LLM
1.[Book Review] LLM의 기초 뼈대 세우기1
References LLM을 활용한 실전 AI 애플리케이션 개발, 허정준 지음 https://product.kyobobook.co.kr/detail/S000213834592 https://www.softwaretestinghelp.com/data-mining-vs-ma
2.LLM 용어정리
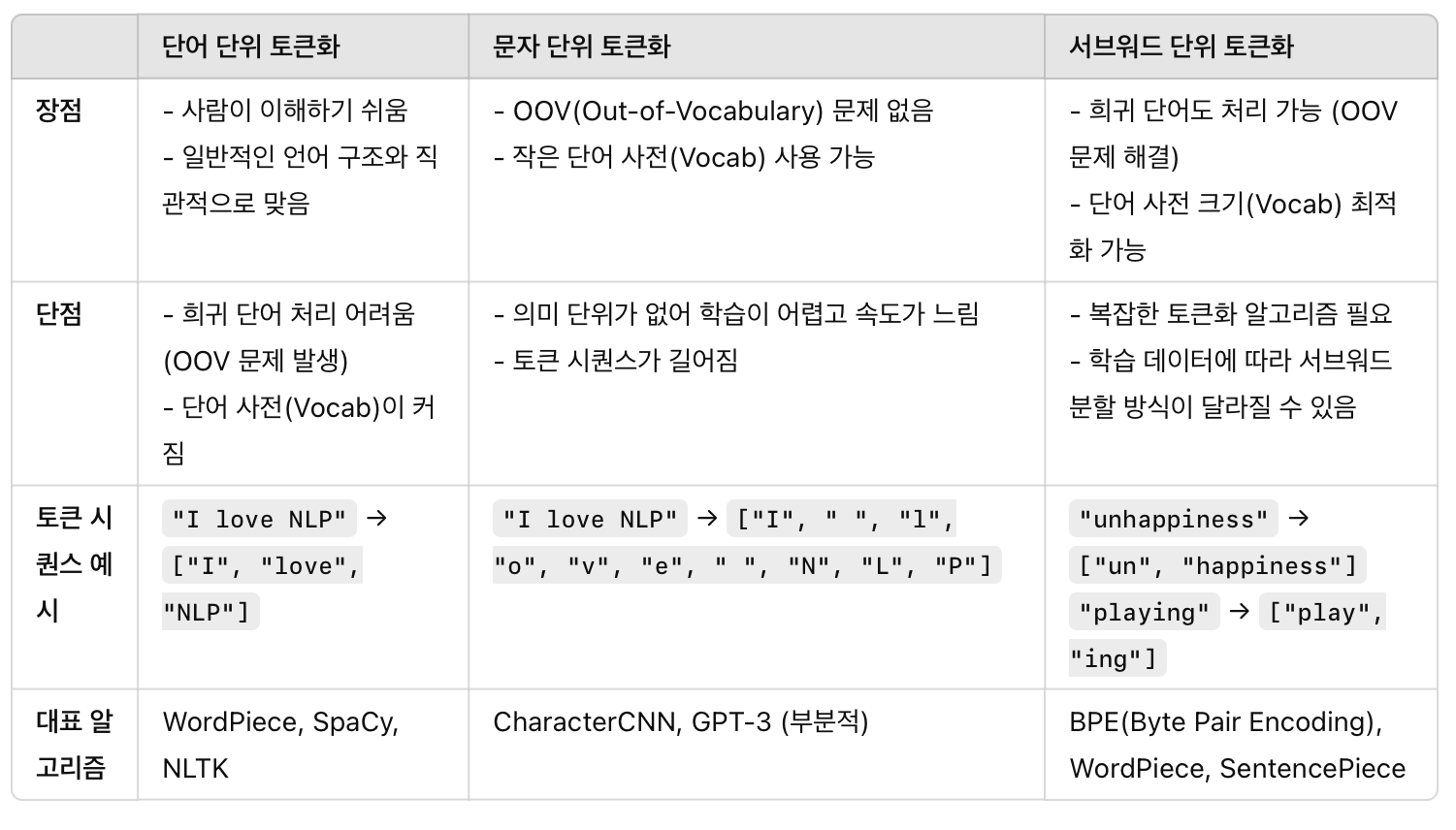
1_1) Token 정의 : 텍스트를 구성하는 개별 단위1_2)Tokenization 정의 : 주어진 텍스트를 개별 토큰으로 분리하는 과정. : 공백, 구두점, 특수 문자를 기준으로 나눌수도 있지만, 문맥에 따라 다를 수도 있음. 한국어는 형태소 단위로 토큰화 할때도
3.서브워드 토크나이저 개발기1
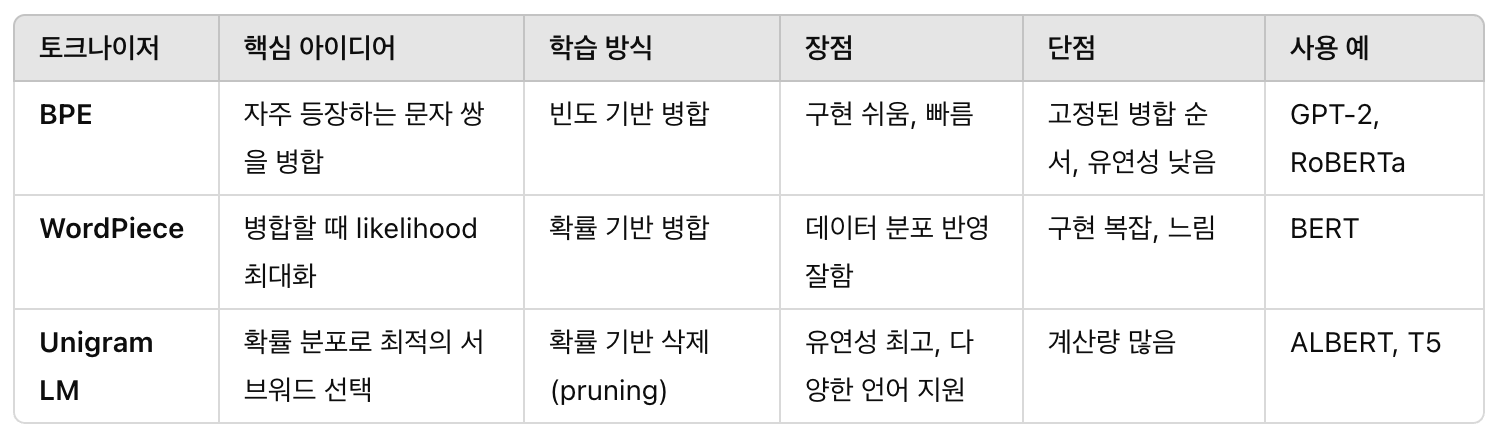
목표 | BPE, WordPiece, Unigram 토크나이저를 만들어보고, 세가지가 어떻게 다른지 비교해본다. 즉, 테스트 텍스트를 서브워드 토큰화 후, 각 모델 별 결과를 확인해본다. 이번 페이지에서는 먼저 주요 내용을 학습한다. 토크나이저 개발에 활용할 대표 모
4.서브워드 토크나이저 개발기2
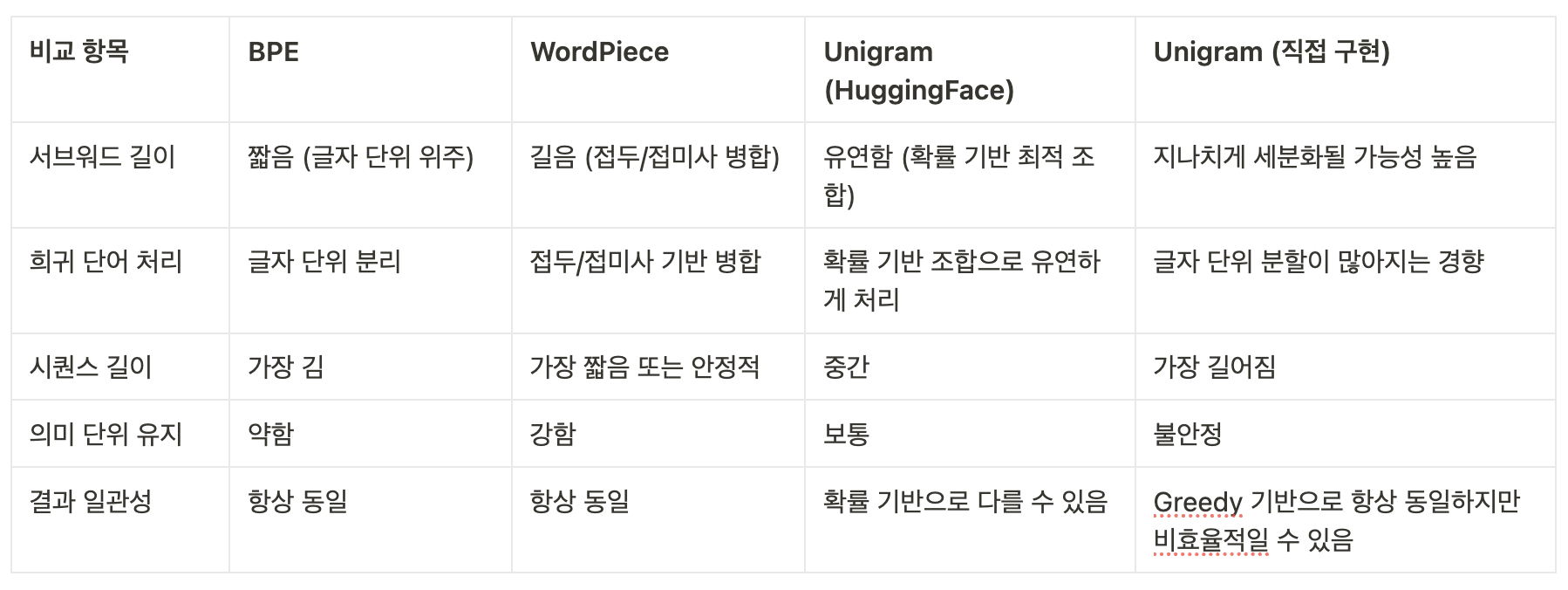
본 과제의 목적은 자연어처리(NLP)에서 널리 사용되는 세 가지 서브워드 토크나이저(BPE, WordPiece, Unigram)를 직접 학습하고 비교 분석하는 것이다. 각 모델을 동일한 학습 데이터로 훈련시키고, 토큰화 결과를 비교하여 장단점과 차이점을 도출하였다.
5.RLHF(Reinforcement Learning from Human Feedback)
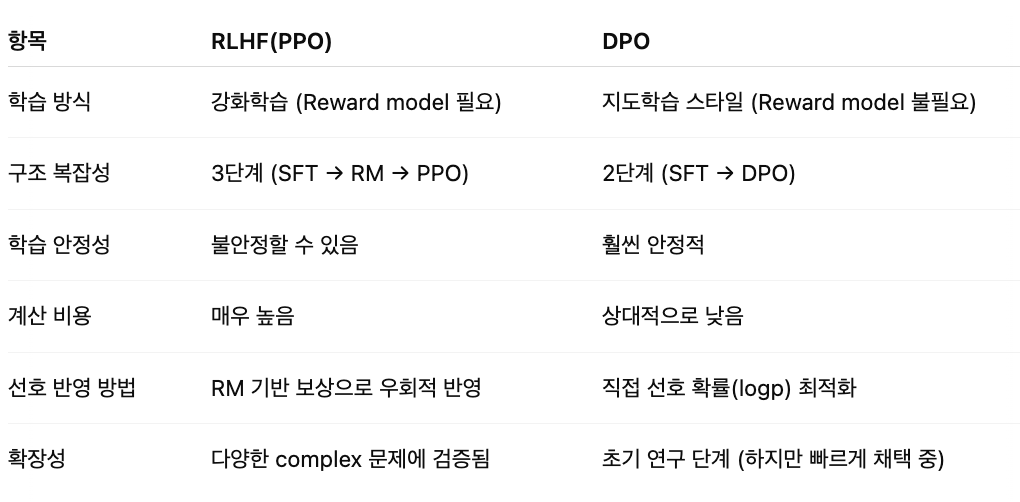
GPT-3는 인간 의도를 잘 반영하지 못했기 때문에, RLHF로 사람 선호를 반영하려고 했지만, 구조가 복잡하고 비용이 높아서, 최근에는 강화학습 없이 간단하고 빠르게 선호를 반영하는 DPO 방법이 등장했다.
6.Lang Chain의 이해

Lang Chain 라이브러리 LLM 자체를 만드는게 아니라, 만들어진 모델을 API통해 가져오고, 나만의 챗봇이나 서비스를 만드는데 집중 할 수 있도록 함.
7.나만의 에이전트를 만들기 전
RAG, CoT, FunctionCalling, ReAct, Prompt Chaining
8.RAG는 언제써야할까? 그리고 LangChain?
자연어처리(NLP)에서 RAG는 Retrieval-Augmented Generation의 약자이다.RAG를 구성한다는 건, 단순히 언어 모델(예: GPT, BERT)을 쓰는 것보다 외부 지식 소스나 문서들을 검색해서, 이것을 답변에 활용하는 시스템을 만든다