

🥲 (2)에서 csv로 저장까지 했는데 S3에 저장하는 것까지 다시 해보자..
트랙원들 편하게 가도록 길 갈고 닦기..💫 결과
짜잔 일단 목표했던 S3에 올려진 것까지 확인했다..! 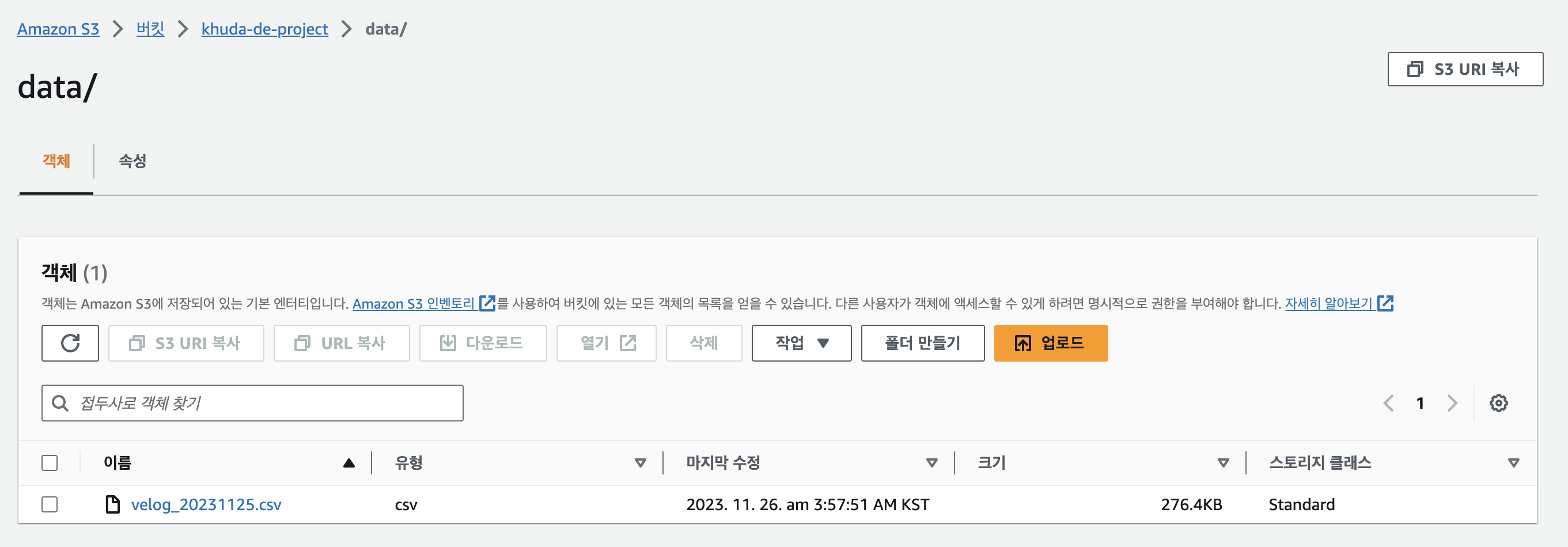
참고한 블로그 링크
- https://velog.io/@tfj0531/Airflow-와-AWS-S3-연결하기-S3-DAG-example
- https://velog.io/@jskim/Airflow-Pipeline-만들기-AWS-S3에-파일-업로드하기
5️⃣ S3 버킷 만들기
S3는 Simple Storage Service를 의미한다. 이 글은 프로젝트 글이므로 이론적 내용은 이후에 이론편에서 정리해보자...
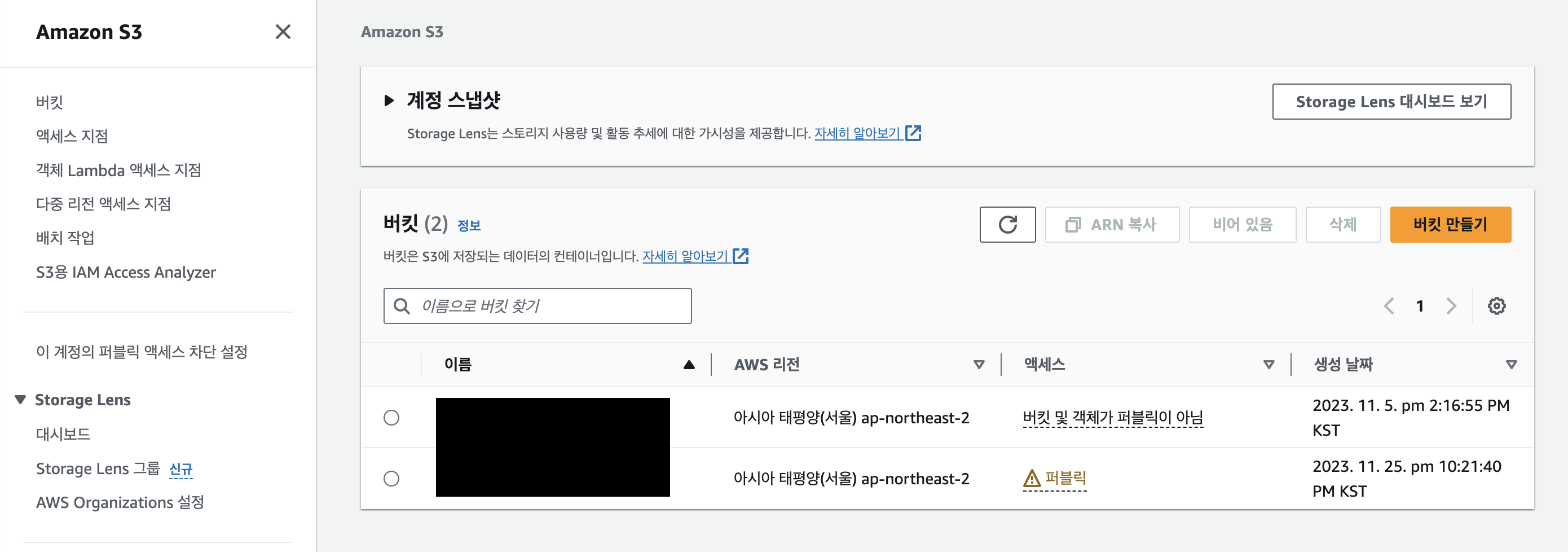
AWS에서 S3를 들어가서 [ 버킷 만들기 ] 에 들어간다.
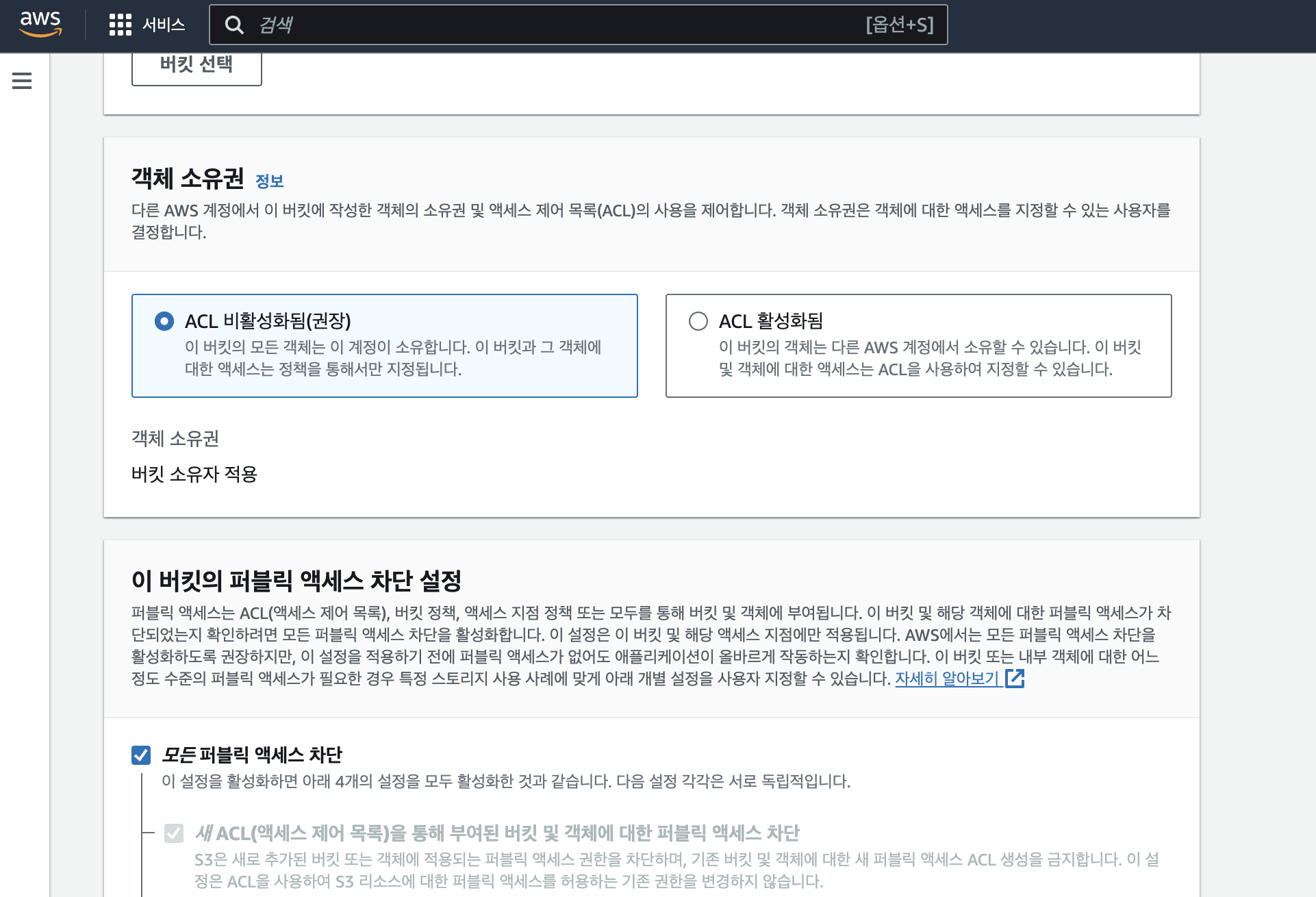
버킷 이름과 AWS 리전을 설정하고, 객체 소유권은 ' ACL 비활성화 '를 유지한다. 퍼블릭 액세스 차단 설정은 우선 '모든 퍼블릭 엑세스 차단'으로 생성하는데, 그러면 일단 자신만 접근할 수 있다. 이후에 정책 설정 등으로 변경할 예정이지만, 보안상 정책 설정하기 전에는 일단 두자. 나머지 설정도 그대로 두고 생성한다.
6️⃣ S3와 연결
Airflow 웹서버에서 상단의 탭에서 [ Admin ] -[ Connections ] 을 들어간다. 그리고 왼쪽에 있는 파란색 ✚ 버튼을 눌러서 새 연결을 설정해준다.
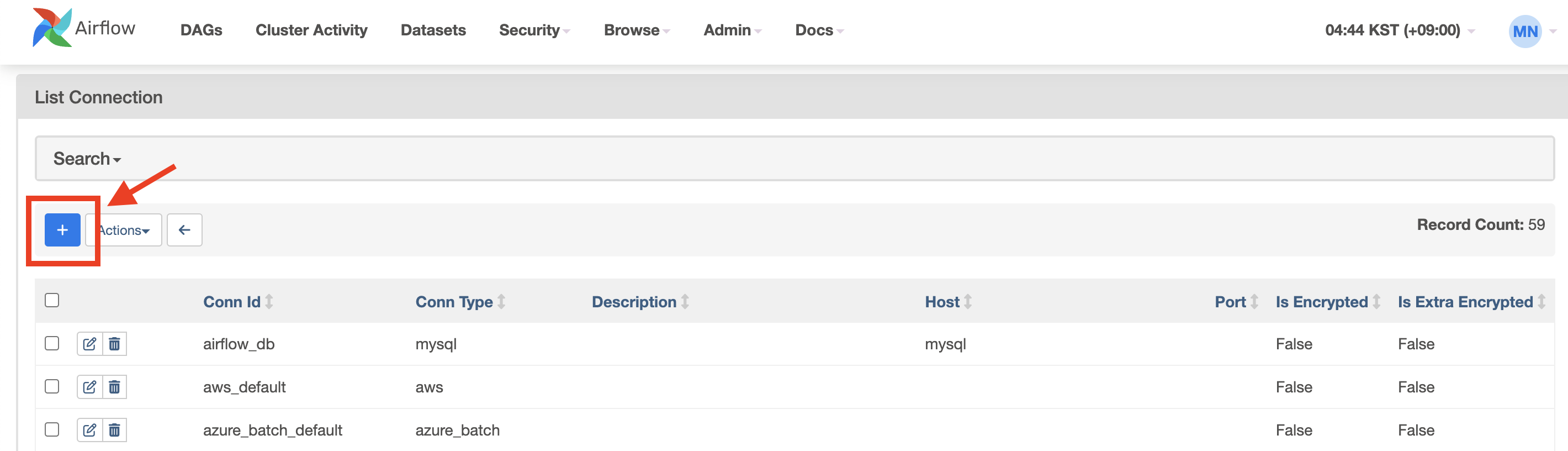
그럼 아래와 같은 창이 나온다. 다음과 같은 사항들을 채워야 한다.
- [ Neccessary ]
- Connection ID
- Connection Type
- AWS Access Key ID , AWS Secret Access Key
- [ Optional ]
- Description
- Extra
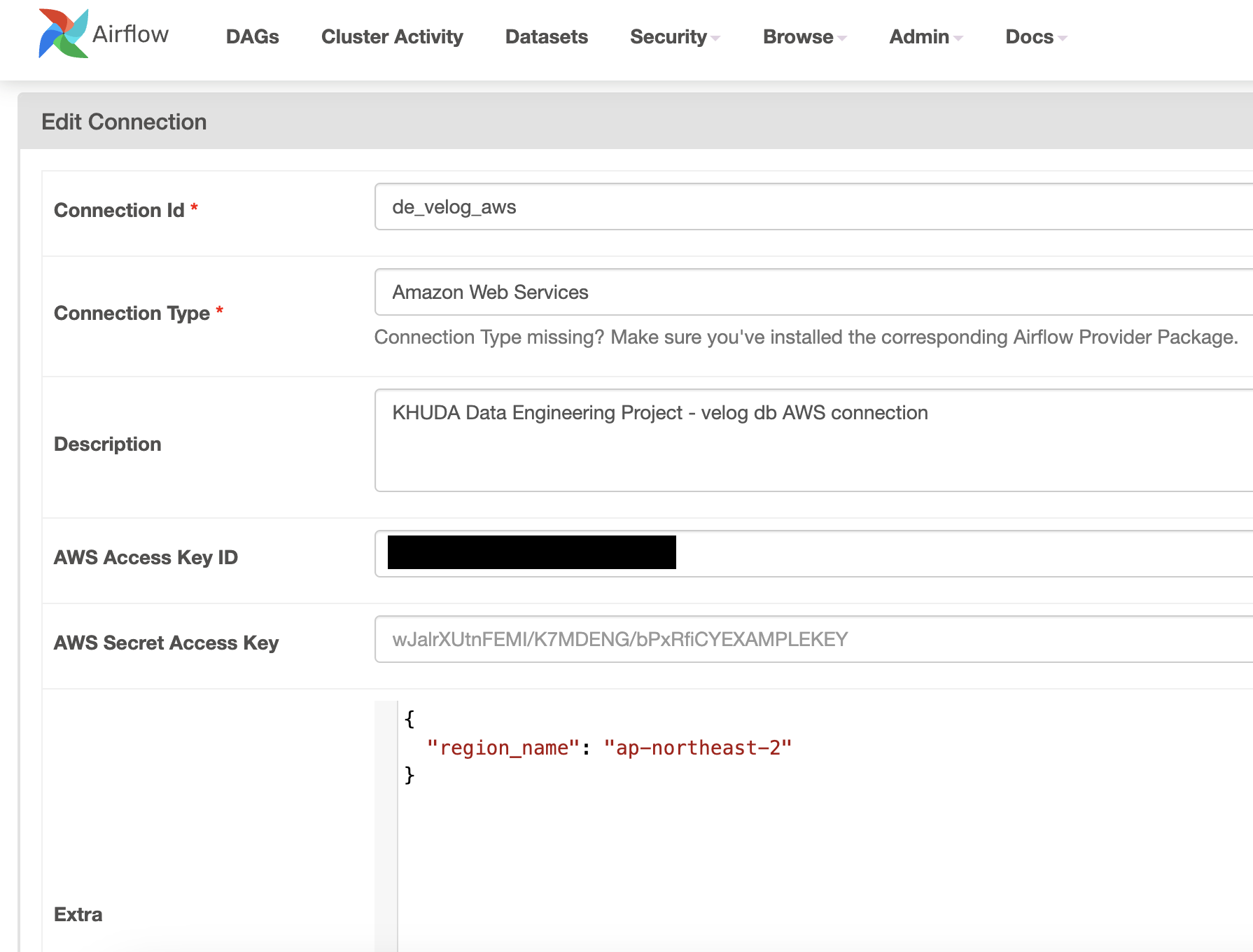
AWS Connection Type 활성화
다음 명령어를 shell에서 실행하고 웹서버를 켜야 Connection Type에서 Amazon Web Services를 이용할 수 있다. 👉🏻 공식 문서
pip install apache-airflow-providers-amazonAWS Access Key Id, AWS Secret Access Key 생성
IAM (Identifier and Access Management
AWS 의 IAM을 통해 리소스의 접근 권한을 설정할 수 있다. Access Key 를 발급하기 위해서는 우선 사용자가 있어야 한다 (없다면 '사용자 생성' 버튼으로 만든다)
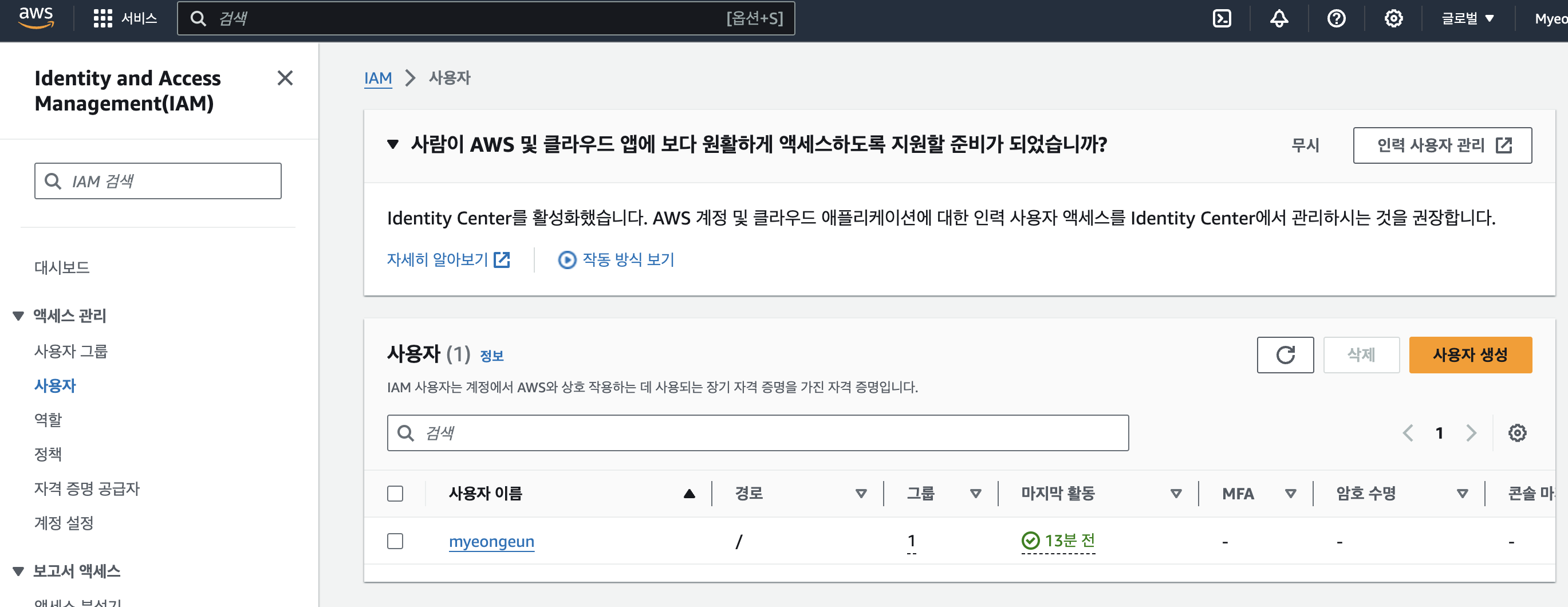
사용자 이름을 눌러서 들어가면 정보가 나온다. 그중에서 [보안 자격 증명] 탭을 찾아 클릭한다.
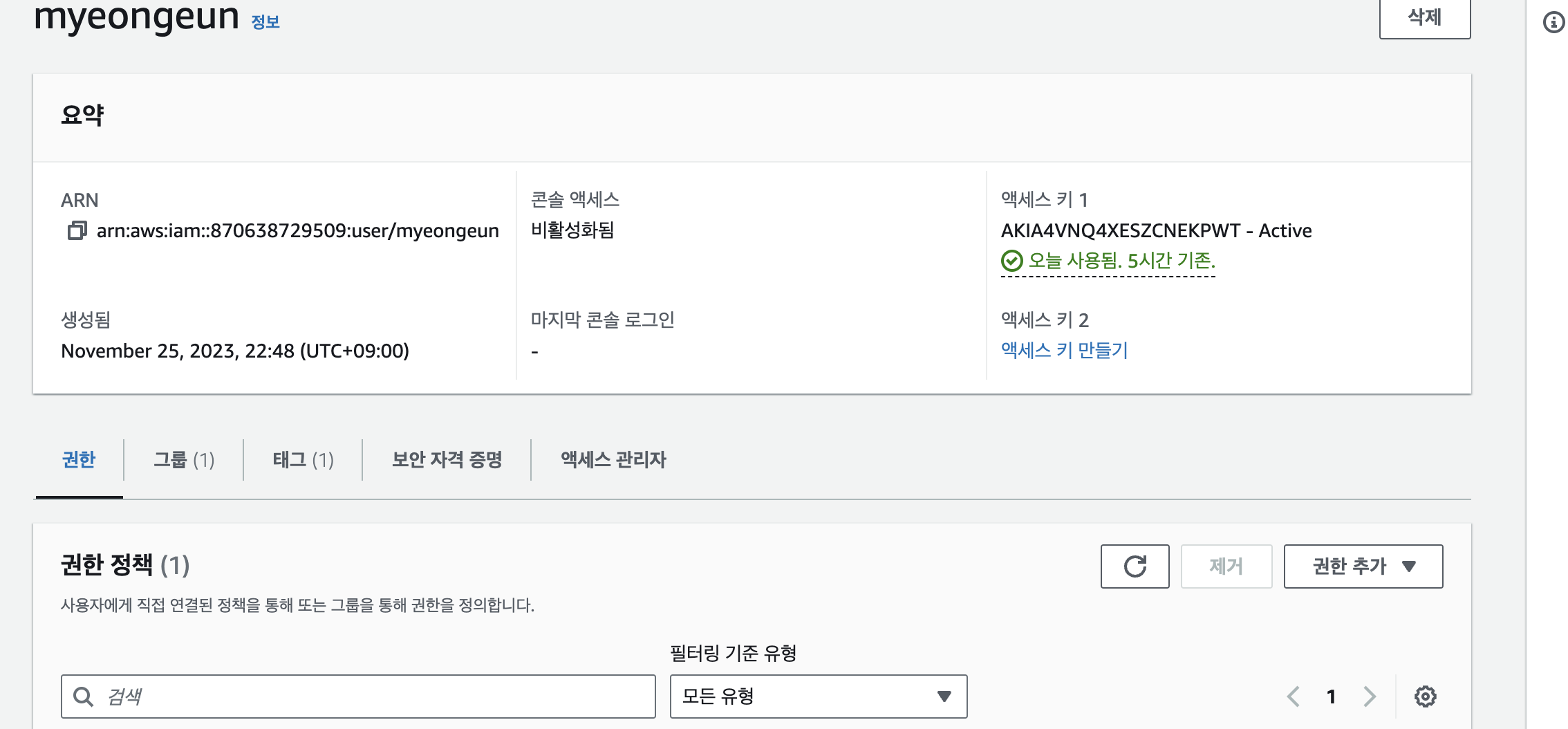
아래로 내리면 액세스 키가 보인다. 나는 이미 생성해서 아래처럼 뜨지만, 없다면 오른쪽 위에 [ 액세스 키 만들기 ]를 눌러준다.
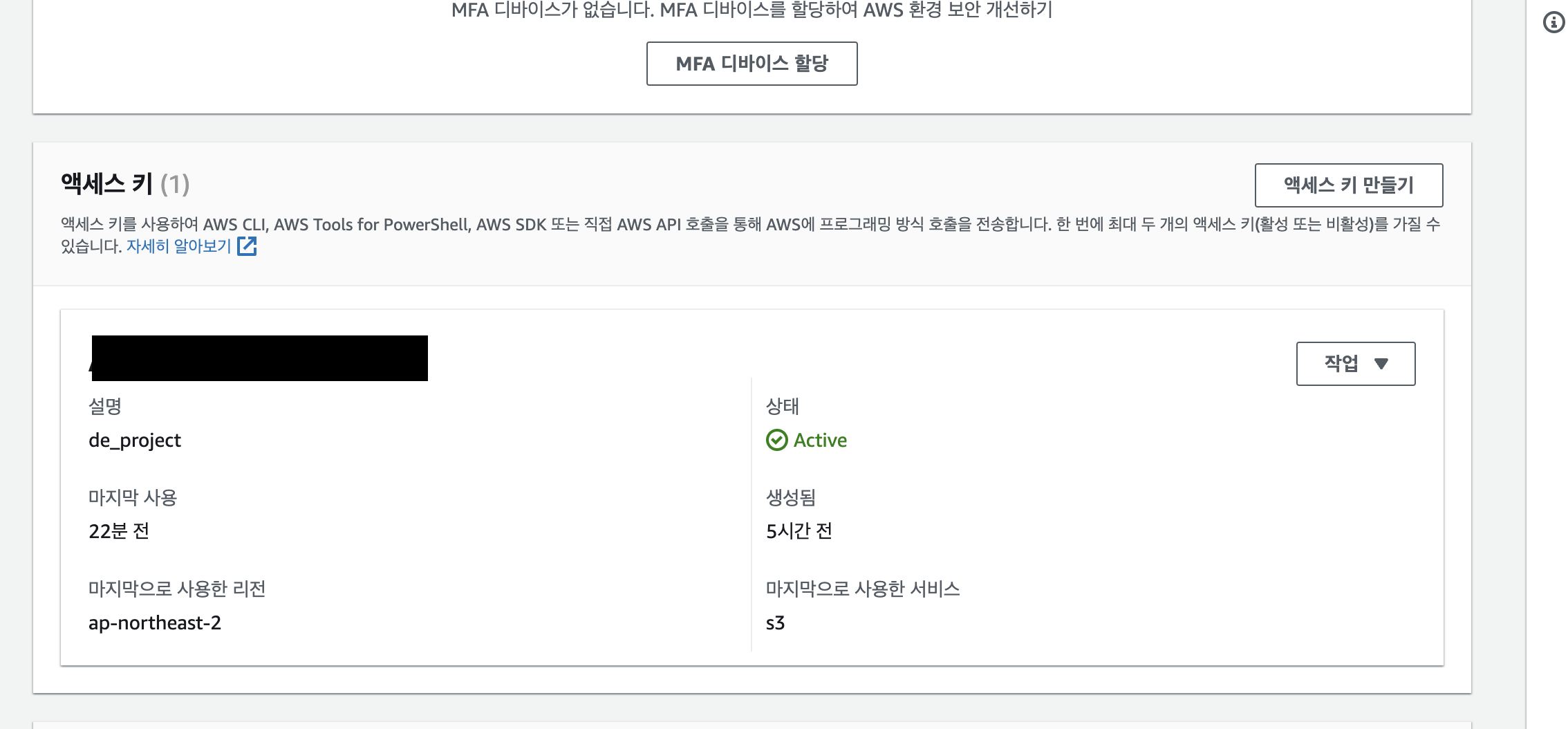
S3에 대해서 할 거라서, [ AWS 컴퓨팅 서비스에서 실행되는 애플리케이션 ]을 클릭하고 아래 뜨는 확인 버튼도 누르고 나서 넘어간다.
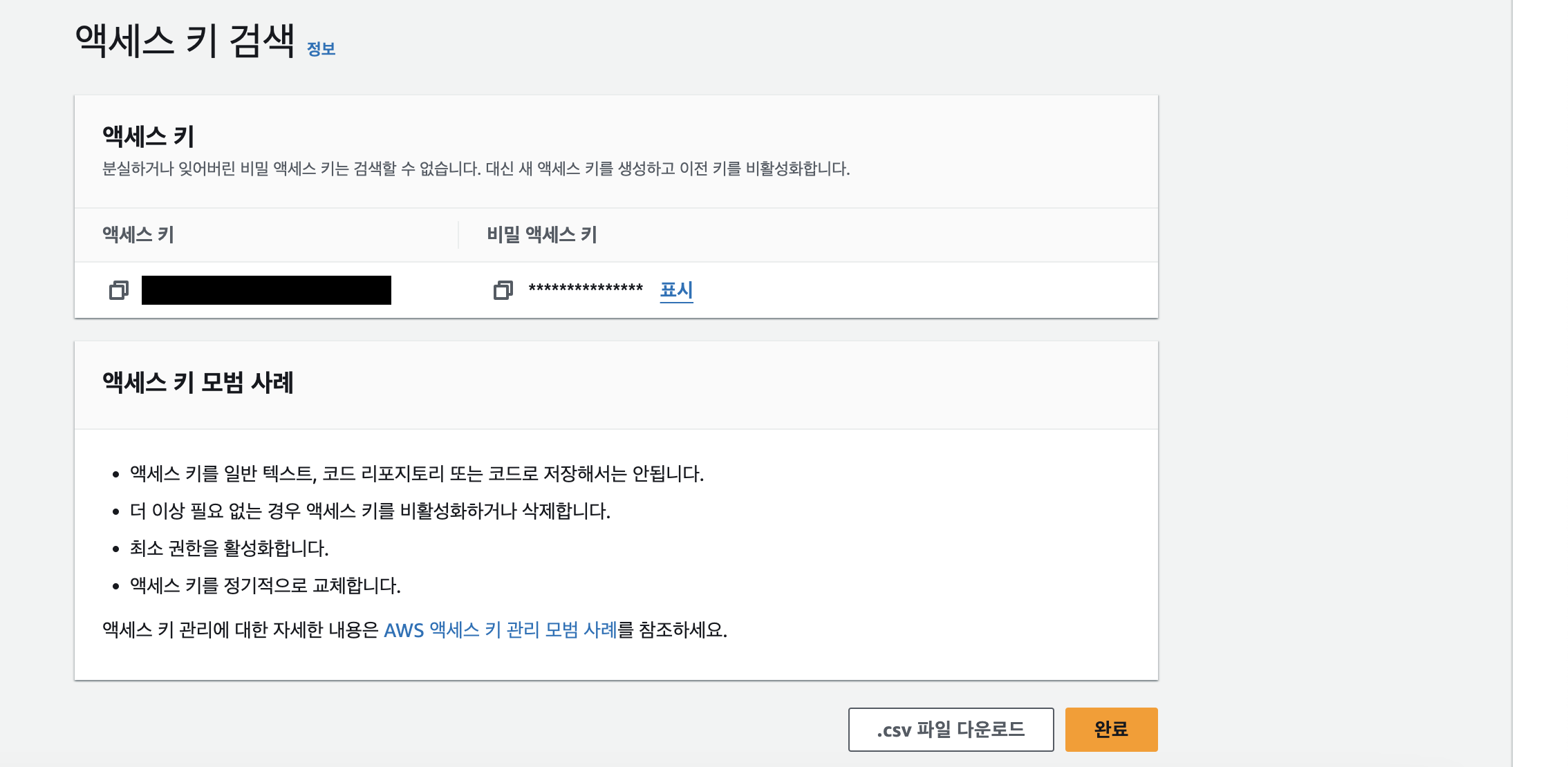
태그까지 입력하면 아래처럼 액세스 키가 만들어진 것을 확인할 수 있다. 비밀 액세스 키의 경우 지금이 아니면 비밀 액세스 키를 보거나 다운로드할 수 없고, 이후에 나중에 복구할 수 없으므로 잘 저장해두자.
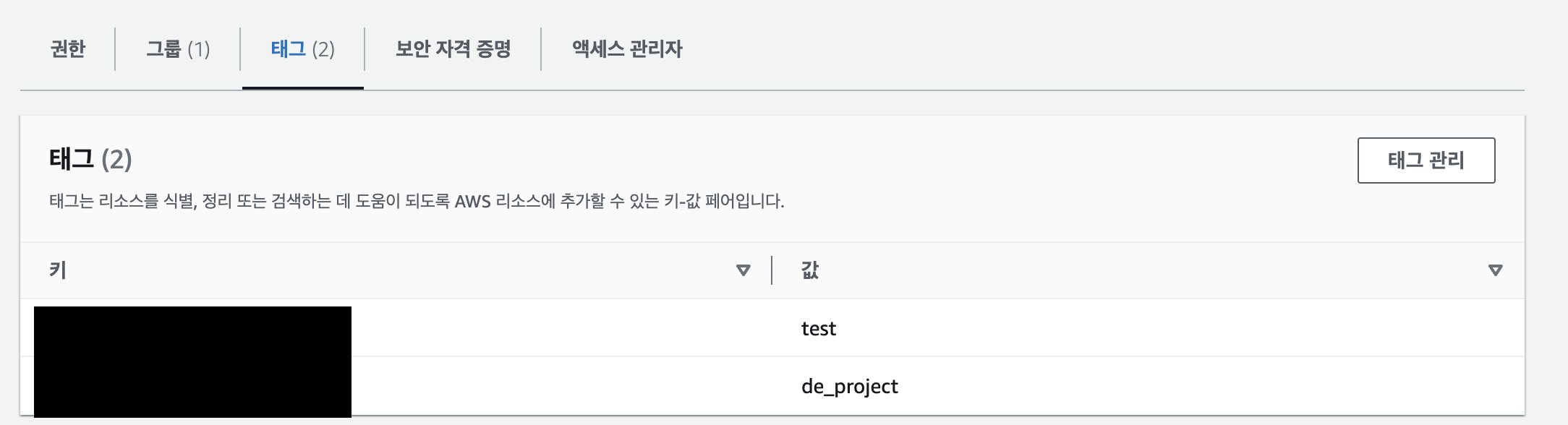
✚ 태그(Tag)라는 것은 리소스를 식별, 정리, 또는 검색하는 데 도움이 되도록 AWS 리소스에 추가할 수 있는 키-값 페어이다.
Extra 작성
Extra 부분에 region에 대한 default 값을 지정해준다.
{
"region_name": "ap-northeast-2"
}Test Connection
연결이 잘 되었는지 테스트 하기 위해서 테스트 버튼이 아래처럼 있는데, 아마 airflow.cfg 파일을 수정하지 않았다면, Test 버튼이 활성화되어있지 않을 수 있다.
airflow.cfg 파일에서 test_connection 부분을 찾아서 ❗️ Disabled → Enabled ❗️ 로 바꿔준다. 아니면 환경변수 AIRFLOW__CORE__TEST__CONNECTION 값을 설정해서 바꿀 수도 있다. ( 👉🏻 관련 내용 공식 문서 바로 가기 )
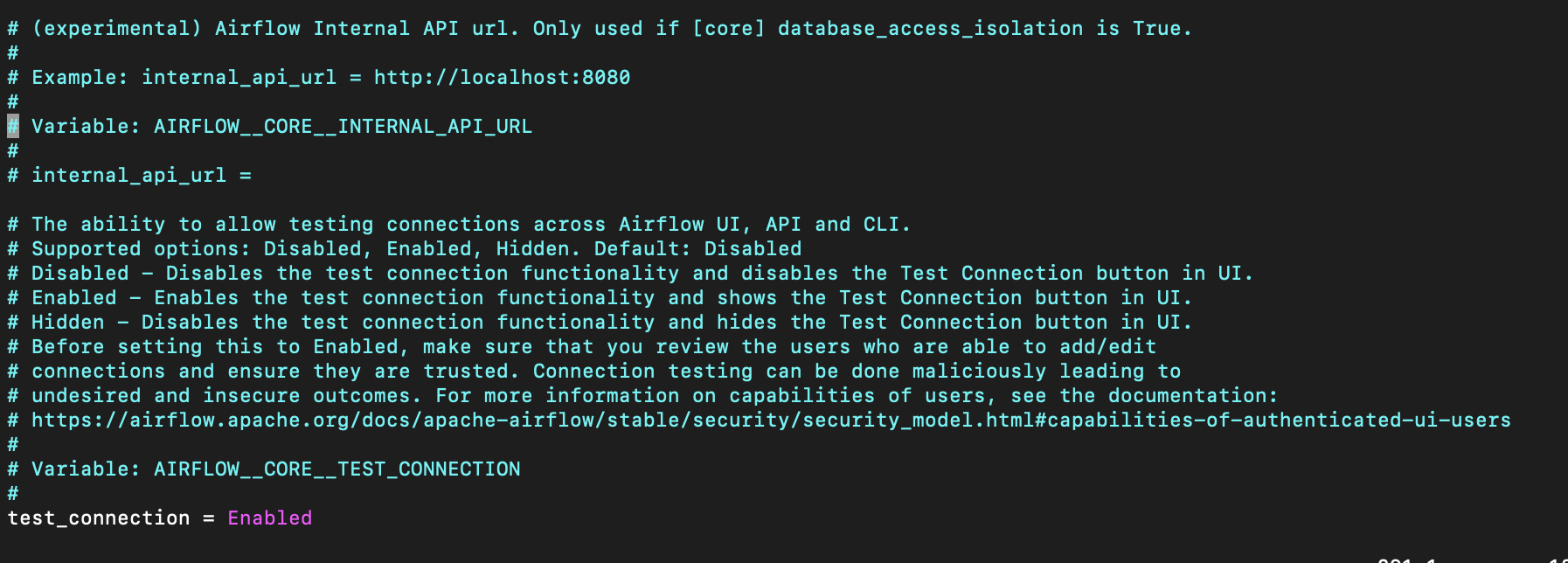
그리고 나서 웹서버를 다시 실행시키면, 테스트 버튼이 활성화되어있다. 그리고 버튼을 눌렀을 때 다음과 같이 초록색 창이 뜨면 잘 연결이 된 것이다!
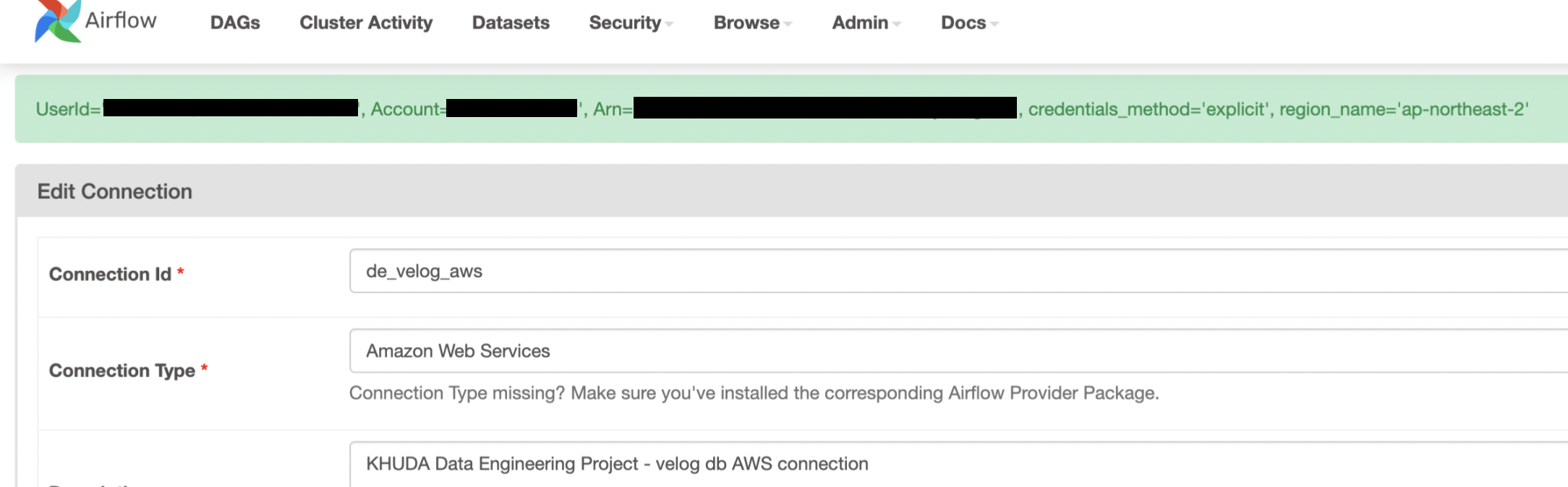
7️⃣ DAG 파일 추가(수정)
(2) 글에서 작성한 DAG가 작성된 crawling_velog_dag.py 파일에서 추가, 수정해서 S3에 만든 csv 파일이 업로드 되도록 만들어주자.
추가 모듈 임포트
S3Hook을 불러와준다.
from airflow.providers.amazon.aws.hooks.s3 import S3Hook python 함수 추가 작성 - upload_to_s3
S3에 업로드해주는 태스크를 위해 함수를 추가로 작성했다.
S3Hook객체를 생성하고 파라미터로는 6️⃣에서 생성한 Connection ID를 넣어준다.filename에는 S3에 올릴 파일이 저장된 경로를 넣어준다.key에는 S3에 저장할 경로를 지정해준다.bucket_name에는 올릴 S3의 버킷 이름을 넣어준다.
위에서 지정한 argument를 넣어줘서 load_file로 S3에 올리는 함수이다.
def upload_to_s3():
date = datetime.datetime.now().strftime("%Y%m%d"),
hook = S3Hook('de_velog_aws') # connection ID 입력
filename = f'/home/ubuntu/airflow/airflow/data/velog_{date}.csv'
key = f'data/velog_{date}.csv'
bucket_name = 'khuda-de-project'
hook.load_file(filename=filename, key=key, bucket_name=bucket_name)DAG 객체 수정
(2)에서와 나머지 부분은 동일하지만, upload라는 태스크를 하나 추가해주고 이를 DAG의 적절한 위치로 수정해주는 작업을 해준다.
- Python Operator로 위에서 정의한 upload_to_s3를 수행하는 태스크
get_info_task(블로그 상세 정보 크롤링) 태스크와msg(최종 결과 메세지 출력) 사이에upload태스크를 넣어준다.
with DAG( **dag_args ) as dag:
# 이전과 동일하게 start 태스크 정의
upload = PythonOperator(
task_id = 'upload',
python_callable = upload_to_s3
)
# 이전과 동일하게 get_url_task, get_info_task, msg, complete 태스크 정의
start >> get_url_task >> get_info_task >> upload >> msg >> complete전체 코드
crawling_velog_dag.py
from datetime import timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python_operator import PythonOperator
from airflow.utils.trigger_rule import TriggerRule
from airflow.providers.amazon.aws.hooks.s3 import S3Hook # 추가
import sys, os
sys.path.append(os.getcwd())
from crawling.crawling_velog import *
def print_result(**kwargs):
r = kwargs["task_instance"].xcom_pull(key='result_msg')
print("message : ", r)
def upload_to_s3(filename: str, key: str, bucket_name: str) -> None:
date = datetime.datetime.now().strftime("%Y%m%d")
hook = S3Hook('de_velog_aws') # connection ID 입력
filename = f'/home/ubuntu/airflow/airflow/data/velog_{date}.csv'
key = f'data/velog_{date}.csv'
bucket_name = 'khuda-de-project'
hook.load_file(filename=filename, key=key, bucket_name=bucket_name)
default_args = {
'owner': 'owner-name',
'depends_on_past': False,
'email': ['your-email@g.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=30),
}
dag_args = dict(
dag_id="crawling-velog",
default_args=default_args,
description='tutorial DAG ml',
schedule_interval=timedelta(minutes=50),
start_date=datetime.datetime(2023, 11, 24),
tags=['example-sj'],
)
with DAG( **dag_args ) as dag:
start = BashOperator(
task_id='start',
bash_command='echo "start!"',
)
upload = PythonOperator(
task_id = 'upload',
python_callable = upload_to_s3
)
get_url_task = PythonOperator(
task_id='selenium_get_url',
python_callable=get_url_list,
)
get_info_task = PythonOperator(
task_id='bs_get_info',
python_callable=crawling,
op_kwargs={'url_list':"url_list"}
)
msg = PythonOperator(
task_id='msg',
python_callable=print_result
)
complete = BashOperator(
task_id='complete_bash',
bash_command='echo "complete!"',
)
start >> get_url_task >> get_info_task >> upload >> msg >> complete
8️⃣ 트러블 슈팅 기록
- 위에서 언급한 Test Connection에서 Test 버튼이 활성화되지 않아서 한참 애먹었었다...
