1. 텐서(Tensor)의 개념과 특징
텐서(Tensor)는 다차원 배열(Multi-dimensional array)
스칼라, 벡터, 행렬 모두 텐서에 포함되며, 차원의 수에 따라 구분함.
-스칼라(Scalar): 0차원 텐서, 하나의 숫자.
-벡터(Vector): 1차원 텐서, 숫자가 나열된 형태.
-행렬(Matrix): 2차원 텐서, 숫자가 행과 열로 나열된 형태.
-그 이상의 차원(N-dimensional Tensor): 3차원 이상의 구조로 숫자들을 나열한 형태.
예시
스칼라: 3
벡터: [1, 2, 3]
행렬: [[1, 2], [3, 4]]
3차원 텐서: [[[1,2],[3,4]], [[5,6],[7,8]]]2. 텐서의 주요 연산
텐서 생성: 다양한 방법으로 텐서를 만들 수 있음. (예: 랜덤, 등차수열, 특정 값 등)
텐서의 차원: shape(모양)을 사용해 각 차원의 크기를 나타냄.
텐서의 연산:
-요소별(Element-wise) 연산: 텐서의 같은 위치에 있는 요소끼리 연산.
-행렬 곱(Matrix multiplication): 행렬끼리 곱셈하는 연산.
-전치(Transpose): 행렬의 행과 열을 바꾸는 연산.
-역행렬(Inverse matrix): 행렬을 곱했을 때 단위 행렬(Identity matrix)을 만드는 행렬.
-축(Axis): 텐서의 연산 시 기준이 되는 차원을 나타냄.
3. 파이썬 라이브러리 및 모듈 정리
(1) torch (PyTorch)
import torch
import torch.nn as nn
import torch.optim as optim역할 및 용도:
torch: 텐서를 생성하고 다양한 수학 연산을 할 수 있는 PyTorch의 기본 라이브러리.
torch.nn: 신경망(neural network) 모델을 만들 때 사용하는 모듈을 포함하며, 줄여서 nn이라 표현함.
torch.optim: 모델의 파라미터 최적화(학습)를 위한 최적화 알고리즘을 제공하며, 보통 optim으로 줄여 씀.
(2) numpy (넘파이)
import numpy as np역할 및 용도:
파이썬에서 수치 계산과 다차원 배열을 다룰 때 사용.
벡터화 연산(vectorized operation)으로 효율적인 수치 연산 제공.
PyTorch와 호환 가능하며 데이터 변환 시에도 많이 활용.
(3) matplotlib
import matplotlib.pyplot as plt역할 및 용도:
파이썬의 대표적인 데이터 시각화 라이브러리.
데이터를 시각적으로 표현하고 그래프를 그릴 때 사용.
🔖 한 줄 정리
텐서는 다차원 배열로 이해하며, PyTorch는 텐서를 다루기 좋은 대표적인 라이브러리.
넘파이는 다양한 수치 연산과 배열 처리를 효율적으로 하는데 쓰이고, Matplotlib은 데이터를 시각화하는데 활용되므로, 적재적소에 잘 활용해야함.
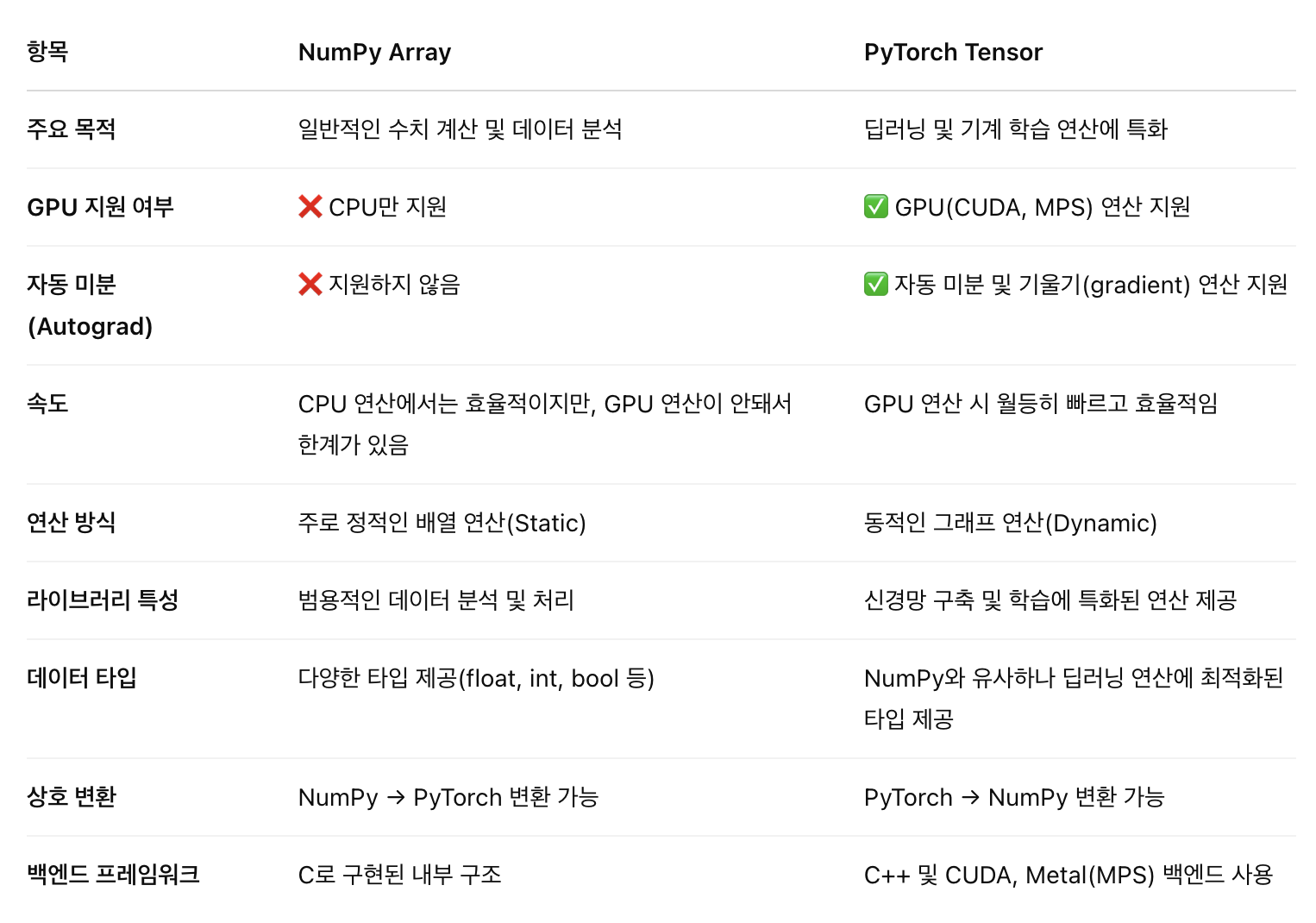
NumPy Array vs. PyTorch Tensor
둘다 다차원 배열을 다루는데 사용하는데, 둘 다 써야하는 이유?
목적이나 사용되는 방식에 있어 차이가 있음.
1️⃣ NumPy Array
일반적인 수치 데이터 처리, 통계적 분석, 머신러닝 전처리 시 (CPU 기반 작업, GPU 불필요한 작업에 적합)
2️⃣ PyTorch Tensor
GPU를 활용한 빠른 연산, 딥러닝 모델 구축, 자동 미분이 필요한 연산 시 (GPU 활용 및 딥러닝에 필수적)
딥러닝에서 미분 또는 자동미분이 필요한 이유
1. 미분(Differentiation)의 개념
미분이란 "어떤 함수의 기울기를 구하는 것"
함수가 있을 때 "입력(x)이 조금 바뀌었을 때 출력(y)이 얼마나 변화하는지" 를 나타내는 수학적 계산 방법.
예-차가 달릴 때 "속력"은 위치 변화(이동거리)를 시간으로 미분한 값이에요.
예-언덕을 오를 때 얼마나 경사가 가파른지(기울기)를 나타내는 값이에요.
🔖 예시로 쉽게 보기:
y=2xx가 1에서 2로 바뀔 때, y는 2에서 4로 바뀜.
이때 x가 1 증가했을 때 y는 2 증가했으니, 이 함수의 기울기(미분 값)는 2임.
즉, 이 함수는 x가 얼마나 바뀌든 항상 기울기(미분값)가 2임.
2. 자동 미분(Automatic Differentiation)의 개념
자동 미분은 컴퓨터가 복잡한 수식을 자동으로 미분해주는 기술.
딥러닝에서 사람이 일일이 손으로 미분 계산을 하려면 거의 불가능할 정도로 오래 걸리고 어려움.
자동 미분은 컴퓨터가 연산의 흐름을 기억하고, 함수에서 사용하는 모든 연산을 따라가면서 미분값을 자동으로 계산해줌.
PyTorch의 자동 미분은 특히 이 작업을 쉽게 할 수 있게 도와줌.
3. 딥러닝에서 왜 자동 미분을 해야 할까?
딥러닝에서 자동 미분이 필수적인 이유는 간단히 말해서 "학습" 에 있음.
딥러닝 모델은 보통 많은 파라미터(weight, 가중치)를 가짐.
이 가중치들이 모델이 얼마나 잘 예측하는지 영향을 줌.
따라서, 모델이 더 정확해지기 위해선,
모델의 예측 오차(Error, Loss)를 줄이는 방향으로 가중치를 조금씩 조정해야함.
바로 여기서 미분이 필요하다.
미분값(기울기)을 이용하면, 어떤 가중치를 얼마나 바꿨을 때 오차가 줄어들지 방향을 알 수 있음 그래서 딥러닝에선 보통 다음 과정을 반복함.
-
입력을 넣고 예측을 하고 → (순전파, Forward)
-
오차를 계산하고 → (Loss, 손실함수)
-
오차의 미분값을 계산한 후 → (역전파, Backward)
-
미분값을 바탕으로 가중치를 조금씩 조정. → (최적화, Optimizer)
이 과정 중 3번 (오차를 미분하는 작업)에서 자동 미분이 쓰임.
4. 파이토치에서 편미분(Partial Differentiation)이란?
편미분은 여러 개의 변수를 가진 함수에서 "한 개의 변수만 관심있게 보고 나머지 변수는 고정한 상태에서 미분하는 것"
미분이 1개 변수(x → y)의 관계에서 기울기를 구하는 것이었다면,
편미분은 2개 이상의 변수(x, y, z, … → output) 중 한 개의 변수만 움직였을 때 결과(output)가 얼마나 변하는지 보는 것이다.
🎯 쉽게 이해하는 예시
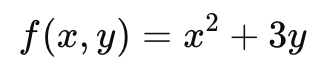
이 함수는 두 개의 변수(x, y)를 가지며, 이때 편미분을 하면 두 가지로 나눠서 볼 수 있다.
① x로 편미분
:y를 고정하고 x만 바꿨을 때, 함수가 어떻게 바뀌는지를 확인.
- y는 상수처럼 취급해서 고정함.
- 그러면, 원래 함수에서 3y 부분은 상수(숫자)라 생각하고 미분하면 0이 됨
- 남은 엑스제곱만 미분하면 됨.
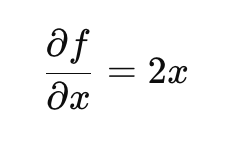
② y로 편미분
이번엔 x를 고정하고 y만 바꿔서 생각해보자.
- 이 경우엔 엑스제곱이 상수처럼 취급됨. 미분하면 0이 됨.
- 3y 부분만 미분하면, y에 대한 1차 함수니까 미분하면 계수인 3인 남음
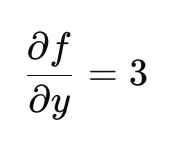
파이토치가 하는 미분은 편미분!
파이토치에서는 변수가 매우 많다.
딥러닝 모델의 손실 함수(loss)는 매우 많은 가중치(weights)에 따라 달라짐.
그래서 파이토치가 하는 자동 미분은 편미분이다.
- 딥러닝 모델은 변수(가중치, weights)가 매우 많음.
- 손실 함수(Loss)는 수백 개, 수천 개의 변수를 가진 매우 복잡한 함수임.
- 파이토치는 각 변수(가중치)별로 손실함수를 편미분하여, "각 가중치를 얼마나 조정할지"를 자동으로 계산함.
이렇게 계산된 값을 가지고, 최적화 알고리즘(optimizer)이 각 가중치를 적절히 조정해서 모델을 학습시킴.
🎯 왜 딥러닝에서 편미분이 중요한가?
딥러닝 모델은 수많은 가중치(weights)를 가지고 있으며, 모델을 최적화하려면 각 변수(가중치)에 대해 독립적으로 미분(편미분)을 수행해, 각각의 가중치를 어떤 방향으로, 얼마만큼 움직일지 알아야 한다.
그래서 딥러닝에서는 무조건 편미분이 필수적이고,PyTorch는 이를 자동화해서 효율적으로 처리해준다.
🔖 한 줄 요약
- 편미분은 다변수 함수에서 한 변수씩만 따로 미분하는 것이고,
- 딥러닝에서 파이토치가 자동 미분을 수행할 때 쓰는 방식이 바로 편미분이다.
