1. 파이썬 소개 및 개발 환경 설정
파이썬은 어디에 활용될까?
- 데이터 분석
- 머신러닝
- 웹 개발
- 자동화
그렇다면 해야할 부분은?
먼저 만들고, 필요한 부분을 채워넣는 게 더 좋다.
코랩 vs 코드편집기
코랩
- 구글 클라우드 기반 Jupyter 노트북 환경
- 별도로 소프트웨어 설치 필요 X
- 머신러닝, 데이터 분석 등 작업에 사용
- GPU / TPU와 같은 하드웨어 가속기를 무료로 사용할 수 있어 딥러닝 작업에 적합
- 주피터 노트북 파일(.ipynb) 형식을 지원, 코드와 문서를 통합해 작성 가능
- 코드와 결과를 공유하기 쉽고, 협업 간편
코드편집기
- VScode / Pycharm
- 컴퓨터 설치
- 디버깅, Git 통합, 코드 완성 등의 기능 제공
- 로컬 환경에서 작업하기에 인터넷 연결 필요치 않음
2. 가상환경에 대한 이해
가상환경
ex)
-
프로젝트1(환경 1)
- 패키지 1 버전 1.x
- 패키지 2 버전 2.x
-
프로젝트2(환경2)
- 패키지1 버전 2.x
- 패키지2 버전 3.x
별도의 환경을 통해 프로젝트 업데이트 진행 → 그렇기 때문에 Python 환경을 나누어 진행하는 이유이다.
- 각각 프로젝트가 필요로 하는 재료가 있음
- 시차에 따른 환경의 격리가 필요하다
실습
conda env list
입력을 통해 콘다 환경에 진입
- 콘다 환경의 리스트를 확인하는 방법
conda create -n ai2 python=3.8
- -n: name
- python=3.8: 아나콘다 내부에서 돌아가는 파이썬 환경
- 디렉토리 생성
conda activate ai2
- ai환경으로 진입했다는 의미
py는 코드를 전체 다 돌린다느 느낌
- 필요한 패키지(함수)를 만들어서 다른 곳에서 호출할 수 있단 장점
💡 ipynb
- 결과를 바로바로 확인할 수 있다는 장점
- ipynb는 코드 작은 것들을 하나 하나 확인한다는 느낌
패키지란?
- 프로그램 개발에서 모듈을 묶어 관리하기 위한 단위
장점
- 코드 관리가 쉬워짐
- 코드 재사용 가능
- 협업 원할
pandas 라이브러리 불러오기
- 커널 선택 후,
!pip install pandas - 이후 pandas 패키지 사용 가능
짧게 할 수는 없나?
- pd라고 보통 칭하기 때문에 pd라고 해줌
모듈? 패키지? 라이브러리?

패키지: 비슷한 기능을 하는 모듈을 묶어서 관리하는 단위
- 함수 단위로 관리
- (간단한 이해) 하나의 폴더
모듈: 프로그램 사용 중 작은 기능의 단위
- 하나의 py파일
- 모듈이 모여 하나의 패키지가 된다
3. 변수와 자료형
변수:
정의: 데이터 특정 이름을 붙여 저장
- 여러 형태 데이터를 하나 이상의 변수로 설정 가능
a = 1
b = “python”
c = [ 1 , 2, 3]
자료형:
- 데이터 자료형 규명은 가장 기본적이고 중요
- 파이썬에서는 데이터의 자료형을 자동으로 지정
- 자료형에 따라 분석의 기법이 달라질 수 있음
- // : 몫
- **: 제곱
문자열:
- 문자, 단어 등으로 구성된 문자 집합
- 문자열 또한 여러 형태도 연산 가능
- indexing: 특정 위치의 문자 추출
- Slicing: 특정 위치 문자를 잘래냄
- 여러줄을 쓰고 싶을 떈 ‘’’ or “””을 사용해 줄바꿈
- 곱하길 사용해 반복할 수도 있음
인덱싱과 슬라이싱(중요!)
- 프로그래밍은 0부터 시작
- indexing: [n]번째 숫자를 출력
print(str2[0]) # <- indexing - slicing: [a:b] → a이상 b미만
str4 = 'python programming' print(str4[:6]) #python print(str4[7:]) #programming print(str4[:]) #python programming - 역슬레시를 통해 작은 따옴표 출력 가능
text1= '나는 "서준범"입니다' text2= "나는 '서준범'입니다" text3= '서준범\'s 레시피' print(text3) 서준범's 레시피 - 줄바꿈 → \n
- 줄바꿈도 인덱싱으로 출력 가능
text4 = "나는 \n서준범 \n입니다" print(text4) print(text4[4]) 나는 서준범 입니다
- 줄바꿈도 인덱싱으로 출력 가능
- find / index (위치 알려주기)
- find: 못찾을 때 → -1 출력
- index: 못찾을 때 에러
- 주요 함수 예제
a = 'hobby' print(a.count('b')) print(a.find('o')) print(a.find('k')) print(a.index('k')) print('asdf'.join(a)) print(a.upper()) 2 1 -1 error hasdfoasdfbasdfbasdfy HOBBY- find 문자열을 찾을 수 없을 때 -1 출력
- index 에러 출력
- join 사이 사이에 삽입
- replace & split
b = 'Life is too short'
b.replace('Life', 'Your leg')
'Your leg is too short'
b.split(' ')
['Life', 'is', 'too', 'short']split함수를 쓰면 자동으로 리스트 형태로 바뀌게 된다
- split / join 활용 예제
a = 'hobby'
a2 = ','.join(a)
a3 = a2.split(',')
a4 = ''.join(a3)
print(a2)
print(a3)
print(a4)
h,o,b,b,y
['h','o','b','b','y']
hobbyjoin함수는 다시 배열을 다시 문자열로 바꿔주는 기능을 하기도 함
예제 1
a = '890724'
a2 = a[0:2]
a3 = a[2:4]
a4 = a[4:6]
print(a2+'/'+a3+'/'+a4)
----
강사 예시
ex1 = '890724'
print(ex1[:2]+'/'+ex1[2:4]+'/'+ex[4:6])예제 2
a = '20190603'
a2 = a[0:4]
a3 = a[4:6]
a4 = a[6:8]
print(a2+'-'+a3+'-'+a4)예제 3
1번째
phone = '010-1234-5678'
print(phone.replace('-', ''))
2번째
phone = '010-1234-5678'
phone.split('-')
''.join(phone.split('-'))
4. 자료형(매우 중요!)
리스트
-
여러 개의 데이터를 다룰 때, 하나의 변수에 많은 값을 집어넣을 수 있음
-
대괄호를 이용하여 데이터를 묶어줌
-
서로 다른 데이터도 하나의 리스트에 넣을 수 있음
-
리스트도 indexing / slicing이 가능
- append(): 추가
- insert(): 삽입
- remove(): 삭제
-
인덱싱
a = [1,2,3]
a[0] -> 1
a[0]+ a[2] -> 4
a[-1] -> 3음의 순서 설정 가능
- 리스트 활용
list2 = [1,2,3,4]
list3 = [5,6,7,8]
print(list2 + list3) -> [1,2,3,4,5,6,7,8]
print(list2 * 3) -> [1,2,3,4,1,2,3,4,1,2,3,4]
list2[1] = 9 -> [1,9,3,4]
list[1:3] = [10,11,12]
print(list3) -> [5,10,11,12,8]
list[1:3] = [] -> [5,12,8]-더하기와 곱하기 모두 가능
- del[n] / remove(object) / sort() / reverse() /
list2 = [9,4,3,1] **#index** list2.index(3) -> 2 # 찾고자 하는 요소 위치 반환 **#insert** list2. insert(2,10) -> [9, 4, 10, 3, 1] #특정 포지션에 값을 넣을 때 insert 활용 **#append** list.appned(11) -> [9, 4, 10, 3, 1, 11] #배열 끝에서 추가 **#pop** list2.pop() -> 11 #가장 뒤에 있는 값을 꺼내 쓰는 함수 print(list2) -> [9,4,10,3,1] **#count** a = [1,2,3,1] a.count(1) -> 2 #리스트 포함된 요소의 개수
튜플
정의: 리스트와 같이 여러 개의 데이터를 집어넣을 수 있음
- 소괄호를 이용하여 데이터를 묶어줌
- 튜플은 한 번 선언되면, 바꿀 수 없음 → 바꾸고 싶지 않은 값을 넣을 때 활용
- 인덱싱 / 슬라이싱 // 더하기 / 곱하기는 가능
- Packing / Unpacking을 통해 데이터를 추출하거나 생성 가능
- 더하기 / 곱하기를 통해 변형을 할 수는 있음
a = (1,2,3,4,5) **#packing**
one, two, three = (1,2,3) **#unpacking:** 하나의 튜플을 여러 변수로 선언, 변수에 각 데이터 선언
print(one) -> 1
print(two) -> 2
print(three) -> 3
**a[1] = 5 -> 에러 발생.**
딕셔너리
정의: Key와 Value의 pari 형태의 변수
d = {”name”: “Kim”, “value”:100}
- Kime이란 데이터가 name이란 키값과 쌍을 이룸
- 100이란 데이터가 value라는 키값과 쌍을 이룸
- Key를 통해 value를 얻는다 라고 생각하면 됨
- Key 값은 중복되지 않는다
dict1 = {1 : 'a'}
dict1[2] = 'b'
print(dict1) -> {1: 'a', 2:'b'}del dict1[1]
print(dict1) -> {2: 'b'}
#get: key 값이 2인 데이터를 불러와라
print(dict1[2]) -> b
print(dict1.get(2)) -> b print(2 in dict1) -> dict1에 key값이 2인 데이터가 있니? ㅇㅇ 있음 TRUE
print(1 in dict1) -> dict1에 key값이 2인 데이터가 있니? ㅇㅇ 없음 FALSEdict2 = {'name' : 'pey' , 'phone': '01012345678', 'birth': '0904'}
print(dict2.keys()) -> dict_keys(['name', 'phone', 'birth'])
print(dict2.values())-> dict_values(['pey', '01012345678', '0904'])
print(dict2.items()) -> dict_items([('name', 'pey'), ('phone', '01012345678'), ('birth', '0904')])집합
- 중괄호를 이용하여 데이터를 묶어줌
- 데이터간 순서가 없고, 중복을 허용하지 않음
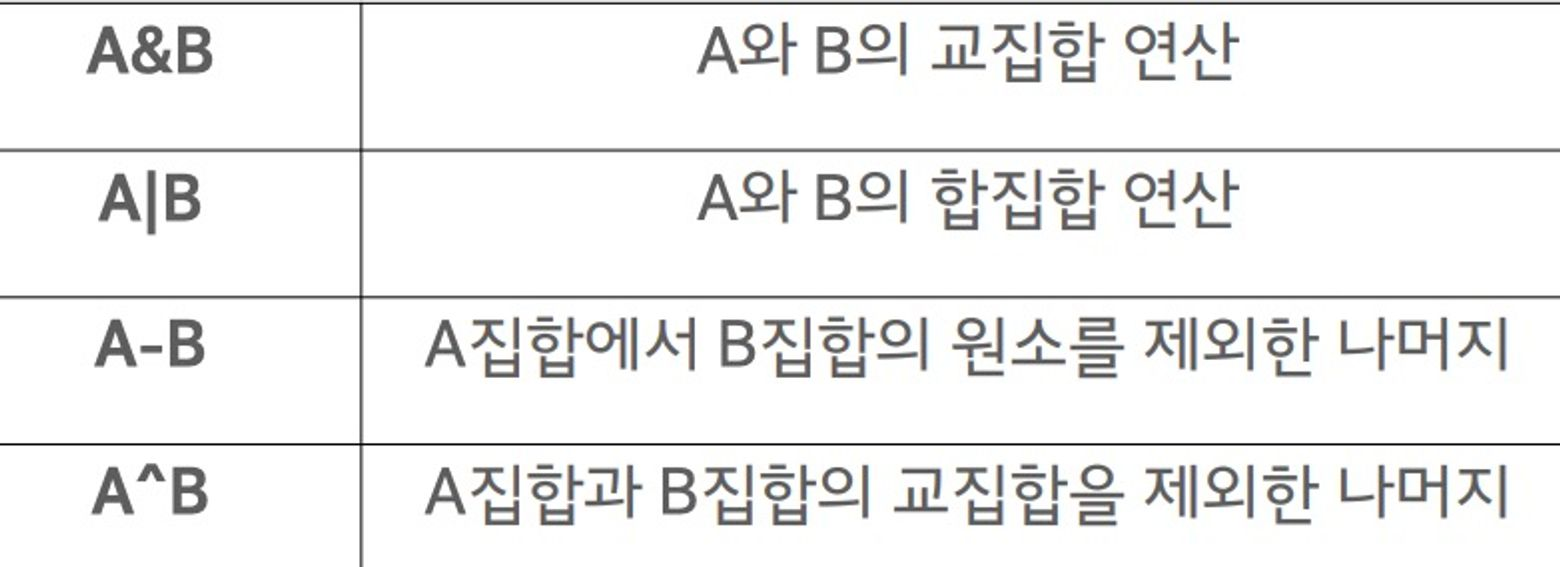
s1 = set([1,2,3]) -> 집합 선언
s2 = {2,3, 4,4} -> 얘도 집합 선언
print(s1) -> {1,2,3}
print(s2) -> {2,3,4}s1.add(4)
print(s1) -> {1,2,3,4}
s2.update([5,6,7])
print(s2) -> {2,3,4,5,6,7}
s2.remove(7)
print(s2) -> {2,3,4,5,6}교집합
print(s1) -> 1,2,3,4
print(s2) -> 2,3,4,5,6,
print(s1&s2) #교집합1 -> {2,3,4}
print(s1.intersection(s2)) #교집합2 -> {2,3,4}합집합
print(s1|s2) #합집합1 -> {1,2,3,4,5,6}
print(s1.union(s2)) #합집합2 -> {1,2,3,4,5,6}차집합
print(s1-s2) #합집합1 -> {1}
print(s1.difference(s2)) #차집합2 -> {1}Boolean
- 빈 문자열 / 리스트 / 튜플 / 딕셔너리 / 0 / None → False
- 값이 비어있으면 False
print(1 == 1) -> True
print(1 != 1) -> False 