Intro: 궁금한 이유
강의에서 mini-batch SGD에 대한 이야기가 나왔다. 강사님은 배치 사이즈를 설정하는 부분을 설명하면서 아래 같은 내용과 뉘앙스로 이야기하셨다.
배치 사이즈를 무한정 키울 수 없다. 어떤 논문(Bag of tricks (2018))에 따르면 배치 사이즈가 일정 수준을 넘어가면 에러가 급격히 늘어나는 것이 확인됐고, 논문에서는 에러가 증가하지 않는 배치 사이즈를 늘리는 방법이 제시되어 있다.
1. 커진 배치 사이즈에 비례해서 learning rate 키워주기
2. learning rate warm-up 적용하기
3. learning rate decay 적용하기
이후에 캐글의 Flower Classification with TPUs라는 문제를 보면서 성능을 향상시키기 위해서 알아보다가 Learning rate에 대한 내용이 생각나서 공부하고 적용해봤다.
1. warm-up을 하는 이유
많은 블로그 포스팅에서 Learning rate warm-up을 하는 이유로 다음과 같이 설명한다.
학습 초반에 모든 가중치들이 무작위로 초기화 되어 있는 상태이고 최종 결과값과는 아주 먼 실수값을 가지고 있다.
따라서 처음부터 높은 learning rate를 gradient에 곱해서 weight를 늘려 나가기 시작하면 불안정한 상태에 빠질 수 있다. 이때 warm-up을 하면 weight를 조금씩 키워서 안정화된 상태로 만들 수 있다.
쉽사리 이해가 가지 않아서 하나씩 풀어서 스스로 납득시켜봤다.
1-1. "최종 결과값과는 아주 먼 실수값"
대부분의 초기화 기법이 0에 가까운 값으로 랜덤하게 가중치를 초기화한다. 학습이 끝난 후에 가중치를 생각해보면 (실제로 어떤 크기의 값을 갖는지는 모르지만) 0에서 멀리 떨어져 있는 값일 것이기 때문에 납득이 간다.
1-2. "불안정한 가중치 / 가중치 안정화"
초기화 상태를 이어서 생각해보면 0에 가까운 무작위 가중치로 학습을 시작하면 초반에는 답에서 아주 먼, 찍는 것에 가까운 대답을 할 것이다.
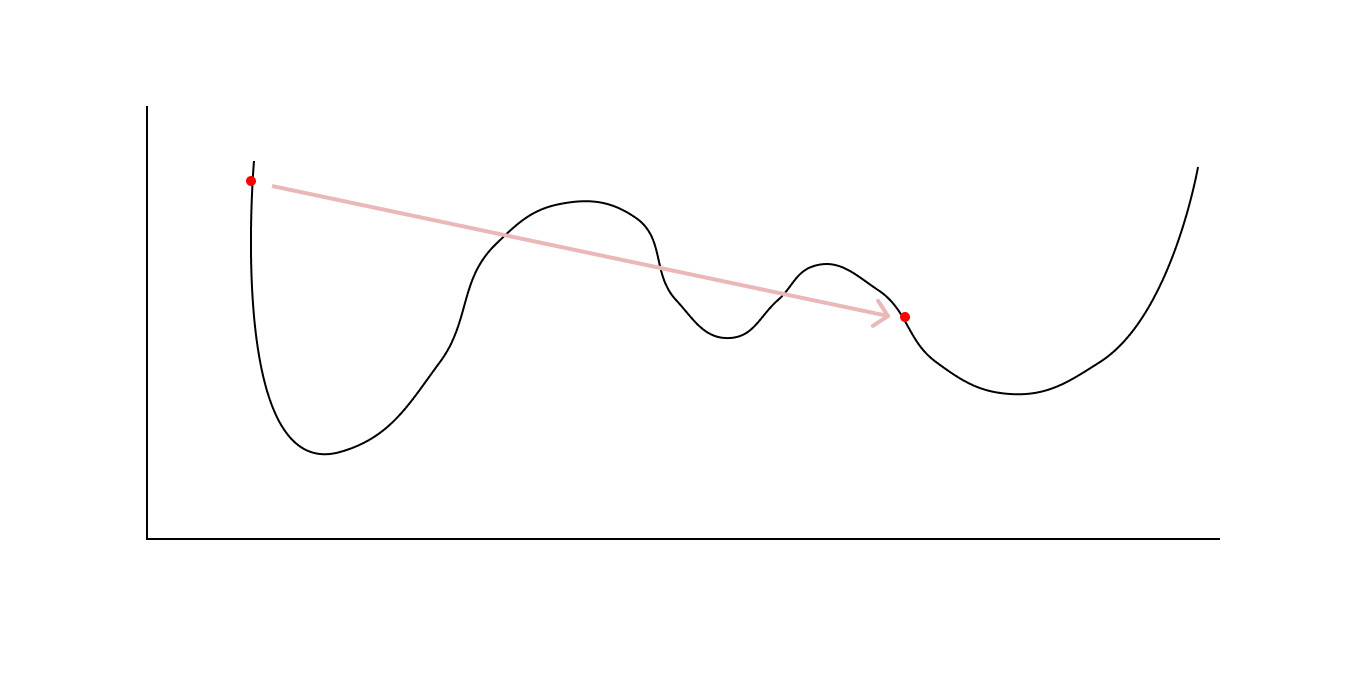
error는 아주 클 것이고 gradient도 크게 나올 것이다. 이렇게 gradient가 클 때 너무 큰 학습률을 적용해버리면 초반에 있던 지점과 근처의 local minimum으로 흘러가는 것이 아니라, 아예 동떨어져 있는 지점으로 옮겨갈 수 있다고 생각했다. 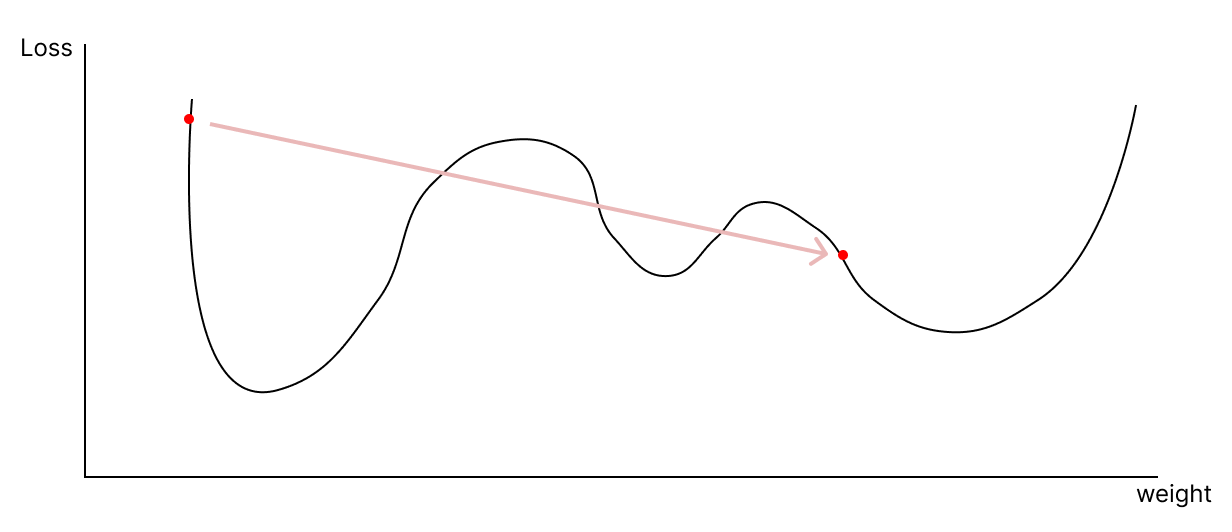
위와 같이 학습을 진행했을 때 loss 함수를 기준으로 바로 앞에 또는 근처에 있는 곳으로 수렴하는 형태가 아니라, 멀리 떨어진 곳으로 가서 큰 error와 gradient가 나오는 형태를 가중치가 불안정하다라고 하는 것 같다고 이해했다.
초반에 learning rate warm-up을 하면 "가중치가 안정화 된다"라는 것은 초반에 작은 learning rate로 weight를 키워서 근처에 있는 곳으로 움직일 수 있게 해주는 것을 의미하는 것 같았다. 초반에 이렇게 수행하서 weight를 키우면 점점 error가 줄어들 것이고 이후에는 learning rate를 의도적으로 키우지 않는다면 자연스럽게 수렴하는 형태로 진행할 것으로 예상되기 때문에 "안정화"라는 표현을 쓴다고 이해했다.
2. Keras에서 learning rate warm-up 하는 법
keras에는 학습 도중에 learning rate를 계속 바꿔주는 방법이 몇 가지 존재하는데, tf.keras.callbacks.LearningRateScheduler 를 써서 입맛대로 맞춰서 써봤다.
2-1. keras.callbacks.LearningRateScheduler
공식 문서에 따르면 이 모듈은 learning rate scheduling을 하는 함수를 파라미터로 전달한다. 인자로 들어가는 함수를 정의할 땐, 다음과 같은 형식으로 작성하면 된다. 아래 코드는 에포크가 10 이상일 때 learning rate를 expoenetial하게 줄이는 스케줄러이다.
>>> # This function keeps the initial learning rate for the first ten epochs
>>> # and decreases it exponentially after that.
>>> def scheduler(epoch, lr):
... if epoch < 10:
... return lr
... else:
... return lr * tf.math.exp(-0.1)위 코드를 참고해서 만든 스케줄러는 아래와 같다.
initial_lr = 0.001
warmup_epochs = 5
total_epochs = 30
def lr_schedule(epoch):
if epoch < warmup_epochs:
return initial_lr * (epoch + 1) / warmup_epochs
else:
return initial_lr
lr_scheduler = tf.keras.callbacks.LearningRateScheduler(lr_schedule)여기서 lr_scheduler는 콜백이기 때문에 fit() 메소드 호출 시에 넣어주면 된다.
2-2. LR warm-up + cosine decay
learning rate를 스케줄링 할 때 warm-up과 decay를 같이 쓰는 경우가 있기 때문에 두 개 모두 사용하는 코드도 작성하고 이용해봤다.
여기서 warm-up은 초반 5회의 에포크에 걸쳐서 0.001까지 선형적으로 늘어나고, 이후에는 25회의 에포크에 걸쳐서 cosine decay를 하도록 했다.
initial_lr = 0.001
warmup_epochs = 5
total_epochs = 30
def lr_schedule(epoch):
if epoch < warmup_epochs:
return initial_lr * (epoch + 1) / warmup_epochs
else:
cosine_decay = 0.5 * (1 + math.cos((epoch - warmup_epochs) / (total_epochs - warmup_epochs) * math.pi))
return initial_lr * cosine_decay
lr_scheduler = LearningRateScheduler(lr_schedule)이것을 시각화 한 결과는 아래와 같다.
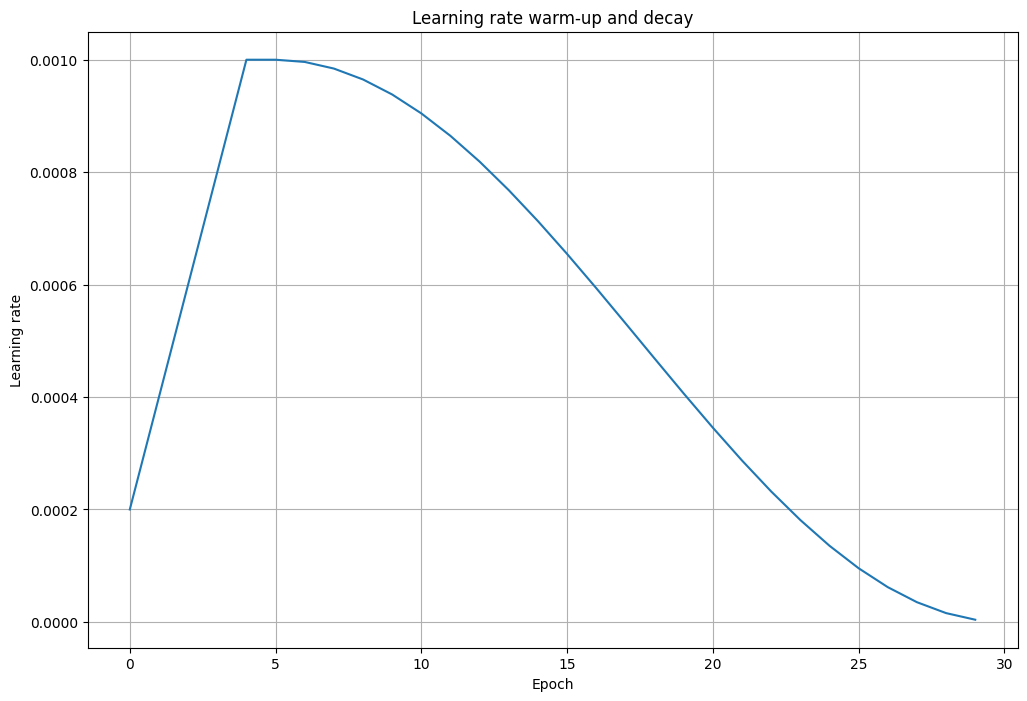
초반에는 선형적으로 목표 지점인 0.001까지 올리고 epoch=5일 때 cosine 모양으로 줄어드는 것을 볼 수 있다.
+ initial_lr을 0.001이 아닌 값으로 설정하고 싶을 때
추가로, 여기서는 learning rate를 다른 optimizer의 default learning rate 값과 동일하게 맞춰줬지만, 0.001이 아닌 값을 사용하고 싶은 상황이 생길 수 있다.
이런 경우에는 아래와 같은 과정을 거쳐서 이용해주면 된다.
1. `initial_lr` 의 값을 변경한다.
2. optimizer 객체를 정의하고 learning rate 값을 지정해주고 이 객체를 이용해서 모델을 컴파일한다. 참고 자료
