
⭐AI vs ML(Machine Learning) vs DL(Deep Learning)
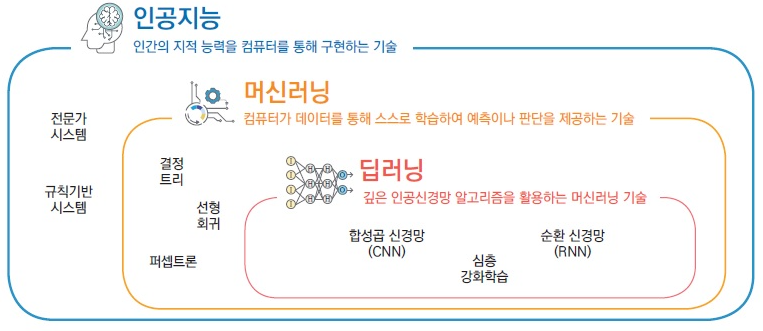
AI는 인간의 지능을 인공적으로 만든 것
ML은 data를 기반으로 기계가 학습하는 것
DL은 DNN(Deep Neural Network)을 기반으로 기계가 학습하는 것
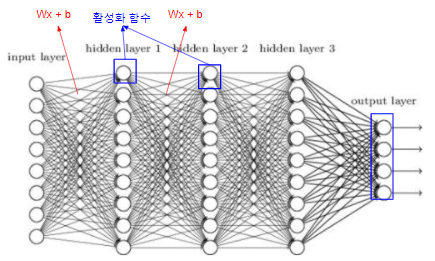
DNN(Deep Neural Network)
DNN이란 입력층(input layer)과 출력층(output layer) 사이에 여러 개의 은닉층(hidden layer)들로 이뤄진 인공신경망(Artificial Neural Network, ANN)
✔지도 학습, 비지도 학습, 자기 지도 학습
⭐ 지도 학습
지도 학습은 정답(label)을 알려주며 학습하는 것
예) 회귀(regression), 분류(classification)
🔎회귀(regression)
어떤 데이터들의 특징(feature)을 토대로 값을 예측하는 것.
관찰된 연속형 변수들에 대해 두 변수 사이의 모형을 구한 뒤 적합도를 측정해 내는 분석 방법
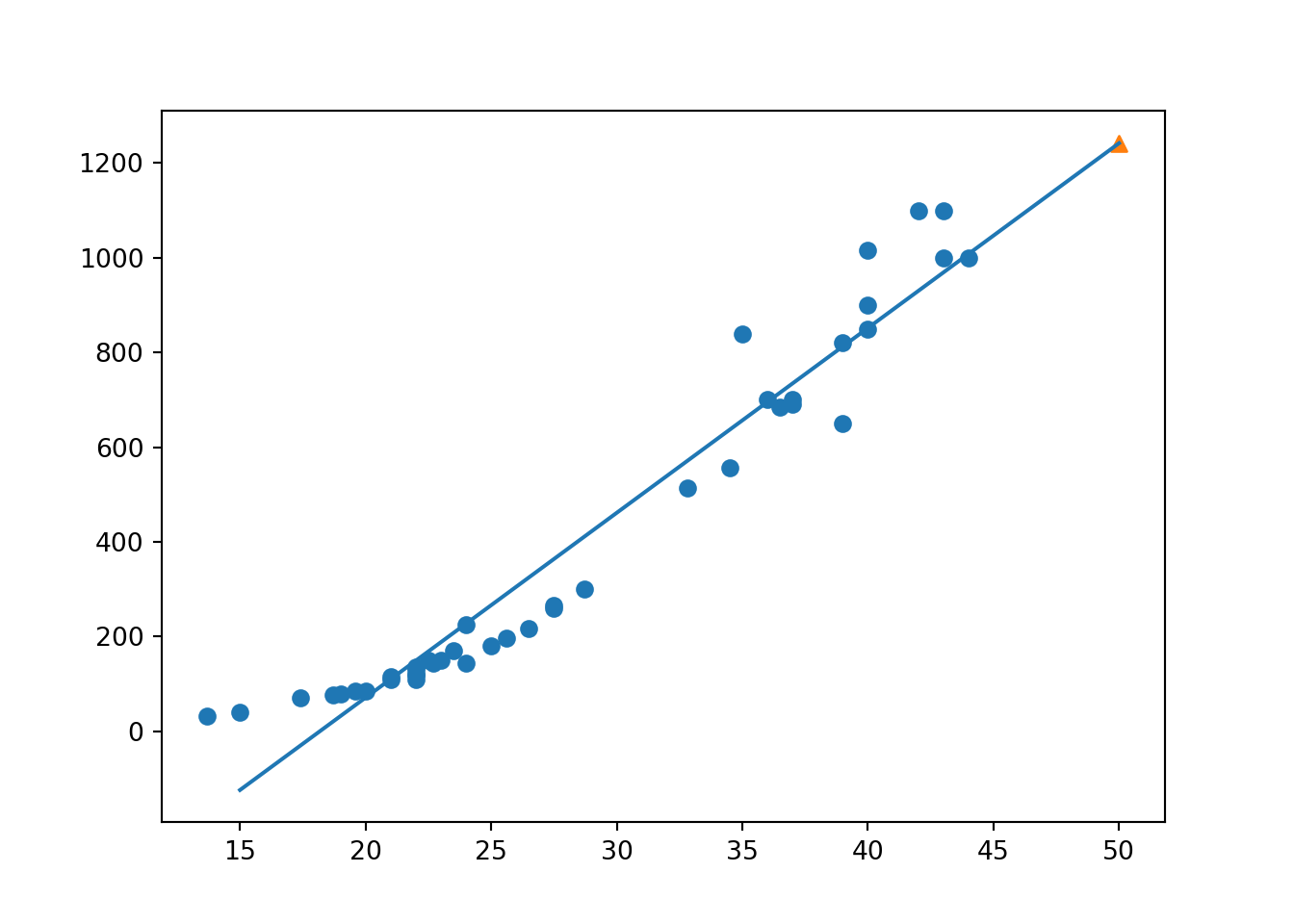
ex) 온실가스 변화에 따른 지구 기온의 변화나 공기 중 평균 습도 변화에 따른 개화 시기
집의 크기, 위치에 따른 가격 사이의 관계를 이용하여 주어진 크기의 집 가격을 예측
회귀 알고리즘 종류
Linear Regression,Locally Weighted Linear,Ridge,Lasso
🔎분류(classification)
- 이진 분류
이진 분류(Binary Classification)란 규칙에 따라 입력된 값을 두 그룹으로 분류하는 작업
참(True) 또는 거짓(False)의 형태orA 그룹 또는 B 그룹으로 데이터를 나누는 경우
분류 결과가 맞다면 1(True, A 그룹에 포함)을 반환하며, 아니라면 0(False, A 그룹에 포함되지 않음)을 반환
- 다중 분류
다중 분류는 3개 이상의 결과값을 예측하는 모델
ex) Q: 이 동물은 뭐야?
A: 고양이(or 개 or 원숭이 등등)
분류 알고리즘 종류
kNN, Naive Bayes, Support Vector, Machine Decision
⭐ 비지도 학습
비지도 학습은 지도 학습과 달리 정답(label)을 알려주지 않는다.
인공지능(AI)이 입력 세트에서 패턴과 상관관계를 찾아내야 하는 머신러닝 알고리즘
예) 군집화(K-means, DBSCAN, ...), 차원 축소(PCA, SVD, ...)
⭐ 자기 지도 학습
자기지도 학습은 레이블이 지정되지 않은 샘플 데이터에서 학습을 진행한다. 지도학습과 비지도 학습의 중간 형태이다.
대량의 labelled data 특히 high-quality의 labelled data를 얻는 것은 비용이 많이 들기 때문에 가짜 문제를 정의해서 먼저 풀어본 후 원래의 문제(지도 학습 or 비지도 학습)을 진행한다는 점이 핵심이다.
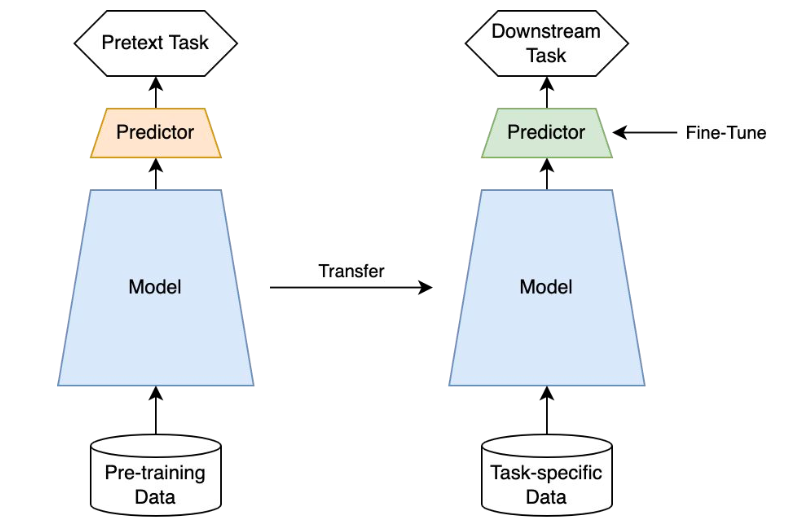
자기지도 학습은 Self-prediction과 Contrastive learning으로 나눌 수 있다.
🔎Self-prediction
하나의 data sample내에서 한 파트를 통해서 다른 파트를 예측하는 task를 말한다.
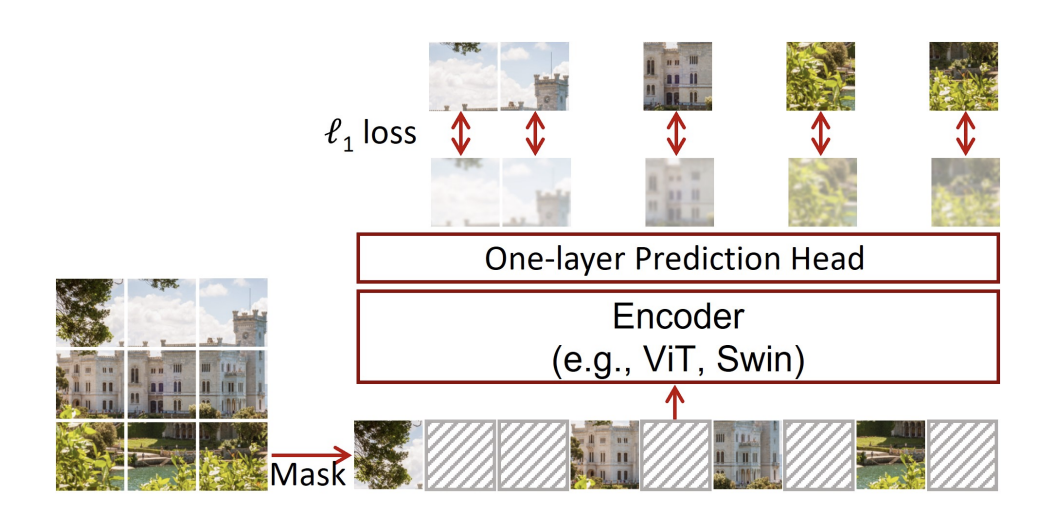
Self-prediction 모델 예시)
①Autoregressive generation (gpt가 사용하는 알고리즘)
②Masked generation
③Innate relationship prediction
④Hybrid self-prediction
🔎Contrastive learning
batch(나눠진 데이터 셋)내의 data sample들 사이의 관계를 예측하는 task를 말한다.
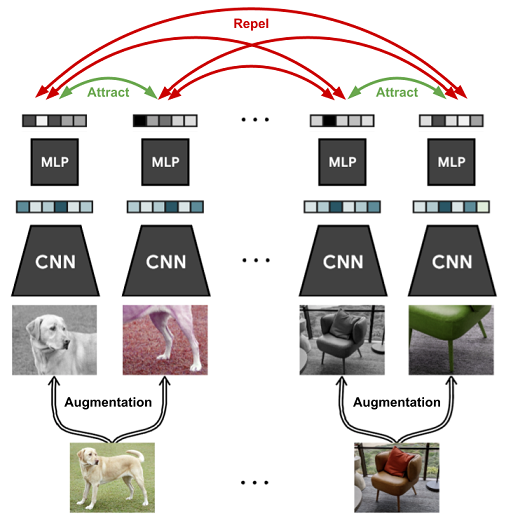
Contrastive learning 모델 예시)
①Background and theories
②Inter-sample classification
③Feature clustering
④Non-contrastive methods
자세한 예시 설명은 https://sanghyu.tistory.com/184 에 나와있다.
✔ 강화 학습
⭐ 강화 학습
강화 학습은 행동에 대한 보상을 받으면서 학습하여 주어진 환경에서 가능한 행동 중 가장 보상이 좋은 행동을 선택하는 방법이다. 강화 학습의 예로는 알파고가 있다.
🔎강화 학습의 용어
Agent : 주인공, 학습하는 대상으로, 환경속에서 행동하는 개체를 말한다. (ex. 개, 로봇, 플레이어)
Action : Agent가 실제 행동한 내용을 말함. Policy에 의해 도출되고.
Reward : Agent가 행동을 했을 때 받게 되는 보상(scalar)으로서, 특정 행동을 유발시키기 위해 positive reward를, 특정 행동을 금지시키기 위해 negative reward를 취할 수 있다. 이때 agent가 어떻게 해야 높은 보상을 받게 되는지 알려주면 안 된다.(에이전트 입장에서 '어라? 이런 시도를 하니까 많이 주네?'로 느껴지게 해야 함). 또한 행동 1번에 꼭 1번 보상이 주어지지 않거나(sparse) 현재 행동이 미래의 보상에 영향을 끼칠 수도 있다.(delayed, ex. 바둑) 미래에 받게 되는 reward에 대해서는 discount을 적용하고, 보상들을 전부 더해 return을 얻을 수 있다.
Environment : Agent와 상호작용하는 환경. 강화학습은 Agent와 Environment간의 상호작용간에 일어나는 과정이다.
State value : 어떤 state에서 보상을 받고 특정 policy를 따랐을 때 받게 되는 Return의 기대값.
Exploration : 탐험. 도박. Agent가 현재 알고 있는 지식으로 행동을 하지 않고, 모르는 분야로 나아가서 정보를 얻기 위해 행동하는 것을 말한다. 예를 들어, 음식점에 갔을 때, 내가 항상 먹던 것을 먹을 것이냐, 안 먹어봤던 신메뉴를 먹어볼 것이냐가 대표적인 예이다. ϵ-greedy에서 ϵ이 모험을 할 확률을 말하며, Q가 높은 action을 하는 것이 아닌 모든 action 중 랜덤하게 골라서 action함. model-free한 상황에서 local optimality에 빠지는 걸 방지.
Discount rate(factor) ; 할인율, 감쇄율. 감마로 표현.0≤γ(gamma)≤1 지금 100만원을 받거나 1달 뒤에 100만원을 받는 두 가지 경우 중 하나를 고른다고 하면, 당연히 전자를 고를 것이다. 이처럼 Agent가 미래에 받는 보상은 할인율을 적용하여 학습하여야 최단경로를 학습해 나갈수 있음. 예를 들어, 매번 움직일 때마다 reward를 +1씩 해준다면, Reward는 무한이 될수 있으나, 감쇄율을 한 step씩 이동할 때마다 reward에 곱해줘서, 두 스텝뒤의 보상은 할인율의 제곱이 곱해진 reward가 됨.
(출처: https://namu.wiki/w/%EA%B0%95%ED%99%94%ED%95%99%EC%8A%B5/%EC%9A%A9%EC%96%B4)
🔎강화 학습 알고리즘: MDP(Markov Decision Process)
MDP(Markov Decision Process)는 강화 학습에서 보상을 최대화할 수 있는 방향으로 행동할 수 있도록 이용과 탐험 사이에 적절한 균형을 맞추는 데 사용되는 의사결정 프로세스이다.
출처(Reference)
https://blog.naver.com/PostView.nhn?
https://sanghyu.tistory.com/184
https://namu.wiki/w/%EA%B0%95%ED%99%94%ED%95%99%EC%8A%B5/%EC%9A%A9%EC%96%B4
