VGGNet (2015)
ABSTRACT
convolutional network의 깊이가 깊어짐에 따라 large-scale image recognition의 정확도에 미치는 영향을 연구한 것이다. 이 연구는 이전 연구의 설정에서 (3 x 3) convolution filter를 이용하여 깊이를 깊게 만든 신경망을 이용해 성능을 향상 시켰다.
2 CONVNET CONFIGURATIONS
2.1 ARCHITECTURE

학습에 사용되는 이미지의 사이즈는 224 x 224이고, 전처리로는 RGB의 평균값을 구해서 각 픽셀에서 빼준다.
신경망은 (3 x 3) conv layer로 구성되어 있으며, (3 x 3)을 선택한 이유는 중심과 상하좌우의 개념이 있는 최소 단위이다. (1 x 1) conv layer도 사용하는데, 사용하는 이유는 non-linearity 때문이다. stride와 padding 모두 1로 설정하며, 이는 (3 x 3) conv filter로 연산을 했을 때 입력값의 크기(높이, 너비)와 feature map의 크기를 같게 만든다.
conv layer 뒤에는 FC layer를 3개 쌓는다. 처음 2개는 4096개의 노드로 되어 있고 마지막 1개는 1000개로 되어 있다. 마지막만 다른 이유는 ILSVRC의 문제가 1000종 분류 문제이기 때문이다.
모든 hidden layer에는 activation function으로 ReLU를 이용한다. 하나의 버전을 제외하고는 나머지 버전의 모델에서는 LRN(Local Response Normalization)을 적용하지 않는다. 하나만 사용하는 이유는, 적용 결과 메모리는 많이 사용하지만 ILSVRC dataset에서 성능 향상은 없었기 때문이다.
2.2 CONFIGURATION

(요약) 표에 나와 있는 내용을 설명한다. 명칭을 A-E로 부르고 각 뒤로 네트워크의 깊이가 깊어지는 것이 주요 특징이다. conv layer의 넓이는 16으로 시작해서 max pooling을 지날 때마다 2배씩 넓어진다.
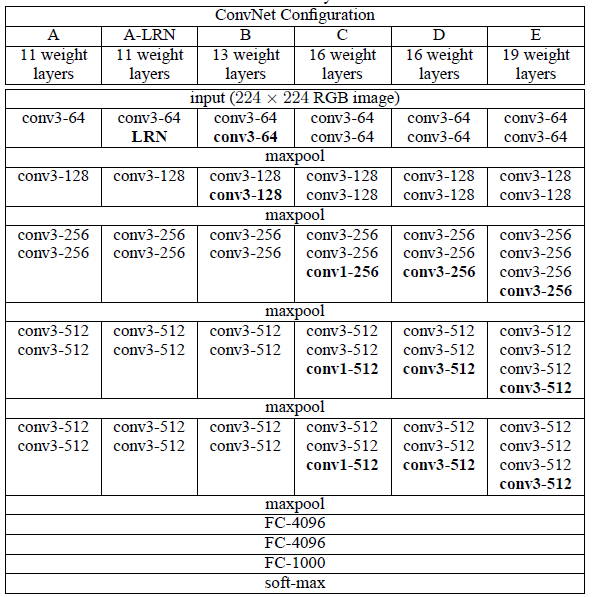
2.3 DISCUSSION


VGGNet은 다른 2012년, 2013년에 최고의 성능을 보여준 모델들과는 다른 점이 몇 개 있다. 이전 모델들이 첫 번째 conv layer에 (7 x 7)과 같이 큰 receptive field를 사용한 것과는 다르게 (3 x 3) filter를 사용했다. 또한 다른 모델에서는 stride=2를 사용하는 경우도 있는데, VGGNet에서는 stride=1로 고정하여 사용한다.
표를 보면 (3 x 3) filter를 2개를 연속해서 사용하는 것을 알 수 있는데, 이것은 (5 x 5) receptive field를 더 효과적으로 반영할 수 있다. 같은 의미로 (3 x 3) filter를 3개 연속해서 이용함으로써 (7 x 7) receptive field를 보는 것과 같은 효과를 낼 수 있다.
(5 x 5) 또는 (7 x 7) filter를 직접 사용하지 않고 (3 x 3) filter를 2개 또는 3개씩 겹쳐서 사용하는 이유는 크게 2가지가 있다.
- 하나를 사용할 때보다 여러 번의 activation function을 거치기 때문에 non-linearity가 증가한다.
- 파라미터 수를 줄인다. 예시로 하나의 (7 x 7) filter의 파라미터는, bias를 제외하면, 가 된다. 3개의 (3 x 3) filter를 사용하면 가 된다.

(1 x 1) filter도 같이 사용하는데 이는 receptive field에 영향 없이 non-linearity를 증가시키기 위해서 사용한다.


ILSVRC-2014에서 가장 좋은 성적을 낸 GoogLeNet은 작은 크기의 filter를 이용하여 깊은 신경망이라는 점은 동일하지만, VGGNet에 비해서 복잡하다. 추가로 전체적인 연산량을 줄이기 위해서 초반부터 feature map의 spatial resolution을 급격하게 줄였다. 하지만 single-network 분류에서는 GoogLeNet보다 VGGNet이 더 좋은 정확도를 보였다.
→ 어쩌면 초반부터 feature map의 크기를 극단적으로 줄이는 것은 피해보는 것이 좋다.
3 CLASSIFICATION FRAMEWORK
3.1 TRAINING
Training procedure (parameter setting)

Multi-scale training image를 sampling하는 과정을 제외하고, ConvNet 학습 과정은 AlexNet과 비슷하다.
- Objective: multinomial logistic regression (= Cross Entropy),
- Optimizer: momentum = 0.9
- Mini-batch SGD: batch size = 256
- Regularization: penalty = , 초반 2개의 FC Layer에서 Dropout = 0.5
- Learning rate: , 성능 향상이 없을 때 줄임.
AlexNet에 비해서 weight도 많고 신경망의 깊이도 깊지만 더 적은 epoch로 학습을 마쳤다. 이런 결과가 나온 이유는 다음 2가지를 예상해볼 수 있다.
- filter의 크기가 더 작아지고 깊이가 깊어지면서 암묵적으로 regularization이 이루어졌다.
- 몇 개의 layer를 pre-initialize했다.
Initialization

실험에서 수행한 방법은 다음과 같다.
- configuration A와 같이 충분히 얕은 모델을 random initialization을 하여 학습을 시킨다. 이때 rand init은 weight를 에서 추출하고 bias는 0으로 초기화한다.
- 더 깊은 모델을 학습시킬 때, 앞에 4개의 conv. layer와 마지막 3개의 FC layer의 weight를 사전에 학습된 config. A의 weight로 init한다.
논문 발표 후에 확인한 것으로는 직접 실험한 과정을 거치지 않고 Xavier initialization을 하면 pre-training을 통한 weight initialization을 하지 않아도 된다.
Obtaining fixed-size images

학습에 사용되는 이미지를 생성하는 과정은 다음과 같다.
- 추출 이전에 이미지를 rescaling한다. 자세한 내용은 아래에서 설명한다.
- 매 SGD iteration마다, 하나의 rescale된 이미지에서 (224, 224) 크기의 crop을 random하게 추출한다.
- Data augmentation을 하는 방법으로는 random horizontal flip과 random RGB shifting을 한다.
Training images rescaling

Training image rescale을 하기 위해서 training scale이라고 부르는 S을 정의한다. S의 값은 224 이상이 되도록 설정해야 한다. S 값이 정해지면 이미지의 짧은 부분의 길이가 S가 되도록 rescale을 한다. 이 과정에서 가로와 세로의 비율을 유지한다. (논문에서 이야기한 isotropically-rescale을 풀어서 설명한 것)
Two approaches for setting

를 설정하는 방법에 따라서 학습 방식을 두 가지로 접근해볼 수 있다. 하나는 S의 값을 지정하는 것이고, 다른 하나는 S 값의 범위를 지정하는 것이다.
첫 번째로 S에 고정값을 넣는 방법을 먼저 보면, S를 256과 384 두 값을 순서대로 지정하여 학습을 진행한다. 먼저 256으로 설정해서 학습을 시키고 이후에 384로 다시 설정하여 추가로 학습을 진행한다. S=384로 바로 하지 않고 두 차례에 나눠서 진행하는 이유는 속도를 향상시키기 위함이다.
추가로 224 이상의 많은 숫자 중 256를 선택한 이유는 이전에 발표된 모델들에서 널리 사용된 값이기 때문이며, 384는 설명하지 않았다. (이 부분은 나중에 구현한다면 바꿔서 진행해봐도 좋을 것 같다)

두 번째 방법은 S 값에 범위를 정해주는 것이다. 설정해주어야 하는 것은 이다. 학습은 속도 상의 이유로 weight가 rand init된 상태가 아닌 S=384로 pre-train된 모델을 fine-tunning하는 방식으로 진행했다.
이 방법의 장점은 어떤 하나의 물체에 대해서 크고 작은 형태를 다양하게 학습하기 좋다는 것이다.
이렇게 다양한 크기의 이미지를 만들어 내는 방법은 data augmentation 중 하나인 scale jittering이라고 볼 수 있다.
3.2 TESTING

학습 이미지를 rescale하기 위해서 S를 이용한 것과 같이, 검증 과정에서도 test scale을 뜻하는 Q를 이용한다. 정확하게 S와 같은 역할을 하지만 독립적인 관계이기 때문에 같은 값을 갖지 않아도 좋다. S마다 몇 개의 Q를 이용하면 성능 향상에 도움이 된다.
검증 과정에서는 학습과 다른 점이 2가지 있다. 첫 번째로 데이터를 Q에 맞춰서 rescale만 하고 crop은 하지 않는다. (Data augmentation에서는 horizontal flip만 수행한다.) 다시 말하면 (224, 224)가 아닌 이미지가 입력으로 들어가 된다. 이런 경우 FC Layer에 들어가는 값의 개수가 정확하게 4096이 아니게 된다. 이 문제를 해결하기 위해 두 번째 다른 점이 나온다.
두 번째로 마지막에 있는 FC layer를 conv. layer로 대체해서 fully convolutional network으로 만든다. 첫 번째 FC layer 대신에는 (7 x 7) filter, 두 번째와 세 번째 FC layer에는 (1 x 1) filter로 대체한다. 이렇게 만드는 이유는 앞서 (224, 224) 크기가 아닌 이미지가 conv. layer를 통과했을 때 4096개보다 적거나 많은 값이 나오는 것을 해소하기 위함이다. (224, 224) 규격의 이미지를 넣으면 FC layer에 들어가는 feature map은 (7, 7, 512)가 되는데, rescale만 한 이미지를 넣게 되면 높이가 넓이가 7을 초과할 수도 있다. 정확한 입력 특성 수가 요구되는 FC layer와 다르게 conv. layer는 입력값의 규격에서 자유롭다.
다만 마지막까지 conv. layer를 이용하게 되면 최종으로 나오는 결과물이 1000개의 값이 아닌 1000개의 feature map(논문에서는 class score map이라고 표현함)이 나오게 된다. 이 map 한 장에 있는 값의 평균값을 구해서 평가를 진행한다.

…..
4 CLASSIFICATION EXPERIMENTS



이미지 분류 결과에 대해서 이야기한다.
- 데이터셋 분할: Training = 1.3M / Validation = 50K / Testing = 100K
- 평가 기준: top-1 error = multi-class classification(다중 분류) / top-5 error = ILSVRC 주 평가 기준
데이터 셋에서 validation set을 test set으로 사용했다고 한다. (그럼 training set에서 일부를 나눠서 실질적인 validation set으로 이용한 건가?)
4.1 SINGLE SCALE EVALUATION

S가 고정된 값일 때는 Q=S로, S가 범위일 때는 로 설정해서 진행했다.
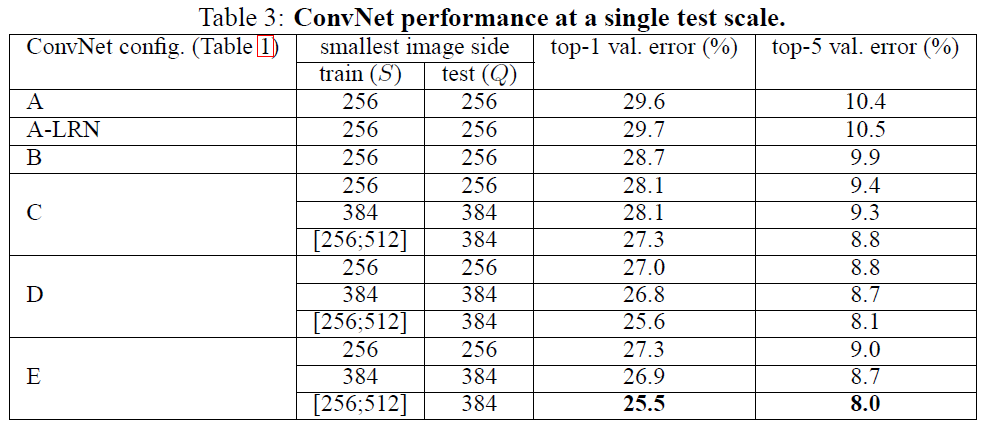

model A에 적용한 결과 Local Response Normalization(LRN)은 성능을 향상시키지 않는다고 판단이 돼서 model A 보다 깊은 모델에는 이용하지 않는다.

ConvNet은 깊이가 깊어지면 에러가 낮아지는 걸 확인했다.
Model C와 D는 깊이가 같고 (1 x 1) filter와 (3 x 3) filter가 다르다는 차이가 있는데 여기서 D가 더 좋은 성능을 보였다. 이 결과를 통해서 1x1 filter로 non-linearity를 더하는 것도 도움이 되지만 3x3 filter로 공간적 맥락을 파악하는 것 역시 중요하다. (결국 직접 해보는 상황에서는 둘 다 테스트 해봐야 좋을 것 같다.)
데이터셋의 크기가 커질 수록 깊은 모델이 도움이 된다.
깊이가 깊고 필터의 크기가 작은 신경망( 3x3 conv layers )과 깊이가 얕고 필터의 크기가 큰 신경망( 5x5 conv layer )을 비교했을 때, 전자가 더 좋은 성능을 보이는 것을 확인했다.

학습 과정에서 데이터를 scale jittering 해주는 것은 성능 향상에 도움이 된다.
4.2 MULTI-SCALE EVALUATION

Test 할 때 scale jittering하여 평가한다.
Training과 test에 사용되는 이미지의 크기에 차이가 클 때 성능이 떨어진다. 따라서 Q 값을 S에 어느 정도 종속적인 범위로 설정을 한다. 먼저 S가 고정값일 때 로 설정한다. 반대로 학습에서 scale jittering을 적용한 경우 S는 사이의 값이기 때문에 으로 설정한다.
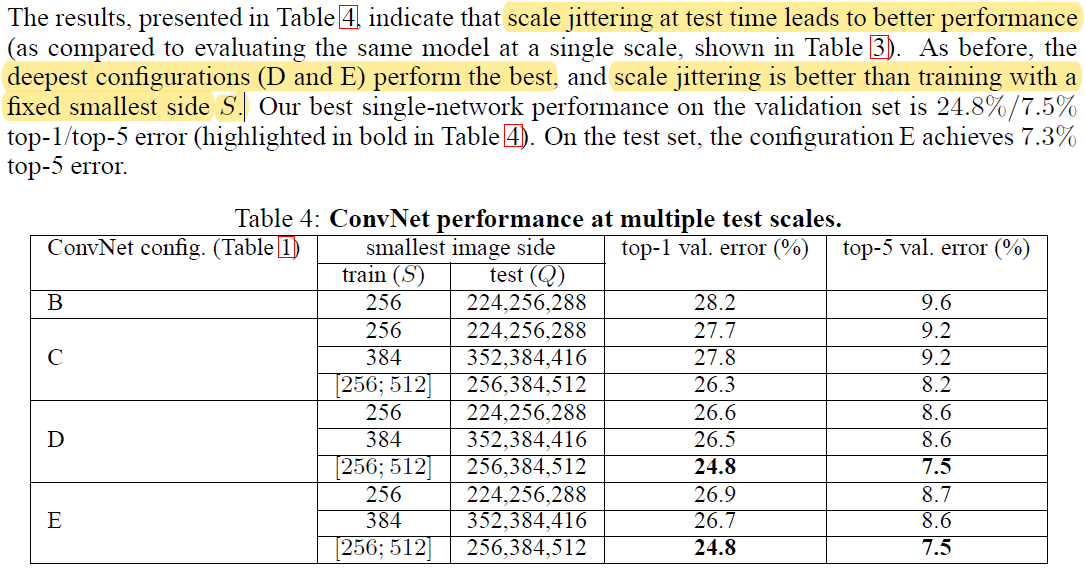
test 과정에서 scale jittering을 하는 것이 더 좋은 성능을 보였다.
깊이가 가장 깊은 model D와 E에서 좋은 성능을 보였으며, 각 모델 안에서도 학습 시에 scale jittering을 해서 학습한 버전에 더 좋은 성능을 보였다.
4.3 MULTI-CROP EVALUATION
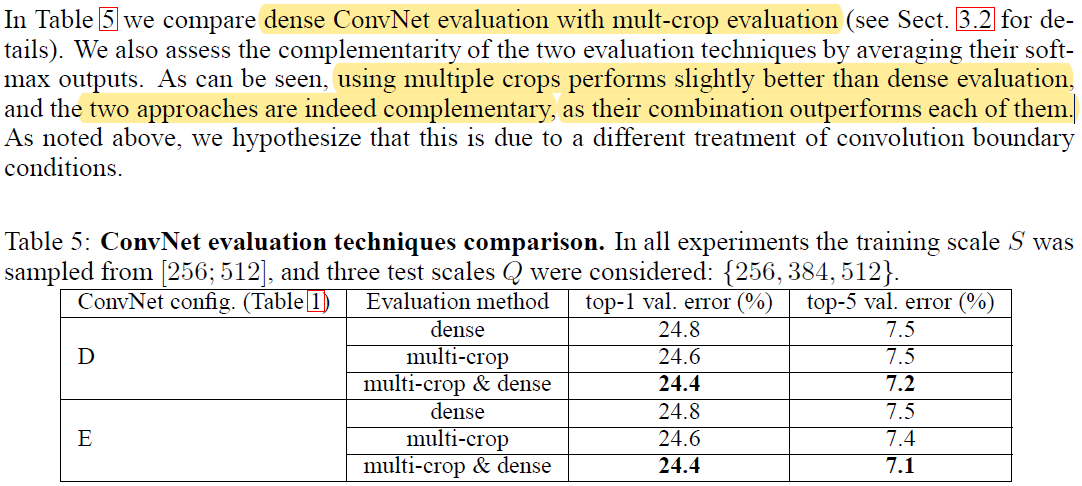
(완벽하게 이해 못했음) 평가 방법 중에 multi-crop evaluation과 dense evaluation이 있는 것 같은데 정확한 내용은 모르겠다.
이 두 방법을 비교했을 때 성능의 차이가 심하게 보이지는 않지만, 두 방법을 섞어서 사용했을 때는 더 좋은 효과를 보였다.
4.4 CONVNET FUSION


AlexNet, ZFNet, OverFeat과 결합해서 평균을 내서 사용하니까 성능이 향상됐다.
이후에 multi-scale training, multi-scale evaluation한 model D와 E를 multi-crop & dense evaluation했을 때 가장 좋은 성능을 냈다. (사전에 실험해서 나온 가장 좋은 조건을 다 넣어서 학습한 모델을 앙상블 한 내용이다.)
