References
- LLM을 활용한 실전 AI 애플리케이션 개발, 허정준 지음
https://product.kyobobook.co.kr/detail/S000213834592 - https://www.softwaretestinghelp.com/data-mining-vs-machine-learning-vs-ai/
- Efficient Estimation of Word Representations in Vector Space (Google, word2vec)
https://arxiv.org/pdf/1301.3781 - Attention is All you need (Google, Transformer Architecture)
http://arxiv.org/pdf/1706.03762 - Improving Lanugauge zUnderstanding by Generative Pre-Training(Open AI, 트랜스포머 모델, 생성적 사전학습)
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf - Training language models to follow instructions with human feedback
https://arxiv.org/pdf/2203.02155 - 실습용 코드
https://github.com/onlybooks/llm
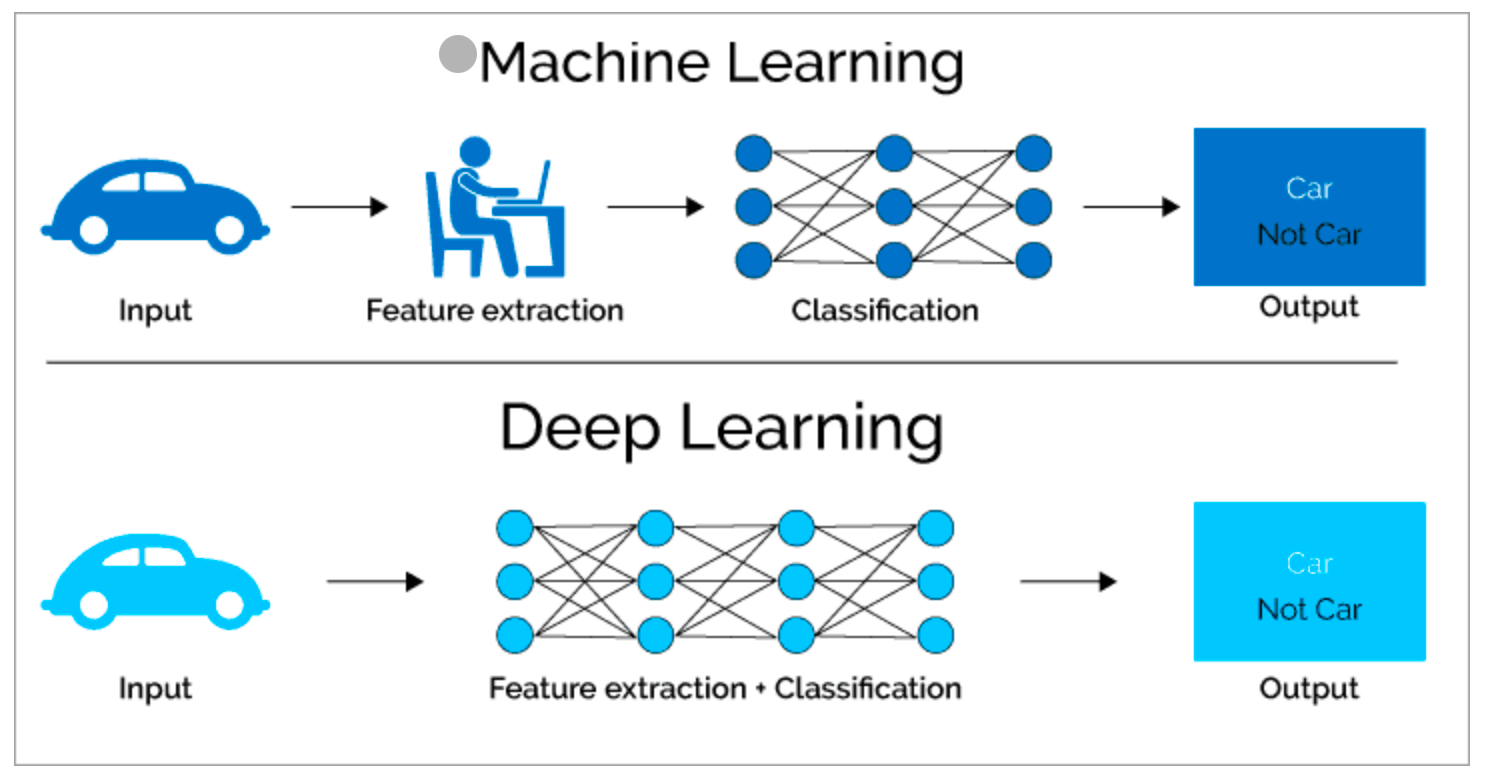
Machine Learning vs Deep Learning
데이터의 특징을 누가 뽑는지에 따라 달라짐.
- 머신러닝 : 피처를 연구자가 찾고 모델에 입력하여 결과 출력
- 딥러닝 : 모델이 스스로 데이터의 특징을 찾고 분류하는 모든 과정을 학습하여 출력
Embedding
임베딩은 데이터의 의미와 특징을 포착해 숫자로 표현한 것임.
임베딩은 딥러닝을 이해할 때 가장 중요한 개념 중 하나임.
2013년 구글에서 “백터 공간에서 단어 표현의 효율적인 추정“ 논문에서 word2vec 모델 통해 단어를 임베딩으로 변환하는 방법 소개.(레퍼런스 원문 확인)
RNN에서 트랜스포머 아키텍처로
트랜스포머 아키텍처는 맥락을 압축하지 않고 그대로 활용하므로, 성능을 높일 수 있지만, 맥락 데이터를 모두 저장해야해서 메모리 사용량이 증가함. 입력이 길어지면 예측에 걸리는 시간도 증가함.
많은 연산량이 필요하다는 단점이 있으나, 성능이 좋고 순차적으로 처리하는 RNN과 달리 병렬처리 통해 학습 속도 높일 수 있어 현재는 대부분의 LLM이 트랜스포머 아키텍처를 기반으로 하고 있음.
챗지피티 등장과 Alignment
- Alignment : LLM이 생성하는 답변을 사용자의 요청 의도에 맞추는 것. 사용자가 답변에서 얻고시은 가치를 반영해 LLM을 학습하여 사용자에게 가치있는 정보를 전달하도록 조정함.
- RLHF(Reinforcemnet Learning from Human Feedback) : 사람의 피드백을 활용한 강화학습으로, 이를 통해 사용자의 요청을 해결할 수 있는 텍스트를 생성하도록 하게 됨.
L Open AI의 논문 참고(상기 레퍼런스)
LLM 애플리케이션의 시대
- sLLM : small Large Language Model
- RAG : Retrieval Augmented Generation (검색 증강 생성)
sLLM
LLM 애플리케이션 개발 시, 크게 두 가지 방법이 있음.
1) 상업용 API를 사용하는 방법(GPT-4, 제미나이) : 모델이 크고 범용 텍스트 생성 능력 뛰어남.
2) 오픈소스 LLM 활용해 직접 LLM API 생성해 사용하는 방법 : 원하는 도메인 데이터, 작업 위한 데이터로 자유롭게 추가 학습 할 수 있는 장점. = 추가학습 하는 경우 모델 크기 작으면서도 특정 도메인 데이터나 작업ㄱ에서 높은 성능 보이는 모델을 만들 수 있음 = sLLM
RAG
LLM은 잘못된 정보, 실제로 존재하지 않는 정보를 만들어내는 현상인 할루시네이션이 발생함.
지시 데이터셋으로 LLM을 지도 미세 조정하는 과정에서 기존에 알지 못하는 정보가 포함된 경우 할루시네이션 현상을 유발 할 수 있다 함. > 이런 문제를 줄이기 위해 검색 증강 생성인 RAG 기술을 사용한다. 이는 프롬프트에서 LLM이 답변할 때 필요한 정보를 미리 추가함으로써 잘못된 정보를 생성하는 문제를 줄인다.
트랜스포머 아키텍처
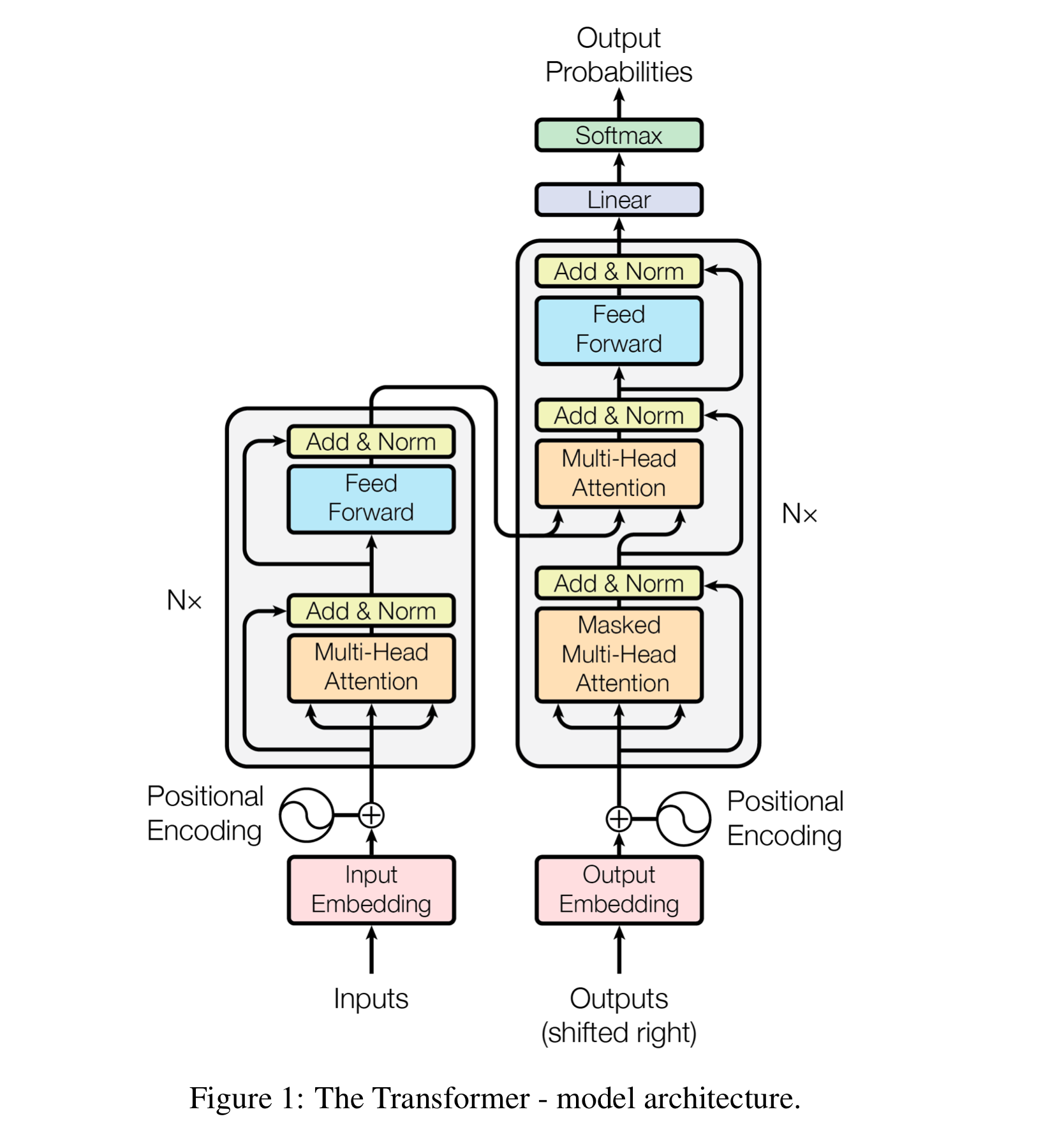
- 트랜스포머 아키텍처는 크게 인코더(layer normalization, multi-head attention, feed forward 층 거치며 문장 이해하고 그 결과를 디코더로 전달)와 디코더로 나뉜다. 왼쪽 상자는 언어를 이해하는 역할을 하는 인코더, 오른쪽 상자는 언어를 생성하는 역할을 하는 디코더임.
- 공통적으로 입력을 임베딩 층을 통해 숫자 집합인 임베딩으로 변환하고, 위치 인코딩 층에서 문장 위치 정보를 더함.
텍스트를 임베딩으로 변환하기
- 순서 1) “토큰화“ : 텍스트를 적절한 단위로 잘라 숫자형 아이디를 부여
- 순서 2) 토큰 아이디를 토큰 임베딩 층을 통해 여러 숫자의 집합인 토큰 임베딩으로 변환
- 순서3) 위치 인코딩 층을 통해 토큰의 위치 정보를 담고 있는 위치 임베딩을 추가해 최종적으로 모델에 입력할 임베딩을 만듬.
책 64페이지 발췌

토큰화 (예제2.1. 토큰화 코드)
# 띄어쓰기 단위로 분리
input_text = "나는 최근 파리 여행을 다녀왔다"
input_text_list = input_text.split()
print("input_text_list: ", input_text_list)
# 토큰 -> 아이디 딕셔너리와 아이디 -> 토큰 딕셔너리 만들기
str2idx = {word:idx for idx, word in enumerate(input_text_list)}
idx2str = {idx:word for idx, word in enumerate(input_text_list)}
print("str2idx: ", str2idx)
print("idx2str: ", idx2str)
# 토큰을 토큰 아이디로 변환
input_ids = [str2idx[word] for word in input_text_list]
print("input_ids: ", input_ids)