[요약]
GPT-3는 인간 의도를 잘 반영하지 못했기 때문에, RLHF로 사람 선호를 반영하려고 했지만, 구조가 복잡하고 비용이 높아서, 최근에는 강화학습 없이 간단하고 빠르게 선호를 반영하는 DPO 방법이 등장했다.
1. 문제의식
기존 GPT-3는 다음 토큰 예측만 잘하도록 학습됨 →
➔ 사용자의 지시나 의도를 잘 따르지 못함
➔ 잘못된 정보(factual errors), 유해한 발언, 지시 무시 같은 문제가 생김
2. InstructGPT / ChatGPT (도입)
목적
-"사용자 지시를 따르는" LLM을 만들자.
-단순 토큰 예측이 아니라 human-aligned behavior를 학습
방법 (RLHF-Reinforcement Learning from Human Feedback 등장)
SFT (Supervised Fine-tuning): 사람 답변으로 미리 튜닝
RM (Reward Model): 사람 선호를 점수화한 모델 학습
PPO (Proximal Policy Optimization): RM의 보상을 최대화하도록 LLM 강화학습
3. RLHF의 구조
Step별 구성
- SFT: 좋은 예시 답변을 지도학습
- Reward Model: 좋은 답변에 높은 점수를 주는 판별기 학습
- PPO: Reward Model을 기반으로 LLM을 강화학습
장점
- 사용자 의도에 맞는 모델 생성 가능
- 다양한 task를 유연하게 다룸
문제점 (한계)
- 구조 복잡: SFT + RM 학습 + PPO 세 단계를 거쳐야 함
- 학습 불안정: PPO는 튜닝이 민감하고 training variance가 큼
- RM 의존성: RM이 부정확하면 전체 학습이 망가짐
비용 부담
RM 따로 학습, PPO 튜닝까지 리소스 소모 큼
4. DPO (Direct Preference Optimization) 등장
등장 배경
Reinforcement Learning (강화학습) 없이 사람 선호를 바로 반영해서 학습할 수 없을까?
구조를 단순화하고, 학습을 더 빠르고 안정적으로 만들자
방법
"A가 B보다 좋다"는 선호 쌍 데이터만 있으면
LLM이 A의 확률을 B보다 높이게 직접 튜닝하는 방식
강화학습을 안 씀 (RM도 필요 없음)**
장점
- 구조 단순화 (SFT → DPO만)
- 계산 효율성 (PPO 생략)
- RM 학습 없이 사람 선호를 직접 반영
- 학습 안정성 높음
단점
아직 다양한 complex setting에서는 RLHF보다 확장성이 제한될 수도 있음 (초기 연구 기준)
5. 모델별 핵심 비교
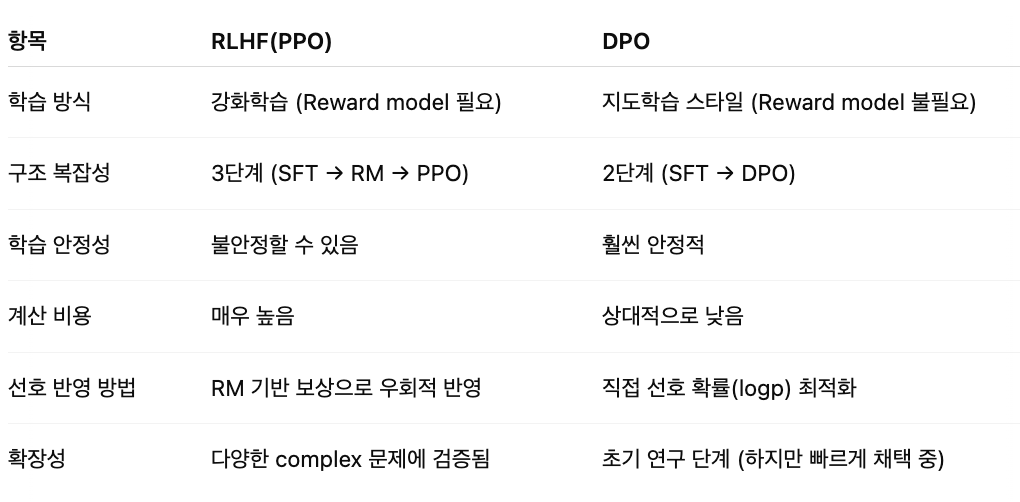
SFT vs DPO
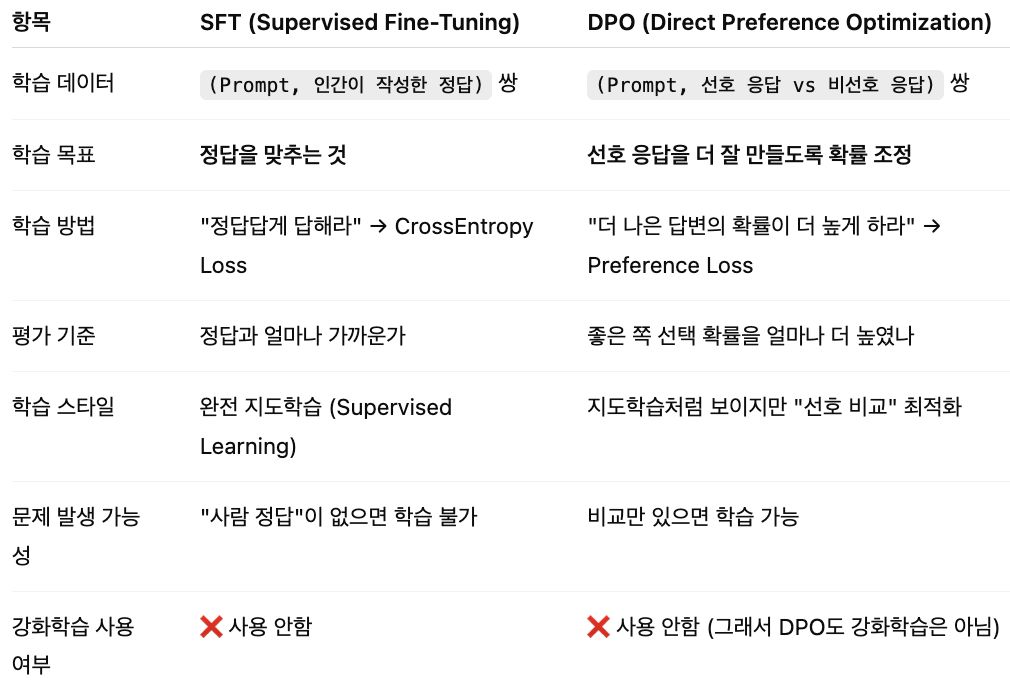
SFT는:
"이 질문에는 반드시 이 답을 써야 한다" = 딱 하나의 정답을 따라감. = 모범답안 복붙 훈련
DPO는:
"이 답이 저 답보다는 낫지 않아?" = 여러 답 중 더 나은 쪽을 고르는 감각을 키워줌. = 좋은 답 고르는 감각 훈련
📌 요약 : SFT는 '정답을 따르게', DPO는 '선호를 따르게' 튜닝
