
📖 작성한 크롤링 코드를 Airflow에 DAG로 옮겨보는 작업을 해보자!0️⃣ Task 구성하기
✅ 코드가 동작되는 순서를 정리해보고, 이에 따라 task를 구성해보자.
- velog.io 메인 페이지에 접속되는지 확인한다.
- 메인페이지에 접속된다면 selenium으로 트렌딩 글 url을 받아와서 csv로 저장한다.
- airflow XCom에 csv 파일을 저장한다.
- 각 url에 접속해서 블로그 내용을 긁어와서 csv로 저장한다.
- url이 저장된 csv를 XCom에서 불러온다.
- 긁어온 내용을 csv 파일에 업데이트한다.
- 변경된 csv 파일을 다시 airflow XCom에 저장한다.
- 종료
✅ 실제 task는 다음과 같이 구성했다.
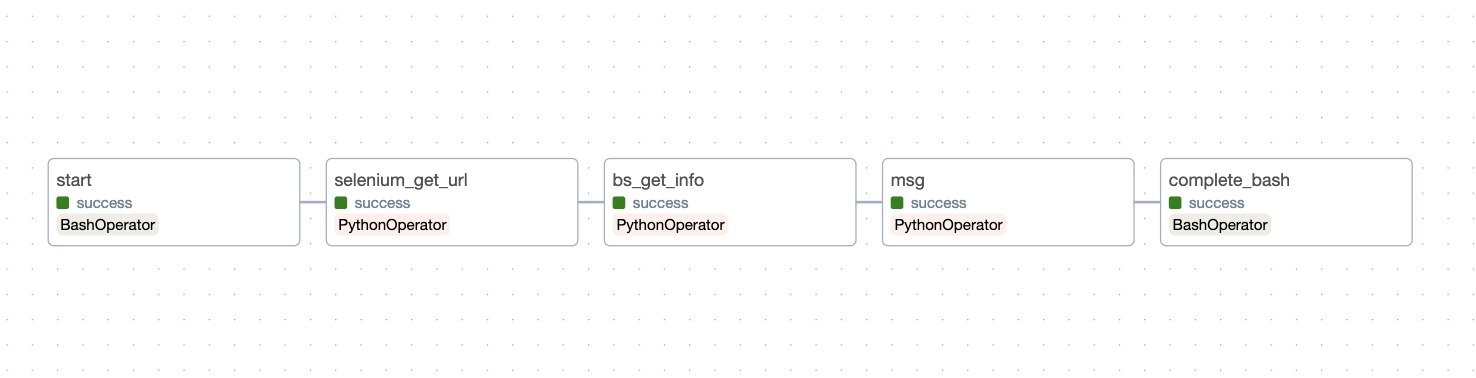
- 시작 (start)
- selenium으로 url 받아오기 (get_url_task)
- bs4로 글 정보 받아오기 (get_info_task)
- 최종적으로 가져온 글의 개수 출력하기(msg)
- 종료(complete)
1️⃣ 기본 파일 & 디렉토리 구조
웹서버를 실행하거나 DAG를 실행하면 자동으로 생성되는 파일들은 다음과 같다
저번에 정리를 못 해서 이제 하는 건 안 비밀😉
🔎 실습 환경 : AWS EC2에서 가상환경(virtualenv)로 작업
- webserver_config.py
: 웹서버 설정(configuration)을 위한 파일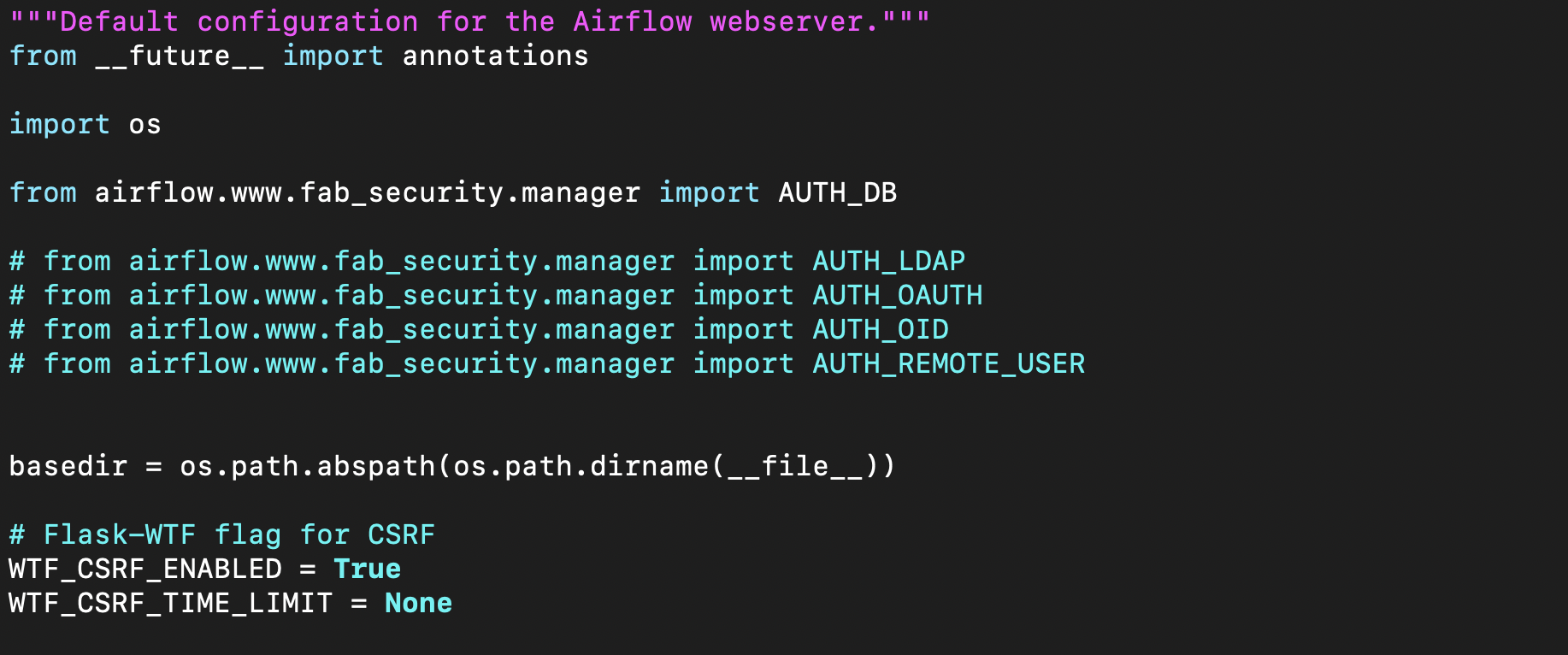
- airflow-webserber.pid
: webserver GUI가 실행되고 있는 프로세스의 ID를 저장
( shell 명령어lsof -i tcp:8080으로도 PID를 확인할 수 있다.)

- airflow.cfg
: airflow 설정(configuration)을 위한 파일. dags 폴더 경로 등을 지정할 수 있다.
( load_examples를 False로 해둬야 webserver에서 예제 dag가 안 보인다)

- airflow.db
: SQLite DB file, 어떤 DAG가 존재하고 어떤 태스크로 구성되는지, 어떤 태스크가 실행 중이고 실행 가능한 상태인지 등의 메타데이터가 저장되는 데이터베이스 파일
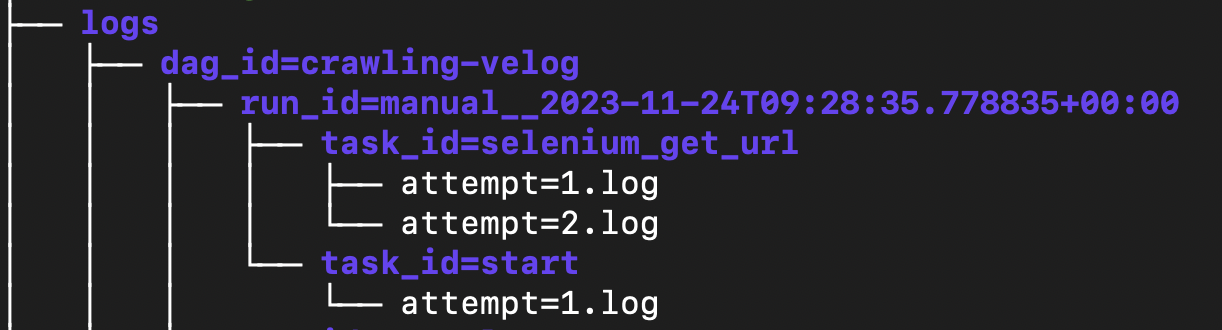
- logs 디렉토리
- dag_id에 대해, 각 run_id에 대해, 각 task_id의 DAG 실행로그
- dag_processor_manager와 schedular에 대한 log
트리 구조로 전체 파일들을 확인하면 아래와 같다.

이제 각각 task와 직접적으로 관련된 파일들을 어떻게 작성했는지 정리해보자.
2️⃣ DAG 파일 작성
- https://lsjsj92.tistory.com/633 블로그 글에 나와있는 코드를 수정해서 주로 구성하였다
처음 본다면 너무 길어서 읽기도 싫으니아래서 쪼개서 설명하였다.
🔎 전체 코드
crawling_velog_dag.py
from datetime import timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python_operator import PythonOperator
from airflow.utils.trigger_rule import TriggerRule
import sys, os
sys.path.append(os.getcwd())
from crawling.crawling_velog import *
def print_result(**kwargs):
r = kwargs["task_instance"].xcom_pull(key='result_msg')
print("message : ", r)
default_args = {
'owner': 'owner-name',
'depends_on_past': False,
'email': ['your-email@g.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=30),
}
dag_args = dict(
dag_id="crawling-velog",
default_args=default_args,
description='tutorial DAG ml',
schedule_interval=timedelta(minutes=50),
start_date=datetime.datetime(2023, 11, 24),
tags=['example-sj'],
)
with DAG( **dag_args ) as dag:
start = BashOperator(
task_id='start',
bash_command='echo "start!"',
)
get_url_task = PythonOperator(
task_id='selenium_get_url',
python_callable=get_url_list,
)
get_info_task = PythonOperator(
task_id='bs_get_info',
python_callable=crawling,
op_kwargs={'url_list':"url_list"}
)
msg = PythonOperator(
task_id='msg',
python_callable=print_result
)
complete = BashOperator(
task_id='complete_bash',
bash_command='echo "complete!"',
)
start >> get_url_task >> get_info_task >> msg >> complete🔎 라이브러리, 모듈 불러오기
DAG, 필요한 종류의 Operator들, trigger 규칙 등과 기타 라이브러리를 불러온다.
from datetime import timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python_operator import PythonOperator
from airflow.utils.trigger_rule import TriggerRule
import sys, os
sys.path.append(os.getcwd())
from crawling.crawling_velog import *- Bash Operator : bash shell script를 실행 (리눅스 명령어 or 프로그램 실행 용도)
- Python Operator : 파이썬 코드(.py) 실행 용도
- Trigger Rule : 작업을 시작할 때, upstream 작업의 실행 상태 조건 (상위 작업에 대한 종속성)
🔎 추가 함수 & DAG arguments 정의
dag의 ID, 스케줄 간격, 시작 시간, 과거 의존성, 재시도 등과 관련된 설정 지정한다
# 결과 출력용 함수 정의
def print_result(**kwargs):
r = kwargs["task_instance"].xcom_pull(key='result_msg')
print("message : ", r)
# dag의 이름, 의존성, 이메일, 실패 시 이메일, 재시도 횟수, 재시도 시간 간격 등을 지정
default_args = {
'owner': 'owner-name',
'depends_on_past': False,
'email': ['your-email@g.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=30),
}
# dag의 id, arguments, 설명, 실행 간격, 시작 일자, 태그 등을 지정
dag_args = dict(
dag_id="crawling-velog",
default_args=default_args,
description='tutorial DAG ml',
schedule_interval=timedelta(minutes=50),
start_date=datetime.datetime(2023, 11, 24),
tags=['example-sj'],
)- default argument와 dag arguments와 관련된 자세한 내용은 이전 글 을 참고해보자.
🔎 DAG 객체 정의
위에서 지정한 argument로 설정된 DAG 객체를 정의하고, 그 안에 실행될 task들과 그 실행 순서 그래프를 명시한다.
with DAG( **dag_args ) as dag:
start = BashOperator(
task_id='start',
bash_command='echo "start!"',
)
get_url_task = PythonOperator(
task_id='selenium_get_url',
python_callable=get_url_list,
)
get_info_task = PythonOperator(
task_id='bs_get_info',
python_callable=crawling,
op_kwargs={'url_list':"url_list"}
)
msg = PythonOperator(
task_id='msg',
python_callable=print_result
)
complete = BashOperator(
task_id='complete_bash',
bash_command='echo "complete!"',
)
# Task를 연결하여 dag 그래프 그리기
start >> get_url_task >> get_info_task >> msg >> complete
start,end: Bash Operator로 echo 명령어로 메세지를 출력get_url_task: Python Operator로 get_url_list 함수를 실행해서 selenium으로 트렌딩 블로그 url을 크롤링하는 taskget_info_task: Python Operator로 crawling 함수를 실행해서 bs4로get_url_task에서 받아온 글(url)의 정보를 크롤링하는 taskmsg: 최종 실행 결과에 대한 출력을 하는 task
- 각 task마다
task_id지정- Bash operator
bash_command로 실행할 명령어 지정- Python operator
python_callable로 실행할 함수(혹은 객체) 지정op_kwargs로 파이선 개체에 전달할 키워드 인자(kwargs) 지정
3️⃣ Task 파일 상세
이제 기존 크롤링 코드를 DAG에 맞게 수정하거나, Xcome을 활용하는 등 일부 수정하자
DAG를 위해서 수정한 부분만 아래에서 자세히 다뤄보도록 하자~!
🔎 전체 코드
crawling/crawling_velog.py
import pandas as pd
import time,os,requests
import warnings
import datetime
from selenium import webdriver
from bs4 import BeautifulSoup as bs
from selenium.webdriver.common.by import By
warnings.filterwarnings(action="ignore")
# selenium으로 velog 메인 페이지에서 트렌딩 글들 링크만 가져오기 (beautilfulSoup으로 하니까 못 찾아서)
def get_url_list(**kwargs) :
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
browser = webdriver.Chrome(options = chrome_options)
browser.get("https://velog.io/")
time.sleep(5)
url_list = browser.find_elements(By.CLASS_NAME, 'VLink_block__Uwj4P.PostCard_styleLink__DYahQ')
result = []
for url in url_list :
link = url.get_attribute('href')
print(f"######{link}######")
result.append(link)
result = list(set(result))
kwargs['task_instance'].xcom_push(key='url_list', value = result)
return "end get url list"
# beautifulSoup으로 각 블로그 글 접속
def open_page(url) :
req=requests.get(url).text
page=bs(req,"html.parser")
return page
# beautifulSoup으로 접속한 블로그 정보 가져오기
def get_title(page) :
title = page.find('div', {'class':'head-wrapper'})
title = title.find('h1').text
return title
def get_writer(page) :
writer = page.find('a',{'class' : 'user-logo'}).text
return writer
def get_thumnail(page) :
img_all = page.find_all('img')
img_src = img_all[0].get('src')
return img_src
def get_text(page) :
text_all = page.find_all(['p','h1','h2','h3','li'])
text=""
for t in text_all :
text += t.text
return text
def crawling(**kwargs) :
url_list = kwargs['task_instance'].xcom_pull(key = 'url_list')
title, writer, img, text, link = [], [], [], [], []
for l in url_list :
link.append(l)
page = open_page(l)
time.sleep(1)
title.append( get_title(page) )
writer.append( get_writer(page) )
img.append( get_thumnail(page) )
text.append( get_text(page) )
print(title)
data = pd.DataFrame({'title' : title, 'writer' : writer, 'img' : img, 'text' : text, 'link' : link})
date = datetime.datetime.now().strftime("%Y%m%d")
data.to_csv(f"/home/ubuntu/airflow/airflow/data/velog_{date}.csv", index=False)
kwargs['task_instance'].xcom_push(key = f'velog_csv', value= f"/home/ubuntu/airflow/airflow/data/velog_{date}.csv")
kwargs['task_instance'].xcom_push(key='result_msg', value= f"total number of blogs this week : {len(data)}")
🔎 get_url_task : Selenium 크롤링
def get_url_list(**kwargs) :
############ chrome 브라우저 설정 ################
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
browser = webdriver.Chrome(options = chrome_options)
######## 메인 페이지 접속하여 클래스 이름으로 url찾기 #############
browser.get("https://velog.io/")
time.sleep(5) # 연결에 시간이 걸릴 수 있으니 대기 시간 설정
url_list = browser.find_elements(By.CLASS_NAME, 'VLink_block__Uwj4P.PostCard_styleLink__DYahQ')
result = []
for url in url_list :
link = url.get_attribute('href')
print(f"blog url : {link}")
result.append(link)
result = list(set(result)) # 중복 제거
######## XCom에 url이 모여진 리스트를 저장 #######
kwargs['task_instance'].xcom_push(key='url_list', value = result)
return "end get url list"
- Chrome 브라우저 설정 : 리눅스 위에서는 처음 Selenium 실행시키는 거라 애를 굉장히 많이(
하루) 먹었다. ( 별도 정리 예정 ) - 기존 코드와 동일하지만, EC2에서는 브라우저 접속 속도가 더 느린지 time.sleep()으로 대기 시간을 걸어줘야 했다. 결과는 result 리스트에 저장!
- XCom에 result 리스트를 저장해두고 task를 종료한다.
( XCom이 뭔지?.. 나중에 정리 하기 전에 여기 참고 ! https://lsjsj92.tistory.com/632 )
🔎 get_info_task : bs4 크롤링
def crawling(**kwargs) :
##### XCom에서 url 리스트 받아오기 #####
url_list = kwargs['task_instance'].xcom_pull(key = 'url_list')
# 빈 리스트로 초기화하고 크롤링하면서 리스트에 담기
title, writer, img, text, link = [], [], [], [], []
for l in url_list :
link.append(l)
page = open_page(l)
time.sleep(1) # 페이지 연결 대기 시간
title.append( get_title(page) )
writer.append( get_writer(page) )
img.append( get_thumnail(page) )
text.append( get_text(page) )
print(title)
# csv로 저장하기 위해 리스트를 dataframe으로 변환
data = pd.DataFrame({'title' : title, 'writer' : writer, 'img' : img, 'text' : text, 'link' : link})
# 파일 이름 지정을 위해 현재 날짜 계산(예; 20231125)
date = datetime.datetime.now().strftime("%Y%m%d")
# data 폴더에 csv 파일로 저장
data.to_csv(f"/home/ubuntu/airflow/airflow/data/velog_{date}.csv", index=False)
# csv 파일을 저장한 경로를 XCom에 저장
kwargs['task_instance'].xcom_push(key = f'velog_csv', value= f"/home/ubuntu/airflow/airflow/data/velog_{date}.csv")
# msg 태스크 수행을 위해서 총 크롤링한 블로그 개수를 세서 XCom에 저장
kwargs['task_instance'].xcom_push(key='result_msg', value= f"total number of blogs this week : {len(data)}")- XCom으로 url_list 라는 key로 url 리스트 받아온다.
- 리스트에 크롤링 결과들을 담는다. 페이지 대기시간 마찬가지로 설정해두었다!
- 리스트를 Dataframe으로 변환하고 data 폴더에 현재 날짜가 포함된 제목으로 csv 저장한다.
- csv 파일을 저장한 경로를 XCom에 velog_csv 라는 key로 저장한다.
- 최종적으로 총 크롤링한 블로그 개수를 알려주는 메세지를 msg 태스크에 전달하기 위해서 XCom으로 push한다
4️⃣ DAG 실행하기
werbserver GUI를 켜두고 scheduler를 실행시켜서 DAG가 잘 실행되었는지 확인해보자.
$ airflow webserver --port 8080
$ airflow scheduler- DAG 등록 실패 : GUI home에 어디가 잘못되었는지 알려주므로 고치자.
- Task 실행 실패 : log를 보면서 어디가 잘못되었는지 확인할 수 있다.
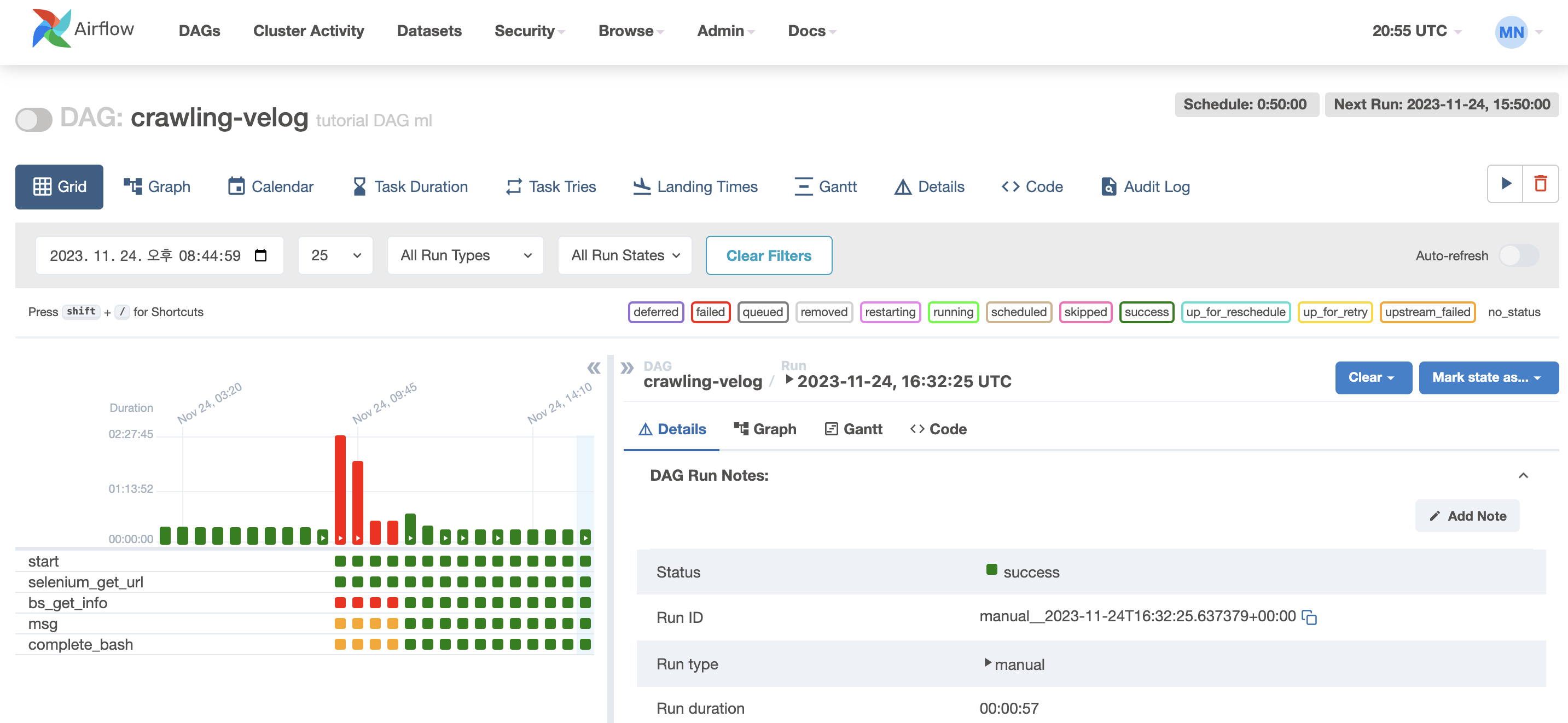
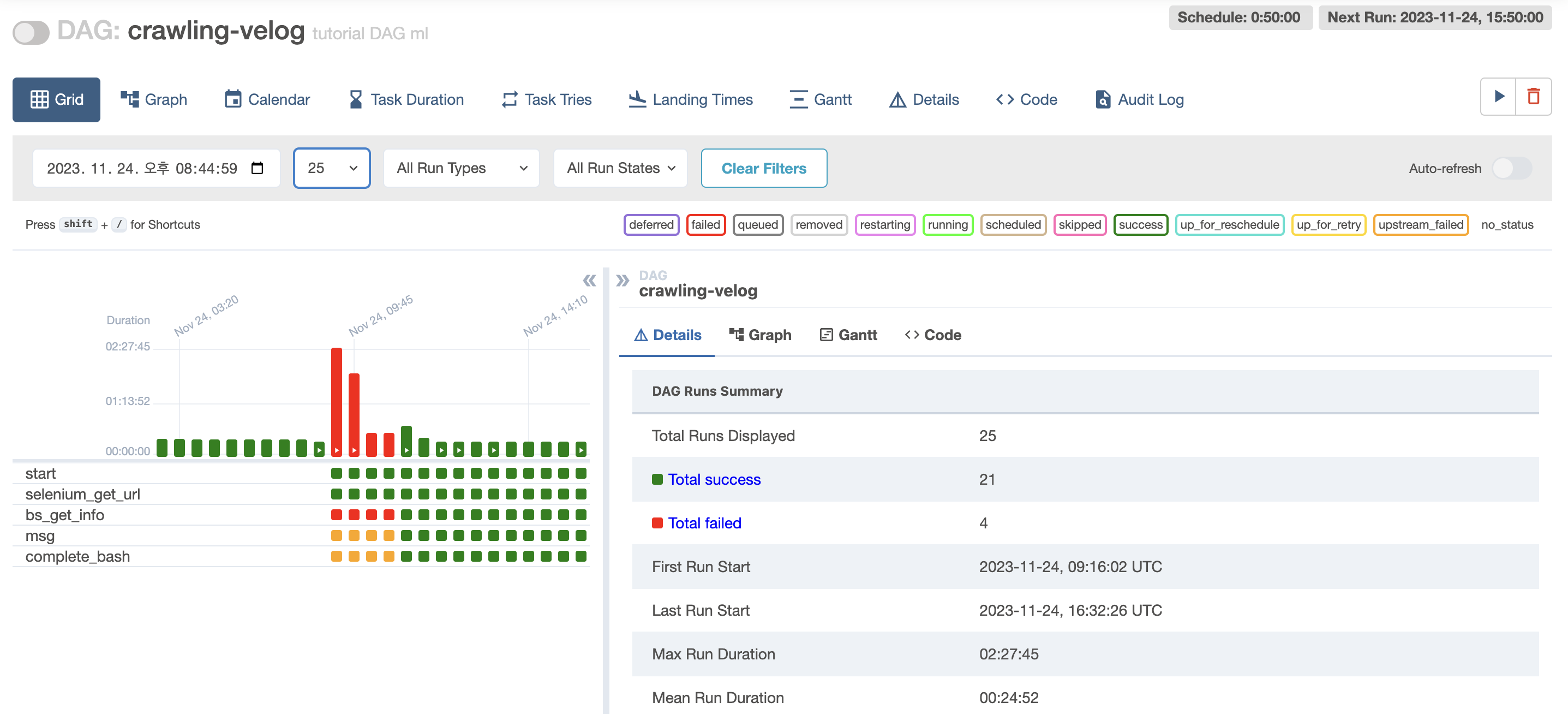
시행착오를 굉장히 많이 겪었다... 사실 EC2에 Chrome 설치해서 Selenium 실행시키는 것과, 대기 시간을 설정하지 않아서 결과가 나오지 않았던 쓸데없는 오류를 고치는 데 더 많은 시간이 걸렸지만... 그래도 성공했다...!! 🥲🥲
로컬로 파일 옮겨서 csv가 잘 저장되었는지까지 확인 완료!! 이론 부분은 다음주에 마저 추가로 공부해서 정리해야겠다..!
깃허브에 업로드까지 끝!-! 👉🏻 코드가 정리된 깃허브 바로가기
