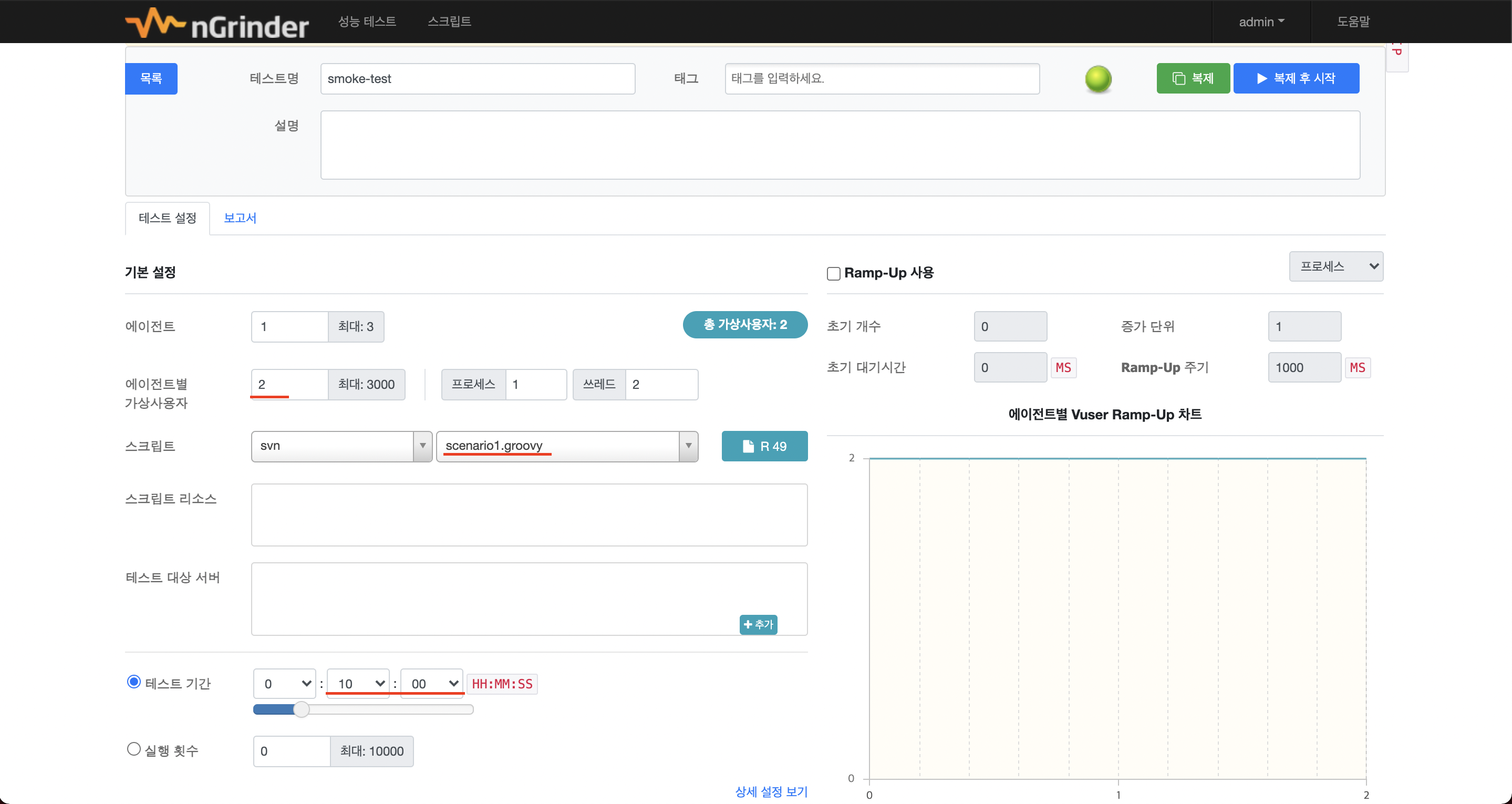
목표는 아래와 같습니다.
TPS(Throughput): 11.3 ~ 34 이상- MTT(Latency): 50 ~ 100ms 이하
결과
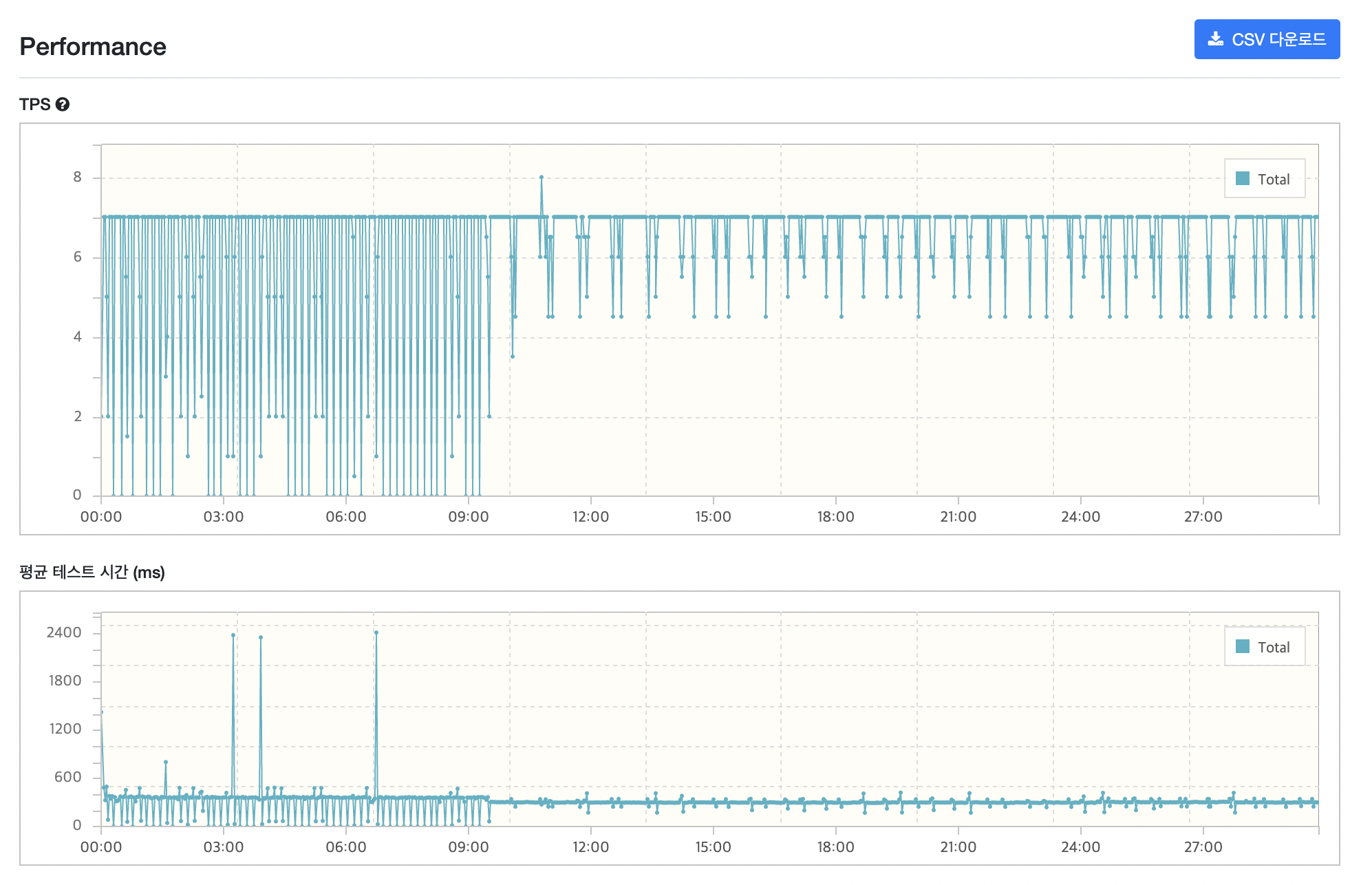
(앞 부분 그래프는 제가 예열을 하지 않고 바로 돌려서 발생한 부분 같습니다ㅎㅎ.. 10분 경부터 보시면 될 것 같습니다.)

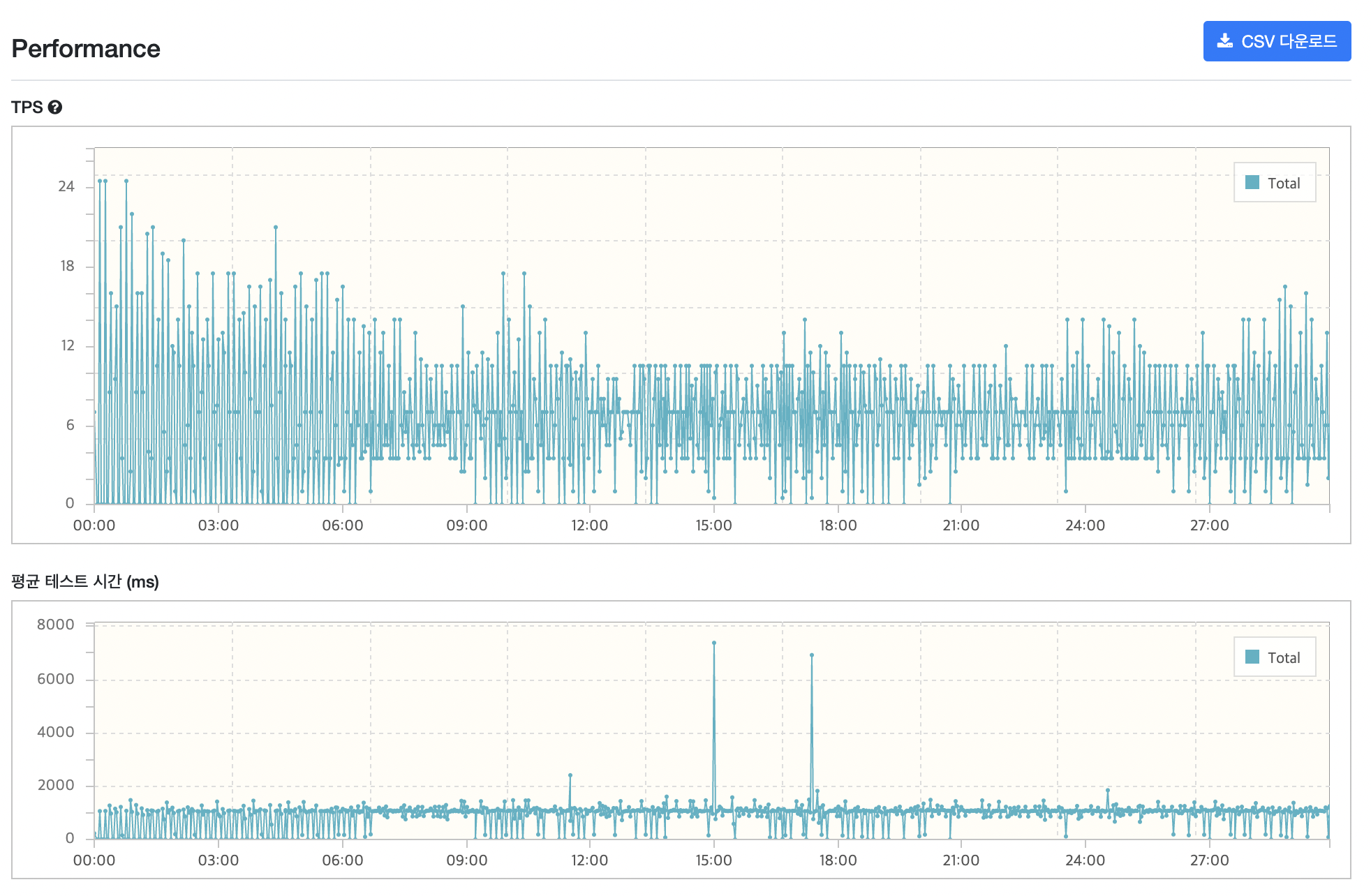
TPS는 데이터의 개수가 많아서인지 VUser가 2명 밖에 안되는데 생각보다 낮게 나왔습니다. WAS에서 병목이 일어난건지, DB에서 병목이 일어난건지 잘 모르겠지만 데이터의 수가 많기 때문에 DB쪽이 아닐까 추측이 듭니다. 데이터 수가 많아서 테스트 요청 자체도 적게 가고 따라서 TPS 값이 낮게 나온다고 생각이 들어 DB Replication 등 DB 관련 최적화를 진행해보고 다시 측정해보겠습니다.
TPS는 분명 각 요청 마다 처리량이 다를텐데 왜 모든 요청이 같게 나왔을까요? 시나리오는 1번부터 7번까지 차례대로 수행되는데, 중간에 오래걸리는 요청이 있는 경우 다른 요청이 빨리 끝나는 요청이라고 해도, 한 묶음으로 수행되므로 테스트 자체의 수가 적게 발생하여 모든 요청의 TPS가 같게 나온 것입니다.. 그래서 TPS 지표가 크게 의미가 없게 되었습니다..
제가 이렇게 테스트를 해보면서 느낀점이 시나리오 자체를 짧게 가져가거나, 아니면 각각 API 별로 테스트해보는게 더 효과적일 것 같다는 생각을 하게되었습니다.(아마 다음에 성능 테스트를 할 땐 그렇게 할 것 같네요 😭)
MTT를 위주로 살펴보겠습니다. 다른 요청들은 괜찮은데, 3번째 요청인 리뷰어 목록을 조회하는 요청의 시간이 많이 걸리는 것을 볼 수 있습니다.
Pinpoint도 한 번 살펴보겠습니다.
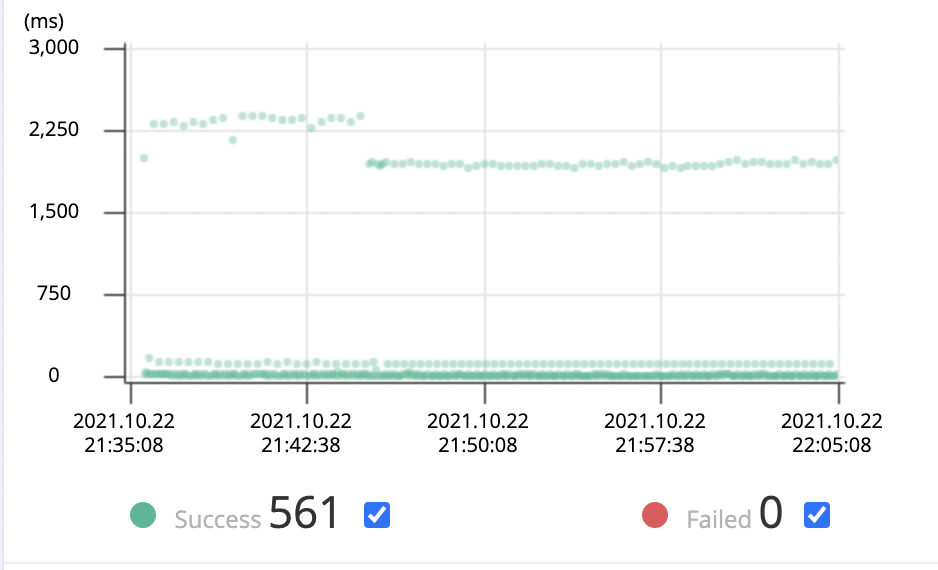
대부분의 요청은 100ms 아래로 보여지는데, 특정 요청들이 2000ms 정도 걸리는 것을 볼 수 있습니다. 위의 로그 파일에서 살펴본 리뷰어 목록을 조회하는 요청이라고 추측됩니다. 드래그를 해서 한 번 살펴보겠습니다.
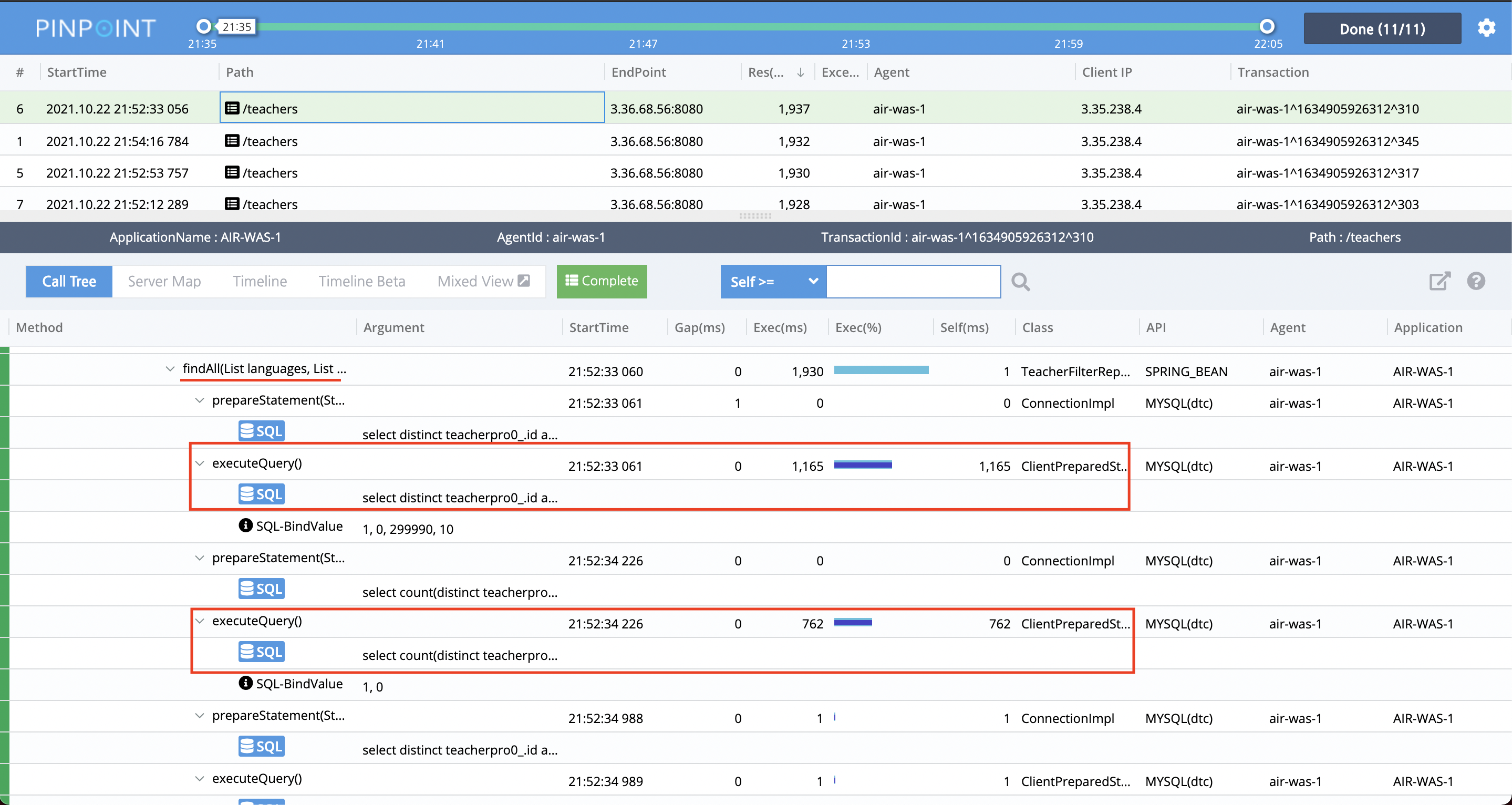
TeacherFilterRepository 클래스의 findAll()메서드에서 시간이 오래걸리는 것을 파악할 수 있습니다. 이 조회 쿼리를 개선해야 해당 요청의 성능이 좋아질 것이라는 것을 알 수 있습니다.
TODO
- findAll 조회 쿼리 개선
📈 Load Test
평균 트래픽일 경우와 최대 트래픽일 경우를 나눠서 테스트해보겠습니다. 테스트 시간은 30분으로 진행합니다.
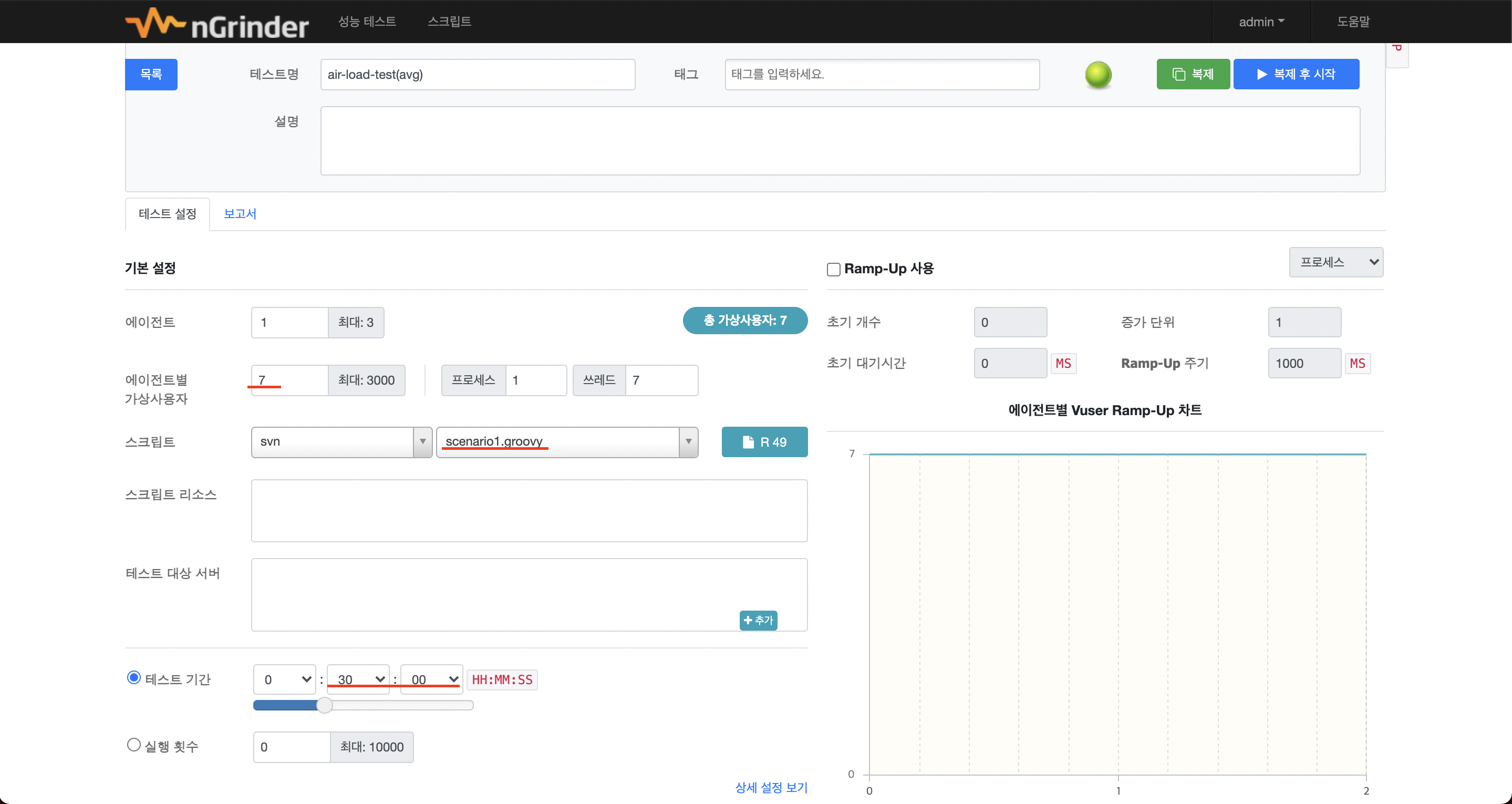
평균 트래픽
- VUser: 7
- 테스트 시간: 30분
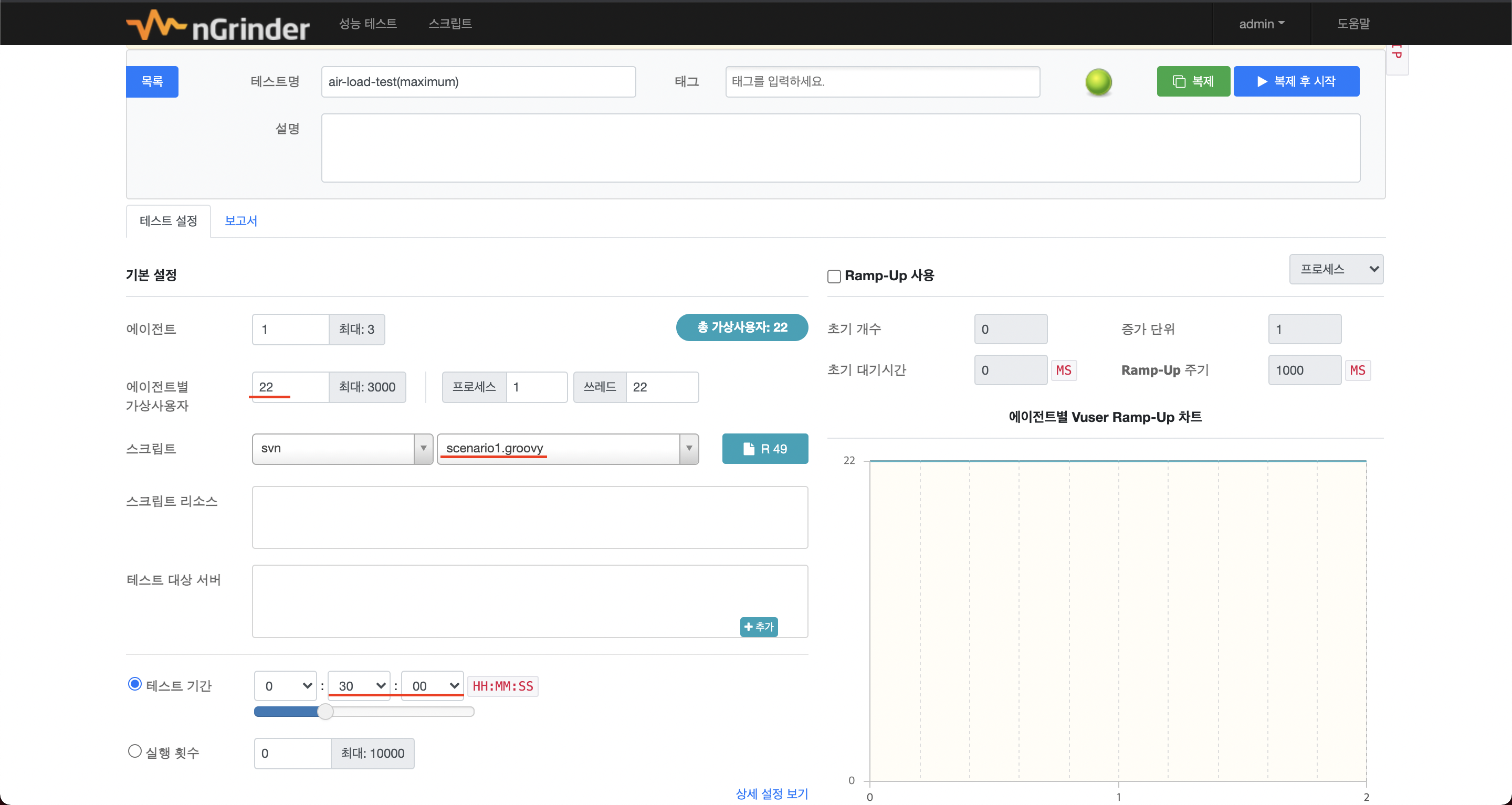
최대 트래픽
- VUser: 22
- 테스트 시간: 30분
두 테스트 모두 목표는 아래와 같습니다.
TPS: 11.3 ~ 34 이상- MTT: 50 ~ 100ms 이하
- 성능 유지 기간: 30분
평균 트래픽 결과

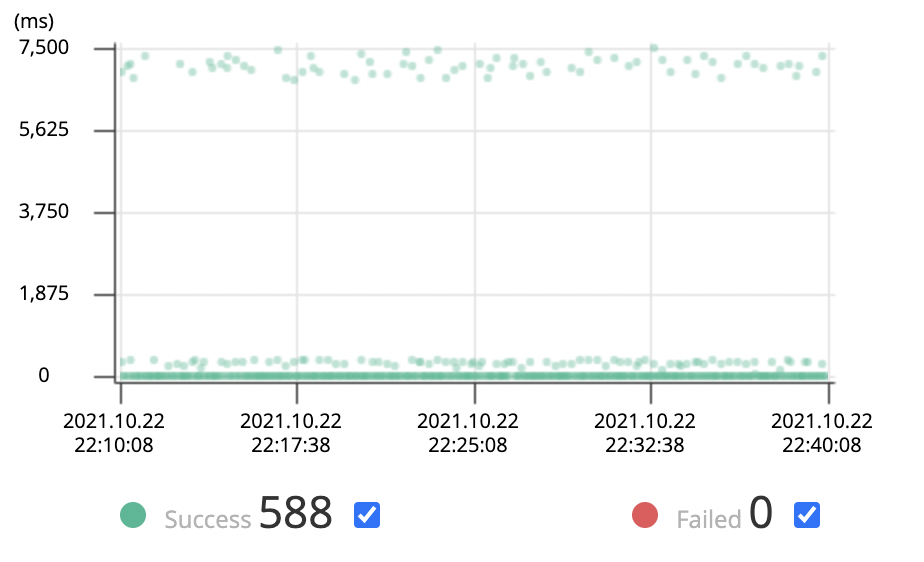
이미 smoke 테스트에서도 문제가 있었던 리뷰어 목록을 조회하는 요청이 엄청난 시간이 걸리게 되었고, 로그인 요청도 꽤 시간이 늘어났습니다.
Pinpoint로도 살펴보겠습니다.
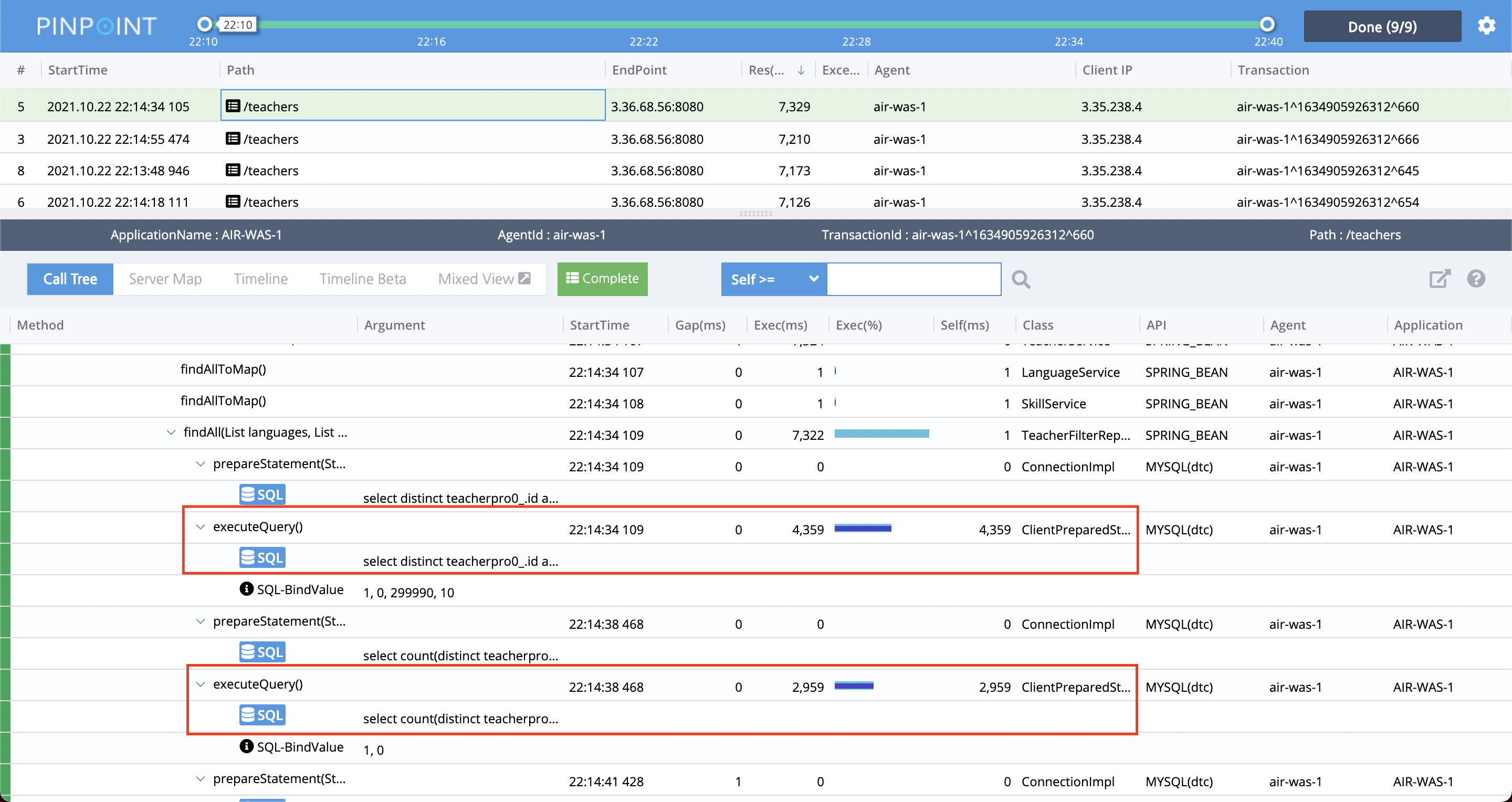
TeacherFilterRepository 클래스의 findAll()메서드의 문제가 심각하다는 걸 알 수 있습니다.
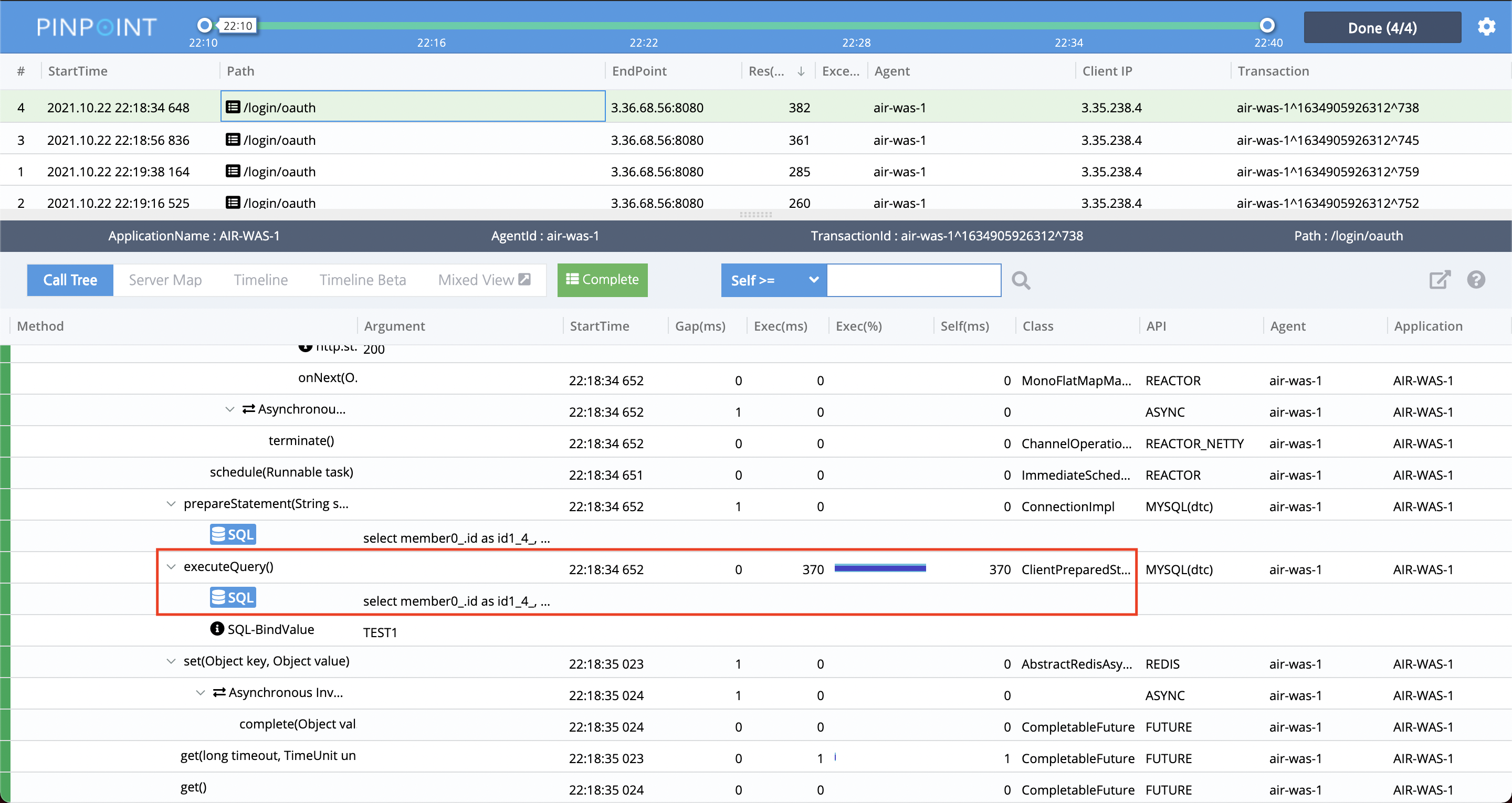
로그인 과정에서 일어나는 조회쿼리 또한 개선이 필요해보입니다.
최대 트래픽 결과
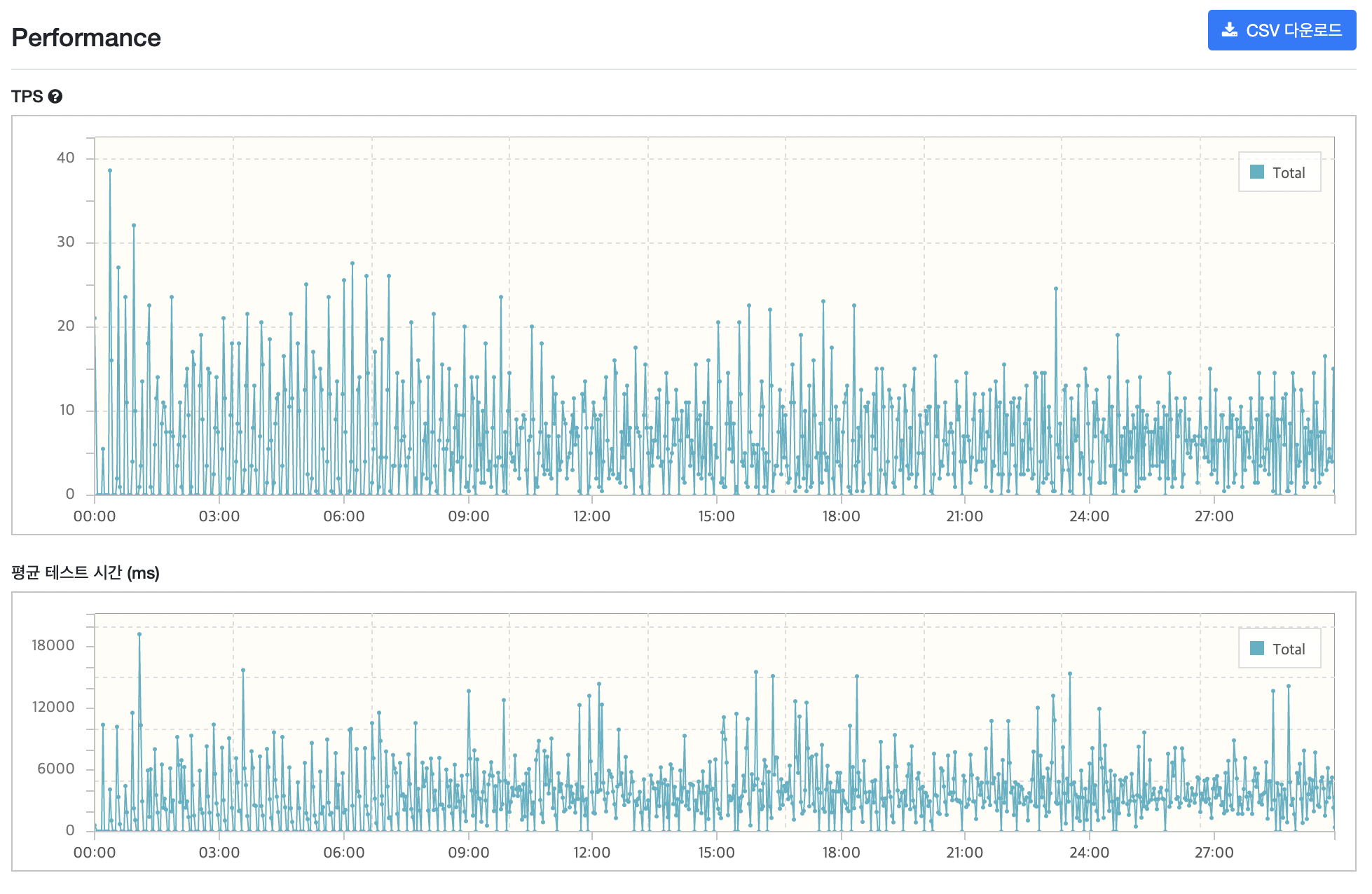
(이유는 모르겠지만 요약 로그 파일도 따로 나오지 않았네요.)
Pinpoint를 살펴보겠습니다.
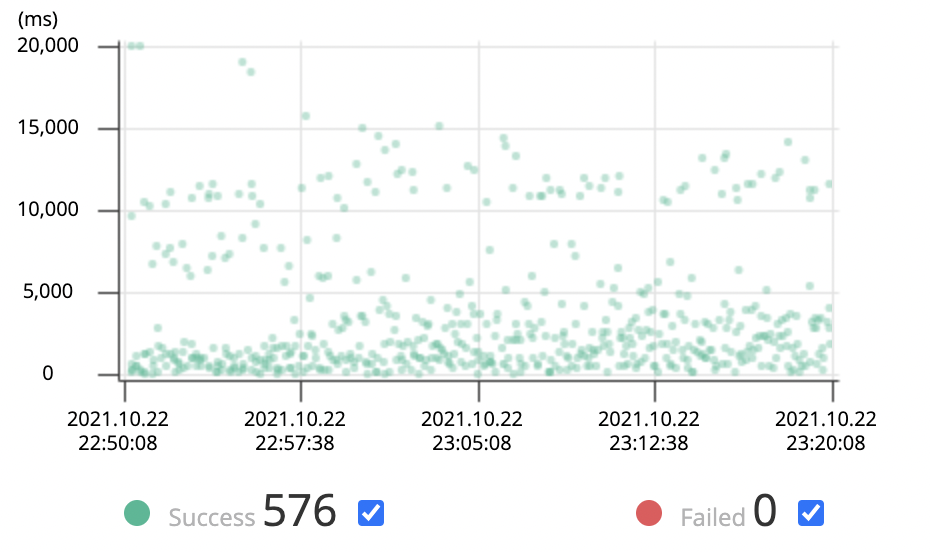

운영 중 최대 트래픽(가정)일 경우 전반적으로 모든 요청의 시간이 목표를 오버해버렸습니다.. 🤦🏻♂️
당연히 이미 문제가 되었던 쿼리는 더 성능이 안좋아졌고, 새로운 문제도 찾을 수 있었습니다. connection 과정에서 많은 비용이 소모되는 걸 볼 수 있었습니다. 다른 요청들도 모두 시간이 늘어났으므로 모두 확인해보니 findAll과 login을 제외한 요청은 전부 connection에서 비용이 확 증가한 것이었습니다. connection pool도 조정해야겠습니다.
TODO
- findAll 조회 쿼리 개선
- login 내부 조회 쿼리 개선
- connection pool 조정
🛠 개선 목표
smoke 테스트와 load 테스트를 통해 개선해 나갈 방향을 잡아보았습니다.
- connection pool 조정
- findAll 조회 쿼리 개선
- login 내부 조회 쿼리 개선
- DB replication 적용
다음 포스팅에서는 개선을 통해 smoke, load 테스트 결과가 어떻게 바뀌는지 알아보겠습니다. 개선을 통해 어느정도 만족할 만한 결과가 나온다면 stress 테스트를 통해 한계점을 찾아보겠습니다.
Reference
- 우아한테크코스
- TPS 지표 이해하기
