References
- 인프런 강의 [모두를 위한 대규모 언어 모델 LLM] 일부 발췌
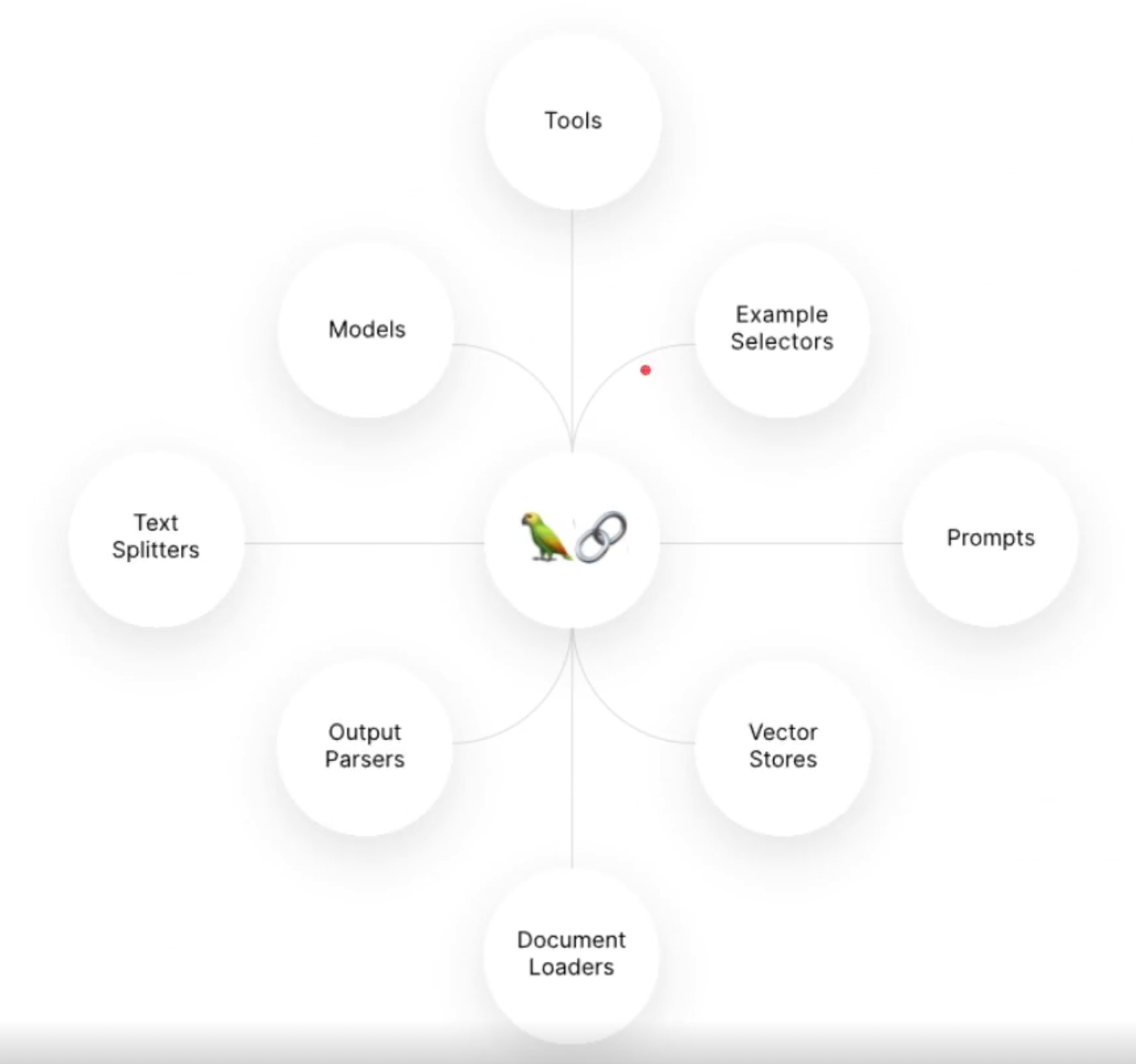
Lang Chain 라이브러리
LLM 자체를 만드는게 아니라, 만들어진 모델을 API통해 가져오고, 나만의 챗봇이나 서비스를 만드는데 집중 할 수 있도록 함.
-자연어 처리와 관련된 다양한 기능을 제공해주는 라이브러리.
https://www.langchain.com/
LLM에 학습되지 않은 지식을 주입하는 방법 2가지
1)Fine Tuning : 텍스트 데이터 소스 이용해서 주입
2)RAG(Retrieval Augmented Generation) : 텍스트 데이터 소스를 embedding 하여 vector stores에 저장하고, 프롬프트 구성 시 외부 데이터 소스로 부터 가져온 텍스트 데이터를 이용하여 구성하고, LLM으로 부터 답변 얻어냄.
Lang Chain 장점
1)손쉬운 구현
2)방대하고 긴 지식이라도 vector store에 DB형식으로 저장하기 때문에 긴 컨텍스트의 지식 주입 가능, 기존 LLM(GPT3.5 409 6토큰제한)한계인 긴 텍스트 제한 문제 완화
3)출처 확인 가능 (할루시네이션 및 블랙박스 문제 최소화), 순수한 Fine Tunning 대비 명확학 출처와 함께 텍스트 생성 가능.
파운데이션 모델
주로 open AI, meta에서 개발한 모델을 일컬음. 해당 모델을 이용해 추가 개발 가능.
1) OpenAI - GPT(GPT-1, GPT-2, GPT-3, GPT-3.5, GPT-4)
2) Meta(Facebook) - Llama 1, Llama 2
3) Google - PaLM
전이학습
학습(Transfer Learning) 또는 Fine-Tuning이라고 부르는 기법은 이미 학습된 Neural
Networks의 파라미터를 새로운 Task에 맞게 다시 미세조정(Fine-Tuning)하는 것을 의미.
대량의 corpus 데이터셋으로 Pre-training -> 목적에 맞게 Fine-Tuning
RLHF 기법 적용 후, 제품화 진행
위험한 발언, 부적절한 결과 있는 경우, 사람의 피드백 통해 가중치 부여하고 안정적인 서비스 상용화.

