Tokenization (토큰화)
1_1) Token 정의 : 텍스트를 구성하는 개별 단위
1_2)Tokenization 정의 : 주어진 텍스트를 개별 토큰으로 분리하는 과정.
: 공백, 구두점, 특수 문자를 기준으로 나눌수도 있지만, 문맥에 따라 다를 수도 있음. 한국어는 형태소 단위로 토큰화 할때도 있었음.
2) 토큰 종류 : 단어 토큰, 문장 토큰, 문단 토큰, 알파벳/형태소 토큰, 문장 토큰
3) 토큰화의 중요성
대부분 NLP 작업에서 텍스트 자체를 다룬다기 보단, 토큰화하여 각 토큰 기반으로 처리이며, 필수적.
4) 토큰화 종류에 따른 비교
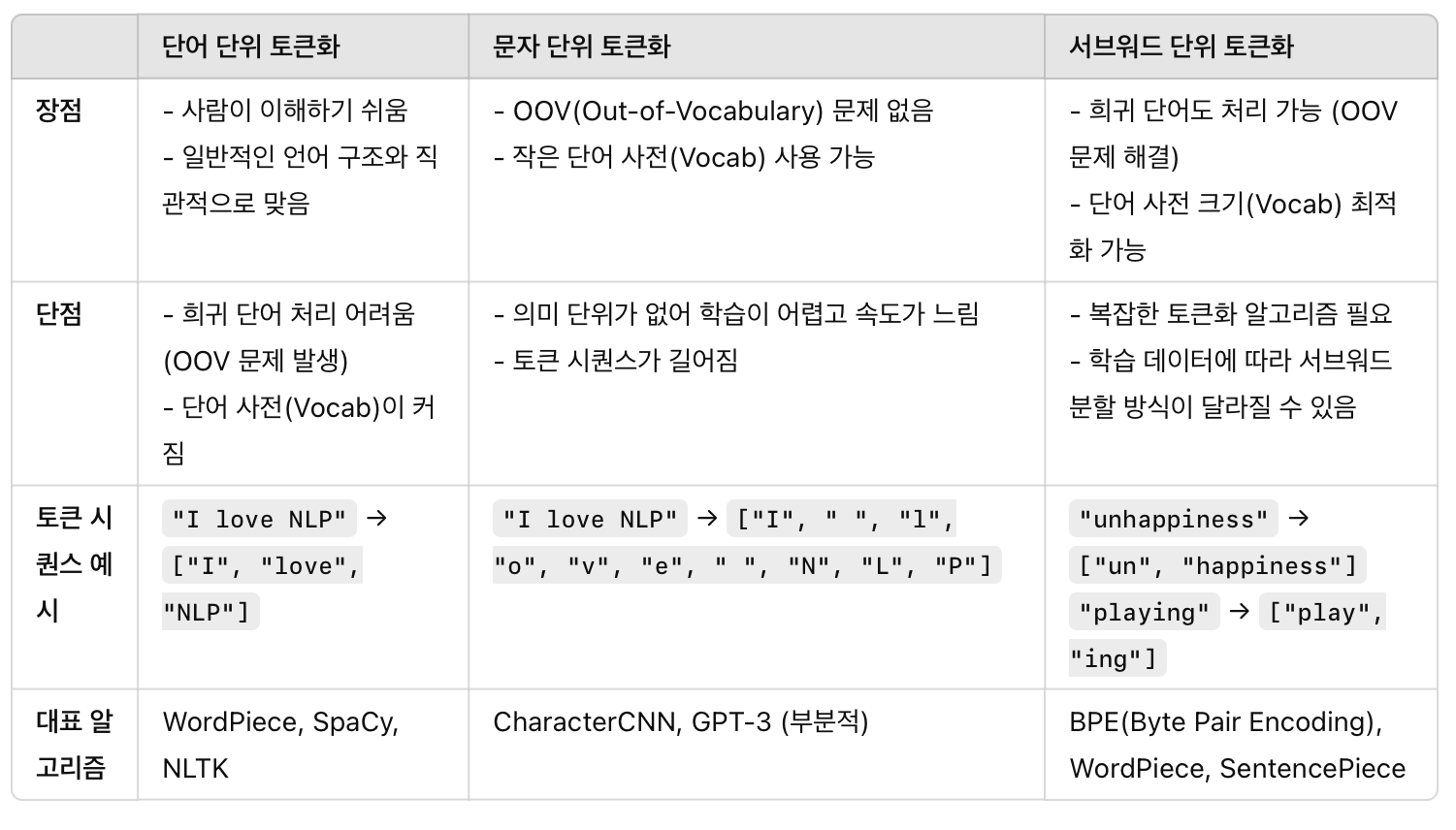
- 토큰 시퀀스(Token Sequence): 텍스트를 토큰화한 후 생성된 연속된 토큰들의 리스트
A) 단어 단위 토큰화 → 짧은 토큰 시퀀스 (ex. ["I", "love", "NLP"])
B) 문자 단위 토큰화 → 긴 토큰 시퀀스 (ex. ["I", " ", "l", "o", "v", "e", " ", "N", "L", "P"])
C) 서브워드 단위 토큰화 → 중간 길이의 토큰 시퀀스 (ex. ["play", "ing"])
- 서브워드 토큰화는 단어 단위와 문자 단위의 중간 형태로, 최근 LLM에서 가장 널리 사용됨.
In-context learning (인컨텍스트 러닝)
1) 기존 fine tunning의 한계
Fine-Tuning(파인 튜닝)은 사전 학습된 대형 언어 모델(LLM)에 추가적인 데이터셋을 사용하여 특정 작업에 맞게 추가 학습하는 과정이며, 아래 단점이 있음.
✅ 높은 비용 & 시간 소모
모델을 다시 학습해야 해서 많은 연산 리소스(GPU, TPU)가 필요함.
특히 거대한 LLM을 파인 튜닝하면 비용이 많이 듦.
✅ 특정 도메인에만 최적화됨
파인 튜닝된 모델은 특정 작업(task)에만 특화됨.
즉, 새로운 작업을 수행하려면 추가로 다시 학습해야 함.
✅ 데이터 준비가 어려움
많은 경우 데이터 수집과 가공이 어렵거나, 도메인마다 데이터가 부족할 수 있음.

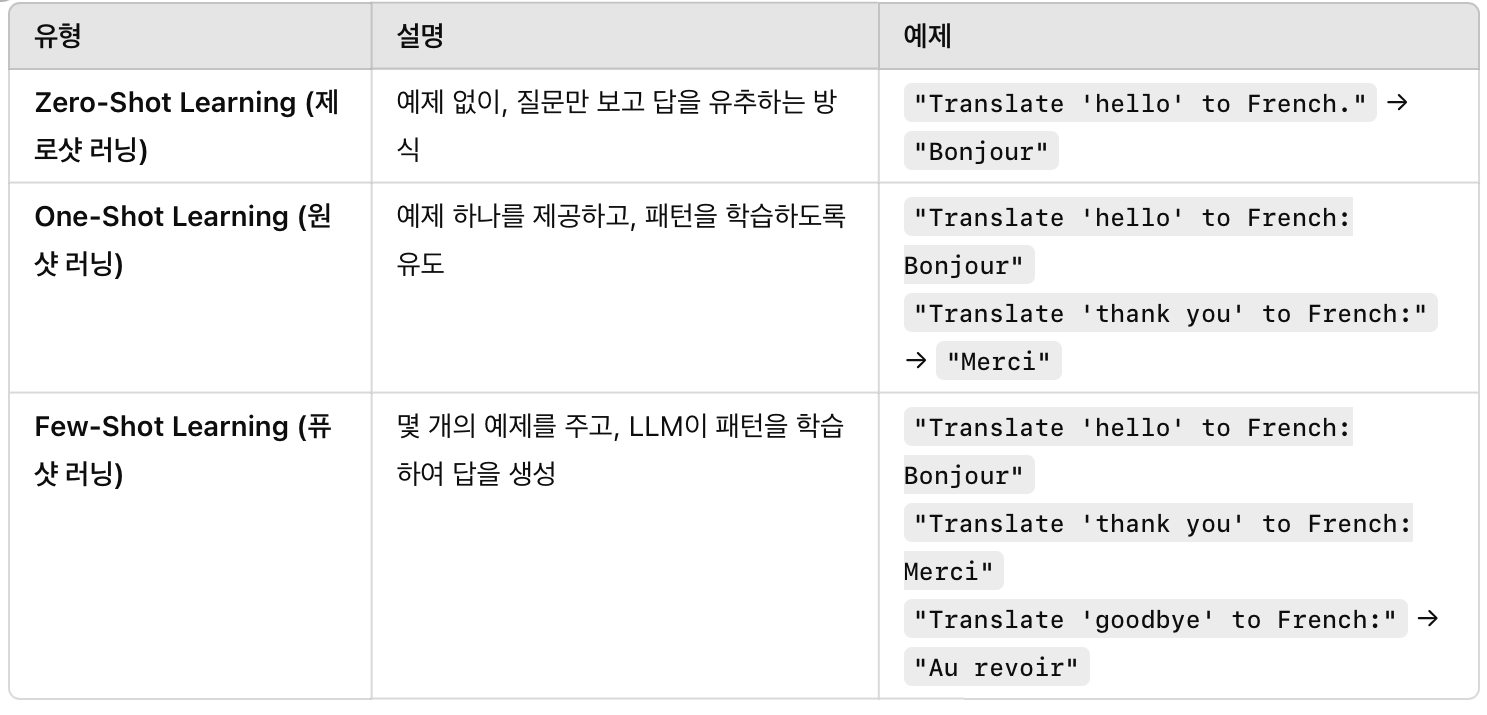
2) In-context learning 등장과 종류 : Zero-shot, One-shot, Few-shot
Fine-Tuning은 모델을 업데이트해서 새로운 작업을 학습하는 방식이라면,
In-Context Learning은 LLM이 기존 지식 활용하여, 주어진 예제만 보고 "즉석에서" 학습하는 방식.
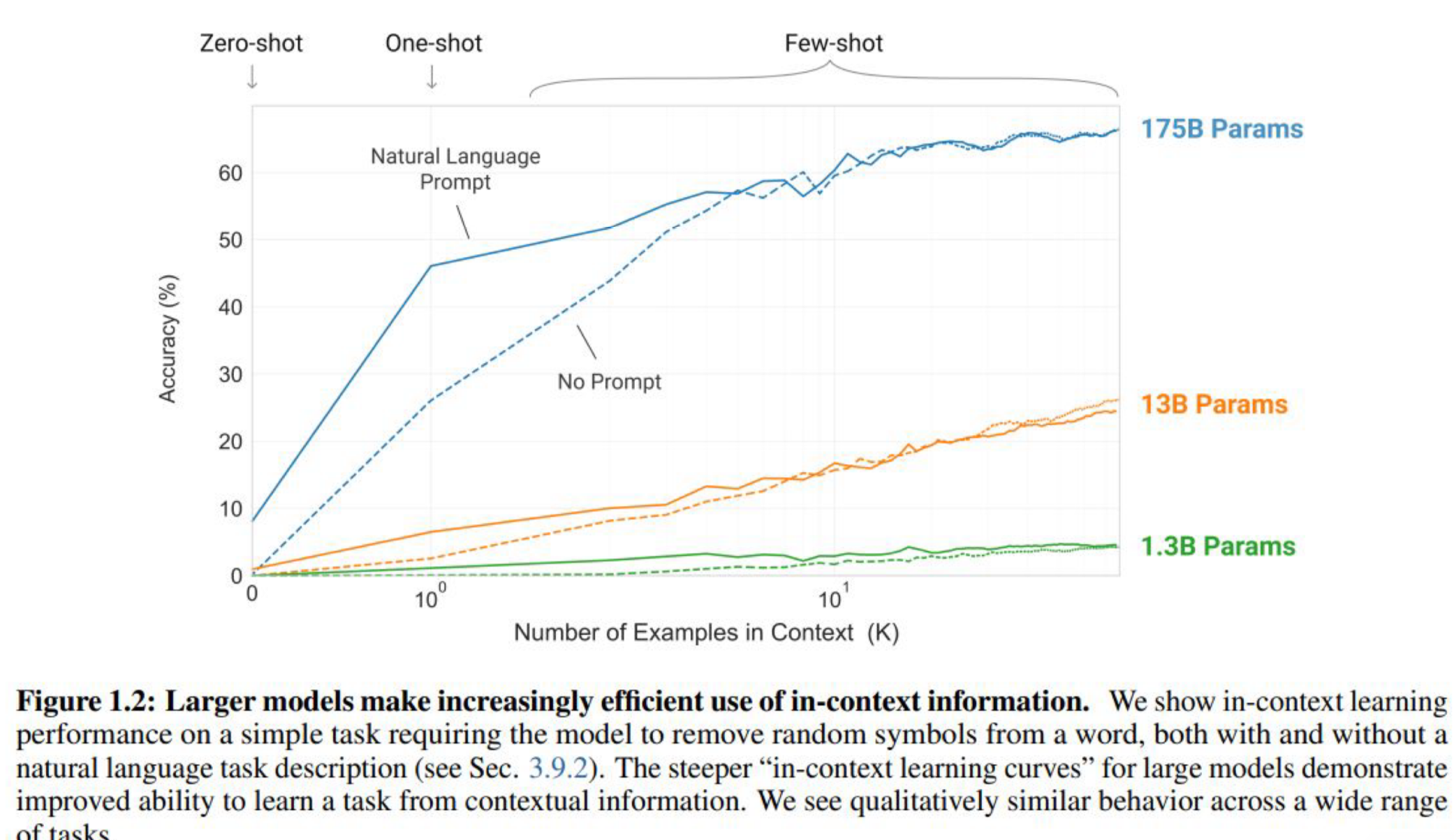
 샷별 성능 비교 : 1개 예제만 줘도 성능이 많이 향상됨.
샷별 성능 비교 : 1개 예제만 줘도 성능이 많이 향상됨.
3) In-context learning 과 Prompt Engineering
앞으로는 추가적인 Fine-tunning 보다도 In-context learning 만으로도 원하는 결과를 얻을 수 있게되면서, 어떻게 프롬프트를 잘 작성하는것이 좋을지 프롬프트 엔지니어링 기법이 연구되고 있음. 물론 특정 분야에서는 여전히 fine-tunning 이 필요하겠지만 프롬프트 작성 기법도 활발히 발전하고 있음.
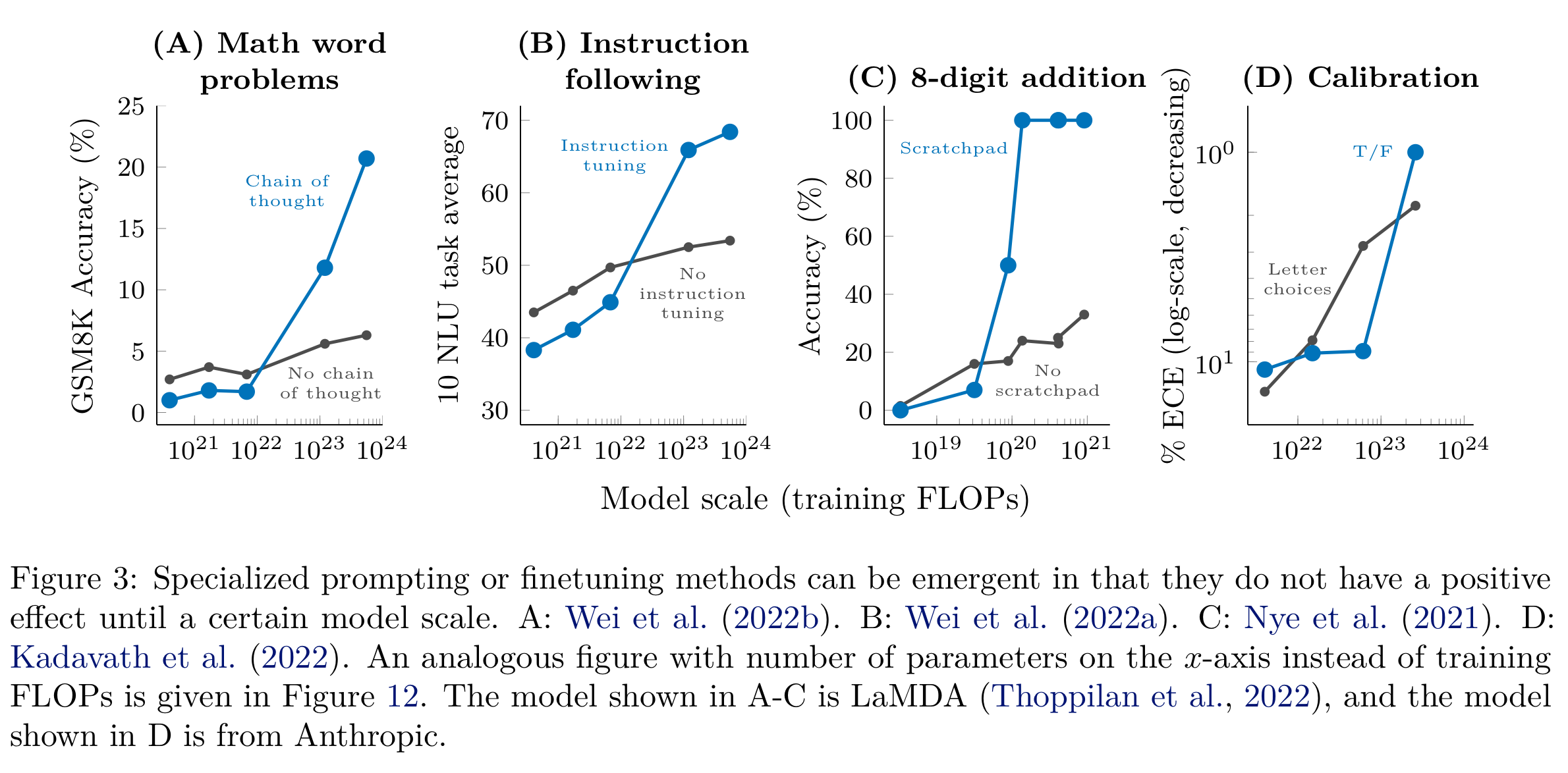
Emgergent ability
1) 정의 : 모델의 emergent abilities는 작은 규모의 모델에는 존재하지 않지만 큰 규모의 모델에는 존재하는 능력(계산량,모델 파라미터의 수, 그리고 학습 데이터셋의 크기가 많이 커지는 순간)
2)모델 별 emergent ability 임계치(모델 스케일)
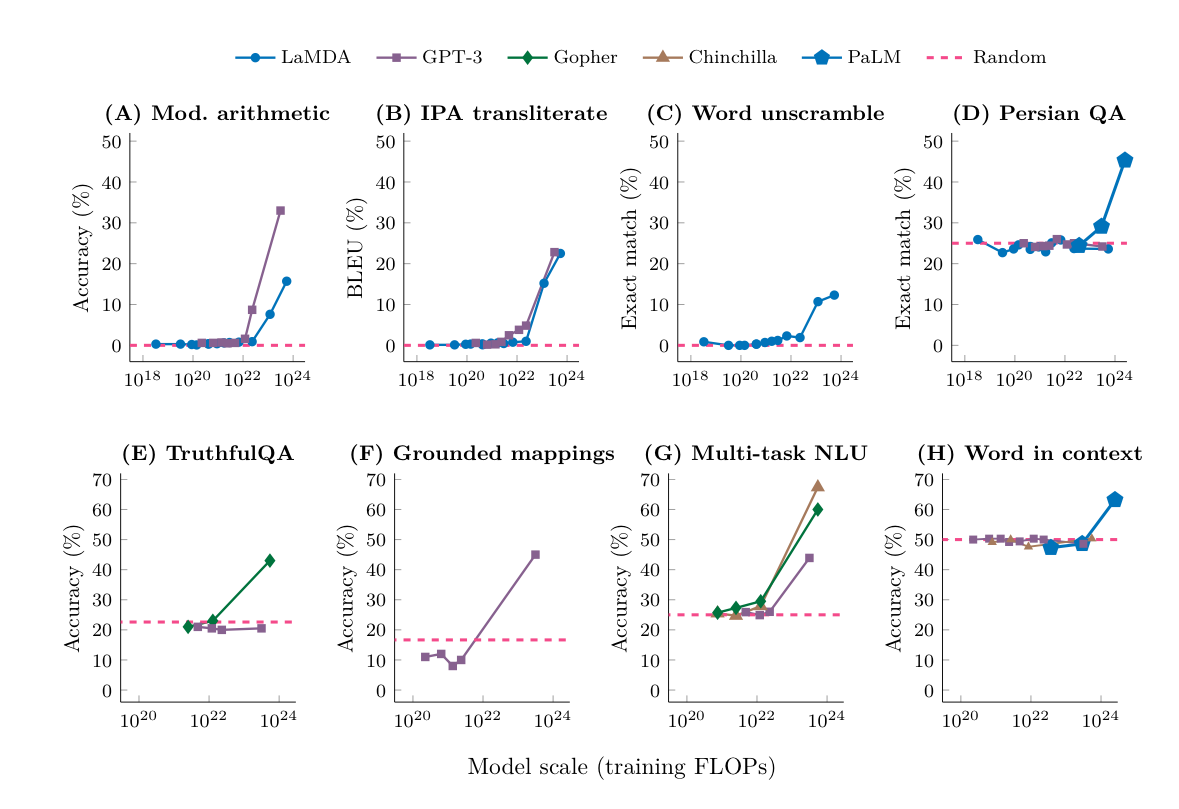
3)특정 프롬프팅 기법 활용 시에도 모델 스케일이 커지면 갑자기 특정 능력이 발현됨
Temperature (온도)
1) 다음 토큰 예측 방법 : Softmax Regression

언어 모델링(Language Modelling)에서 다음 토큰의 예측은 단어 집합(Vocabulary)에 존재하는 단어들에 대한 Softmax Regression값임.
✔ Softmax Regression을 사용해 다음 단어의 확률을 계산하고, 가장 높은 확률의 단어를 선택
✔ Temperature 값이 낮으면 확실한 단어 선택, 높으면 랜덤성이 증가
✔ T가 낮으면 예측이 보수적이고 정확한 답을 요구하는 작업에 적합 (예: 번역, 코드 자동 완성)
✔ T가 높으면 창의적인 결과를 생성할 수 있음 (예: 스토리 생성, 시 창작 등)
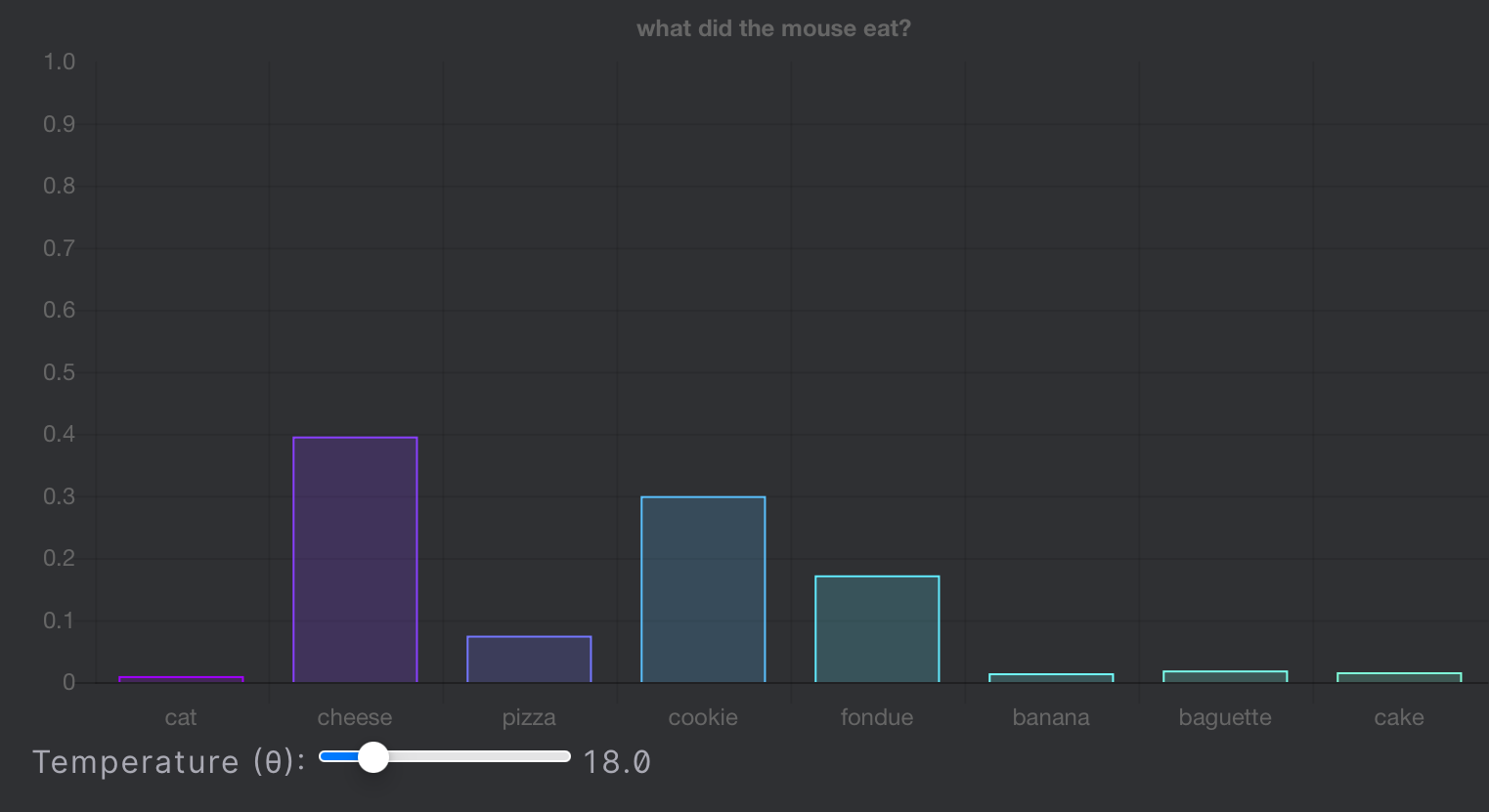
2) Temperature 값에 따른 다음 토큰 후보군
Temperature(온도) 조절은 Softmax의 출력을 조정하여
모델의 출력 확률 분포를 더 집중되게(낮은 온도) 또는 더 확산되게(높은 온도) 만드는 기법.
- 온도(Temperature)는 Softmax Regression의 각 다음 토큰이 샘플링시에 뽑힐 확률을 뾰족하게 만들어 주거나 평평하게 만들어줌.
temperature 값이 낮을 때 :
온도(Temperature) 값이 작을 경우 → 가장 확률값이 높은 토큰의 예측 확률이 증폭됨 → 가장 그럴듯한 토큰이 뽑힐 확률이 높아짐.

temperature 값이 중간일 때 :
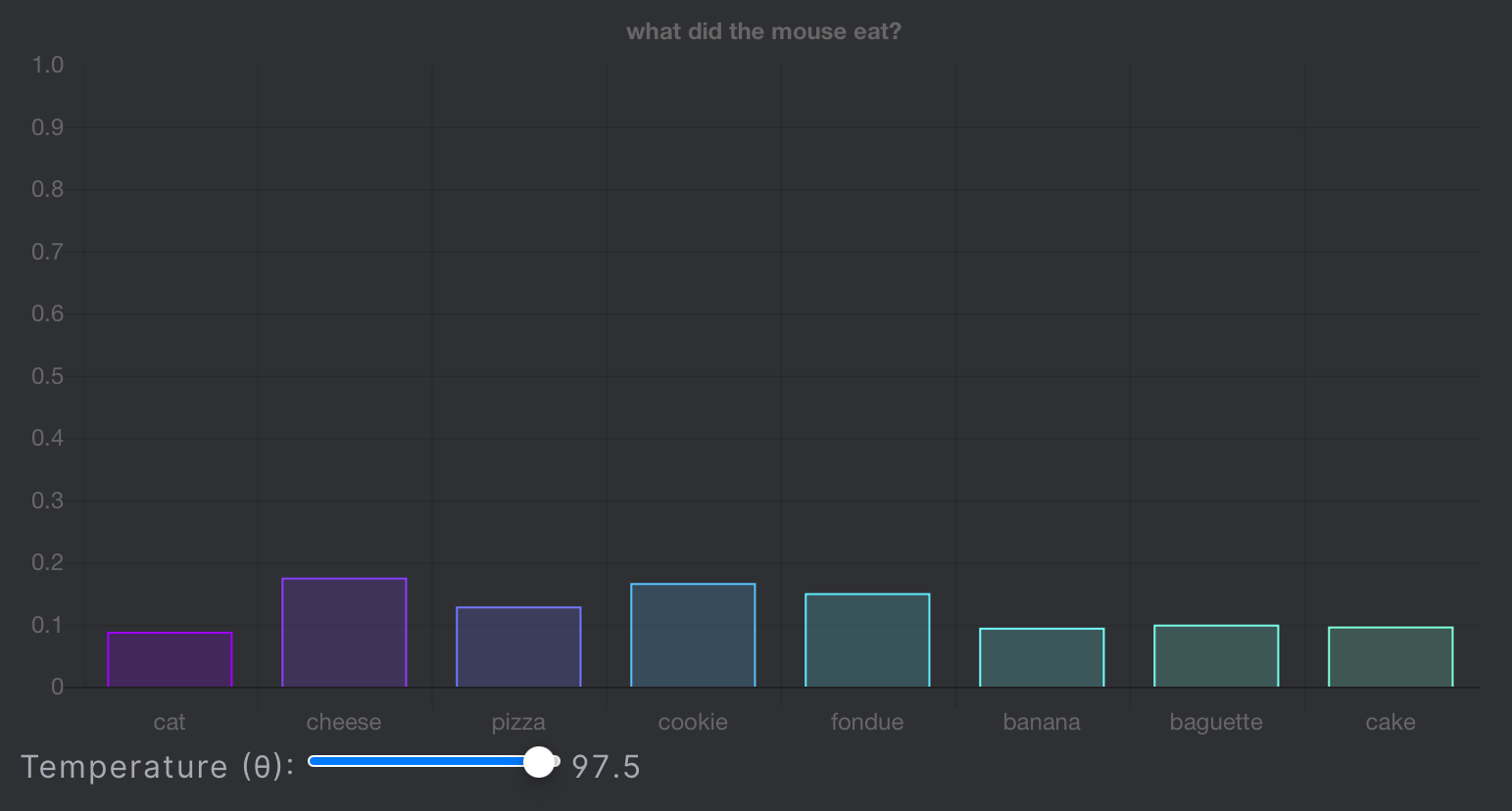
temperature 값이 높을 때 :
온도(Temperature) 값이 클 경우 → 모든 토큰의 확률값이 평평해짐 → 더욱 다양성 있는 텍스트가 생성될 확률이 높아짐

References
토큰화 https://shaankhosla.substack.com/p/talking-tokenization
인컨텍스트러닝 http://arxiv.org/pdf/2005.14165
Emergent ability https://arxiv.org/abs/2206.07682
Temperature https://blog.lukesalamone.com/posts/what-is-temperature/
인프런 모두를 위한 대규모 언어 모델 LLM(Large Language Model) Part 1 (일부 포함)
