들어가며
이 글은 Vision-Language-Action Models 논문을 읽으며, VLA가 왜 등장했고, 기존 Vision-Language Model과 무엇이 다른지를 정리하기 위해 작성되었습니다. 논문을 보며 메모한 내용들을 나열한 것이기에 다소 거친 면이 있으며 실제 논문과 같이 보면 더 따라가기 쉽습니다.
AI가 ‘보고 이해하는 것’을 넘어 실제 행동으로 연결되기 위해 어떤 구조가 필요한지를 중심으로 살펴보고자 하며 VLA 분야에 대해 처음 접하는 사람들을 위해 최대한 관련 개념들도 풀어서 작성했습니다.
부정확한 내용이 있다면 댓글로 비판해주시면 감사하겠습니다.
Paper Information
Title: Vision-Language-Action Models: Concepts, Progress, Applications and Challenges
Authors: Ranjan Sapkota, Yang Cao, Konstantinos I. Roumeliotis, Manoj Karkee
arXiv ID: 2505.04769
Topic: Vision-Language-Action Models, Robotics, Embodied AI, AI Agents
최근 Vision-Language Model (VLM)은 기계가 이미지와 텍스트를 함께 이해하게끔 하는 방향으로 기여를 했지만, 실제 세계에서 움직이고 상호작용해야 하는 로봇이나 embodied agent에게는 단순한 이해만으로는 부족했습니다.
예를 들어, 모델이 “빨간 사과”를 인식하고 “사과를 집어라”라는 문장을 이해하더라도, 그 사과를 향해 팔을 움직이고, 적절한 힘으로 잡고, 상황 변화에 따라 동작을 수정할 수 없다면 실제 행동을 수행하는 agent라고 보기는 어렵습니다.
이러한 문제의식에서 등장한 개념이 바로 Vision-Language-Action Model(VLA)입니다.
1. Introduction
VLA가 발전되기 전 robotics와 AI 분야의 발전 양상
각각의 시스템은 잘 작동하지만 정작 시스템을 통합하려니 안되고 새롭거나 예측할 수 없는 상황이 벌어지면 작동을 못함
1.1. 각자 따로 놀던 시대
- VIsion System : See and recognize images
- extensive labeled datasets
- cumbersome retraining for even slight shifts in environment or objectives
- Lacked any understanding of language
- Lacked the ability to convert visual insifgts into purposeful actions
- Language System : understand and generate text
- restricted to processing language without tcapability to perceive or reason about world
- Action System : control movement
- relying heavily on hand-crafted policies or reinforcement learning
- demaned painstaking engineering
- failed to generalize beyond narrowly scripted scenarios
1.2. 통합을 시도한 시대
- VLM (Vision-Language Model): Vision + Language
- inability to generate or execute coherent actions based on umltimodal input
Vision-Language, Language-Action, Vision-Action 처럼 두개의 요소에 대한 System에 대한 통합이 다였음
→ Fragmented Pipeline architecture에 그침 → brittle generalization and labor-intensive engineering efforts
이게 문제인 이유가 embodied AI같은 분야에서 인지와 이해 그리고 액션이 통합되어 작동하는 시스템이 없다보니 발전 측면에서 병목현상을 발생시킴
→ VLA의 필요성 대두됨
VLA라는 컨셉 자체는 이미 2021년 - 2022년에 대두된 주제로 Google DeepMind’s Robotic Transformer 2 (RT-2)와 같은 모습으로 연구되어온 주제로 연구되어왔음 그래서 VLA는 결론적으로 vision inputs, language comprehension, moto control capabilities를 통합하여 embodied agent의 상황과 복잡한 지시에 대한 이해 및 실행을 가능하게 함
[224] Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al., 2023. Rt-2: Vision-language-action models transfer web knowledge to robotic control, in: Conference on Robot Learning, PMLR. pp. 2165–2183.
1.3. Early VLA Approaches
- Extending vision-language models to include action tokens — numerical or symbolic representations of robot motor commands
- 모델이 서로 대응되어 묶여 있는 시각 데이터, 언어 데이터, 궤적 데이터로부터 학습할 수 있게 했다.
- 학습 과정에서 못본 객체에 대한 일반화 (Generalize to unseen objects),
- 새로운 명령어에 대한 변환 (interpret novel language commands),
- 비구조화된 환경에서의 다중 단계 추론이 가능하게 됨 (perform multi-step reasoning in unstructured environments)
2. Concepts of Vision-Language-Action Models
What constitutes a VLA model, its historical evolution, multimodal integration mechanisms, and language-based tokenization and encoding strategies
VLA =
- Vision Encoders (e.g. CNNs, ViTs) +
- Language models (e.g. LLMs, Transformers) +
- Policy modules or planners to achieve task-conditioned control
⇒ multimodal fusion techniques를 활용한 결합 (e.g. cross-attention, concatenated embeddings, token unification)
VLA는 traditional visuomotor pipelines와는 다르게 sematic grounding , context-aware reasoning, affordance detection, temporal planning 이 가능했음
❓ traditional visuomotor pipeline
: 시각 인식과 행동 제어가 모듈별로 나뉜 로봇 제어 방식
이미지 입력 → 물체 인식/위치 추정 → 계획 수립 → 제어 명령 생성 → 로봇 실행
2.1. 발전 양상 (Evolution and Timeline)
2.1.1. Foundational Integration (2022-2023)
-
basic visuomotor coordination을 modal fusion architectures를 통해 Early VLA를 구현함
- CLIP embedding을 motion primitives와 함께 결합
[141] Reed, S., Zolna, K., Parisotto, E., Colmenarejo, S.G., Novikov, A., Barth-Maron, G., Gimenez, M., Sulsky, Y., Kay, J., Springenberg, J.T., et al., 2022. A generalist agent. arXiv preprint arXiv:2205.06175 .
→ 604개의 다양한 작업에서 범용적으로 작동할 수 있는 능력을 보였다. (Generalist Capabilities)
→ Transformer-based planner를 통해 시간적 추론(temporal reasoning)능력을 보여줌
Temperal reasoning : 작업을 시간 순서에 따라 이해하고, 여러 행동을 단계적으로 연결하는 능력
-
2023년에는 visual chain-of-though reasoning을 구현하고
visual chain-of-though reasoning: 이미지/장면을 보고, 바로 행동하지 않고, 중간 추론 단계를 거쳐 행동을 결정하는 능력
→ vision을 기반으로 한 단계적 reasoning
[224] Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al., 2023. Rt-2: Vision-language-action models transfer web knowledge to robotic control, in: Conference on Robot Learning, PMLR. pp. 2165–2183.
-
stochastic action prediction을 diffusion process를 통해 발전시켰다
stochastic action prediction: 행동을 하나의 정답처럼 고정해서 예측하는 것이 아니라, 가능한 여러 행동 분포에서 샘플링하거나 생성하는 방식
diffusion process: 처음에는 노이즈에 가까운 상태에서 시작해서, 점점 의미 있는 결과로 정제해 나가는 방식
이상한 움직임 후보 (무작위 행동 궤적)
→ 장애물 피하기 → 손목 방향 조정
→ 컵을 안정적으로 잡는 경로 (자연스러운 로봇 동작 궤적)
[34] Chi, C., Xu, Z., Feng, S., Cousineau, E., Du, Y., Burchfiel, B., Tedrake, R., Song, S., 2023. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research , 02783649241273668.
- 최종적으로 low-level control을 해결했지만, Lacked compositional reasoning 문제가 있었음
❓
lacked compositional reasoning개별 개념은 알아도 그것들을 조합해 새로운 복합 작업을 해결하지 못하는 문제
→ 실제 로봇 환경의 명령과 상황이 대부분 조합적이고 매번 조금씩 다르다.
3.1.2. Specialization and Embodied Reasoning (2024)
Second-generation VLA는 domain-specific inductive biases를 활용했다.
→ 범용 모델 하나로 다 해결하기 보다는, 특정 도메인에서 잘 작동하도록 구조적 힌트(inductive bias)를 넣기 시작했다
- Enhanced few-shot adaptation through retrieval-augmented traing
Inductive Bia: “로봇 작업은 과거의 유사한 조작 경험이 새 작업에 도움이 된다”retrieval-augmented는 모델이 모든 것을 내부 파라미터에 기억하는 대신, 비슷한 예시나 지식을 외부 데이터베이스에서 찾아와 참고한다
- optmized navigation via 3D scene-graph integration
Inductive Bia: “내비게이션에서는 픽셀 자체보다 “어디에 무엇이 있고, 어떤 공간이 연결되어 있는가”가 중요하다”공간을 노드와 관계(edge)로 표현
- introduced reversible architectures for memory efficency
Inductive Bia: “긴 시간 흐름과 여러 모달리티를 처리하려면 메모리 효율성이 중요하다”중간 계산값을 전부 저장하지 않고도 역방향 계산을 할 수 있게 만든 구조
→ backpropagation시 메모리 사용량 감소 → 더 큰 모델이나 긴 sequence 처리 가능
- addressed partial observability with physics-informed attention
- improved disentanglement
“빨간 컵”을 볼 때
→ 빨간색 = color, 컵 = object category, 잡을 수 있음 = affordance, 테이블 위 = spatial relation
→ 하나의 물체를 개념에 따라 분리해서 다각화 이해 (뭉뚱그려 이해하지 않는다) - extended applications to autonomous driving via multi-modal sensor fusion
⇒ required new benchmarking methodologies (기존 평가 방식으로는 VLA의 성능을 제대로 평가할 수 없게 되었다)
2024년 VLA는 단순히 vision-language-action을 연결하는 수준을 넘어서, 로봇 조작, 내비게이션, 물리 환경, 자율주행 같은 특정 도메인의 구조적 지식을 모델에 반영하면서 더 잘 일반화하고 더 안정적으로 행동하도록 발전
3.1.3. Generalization and Safety-Critical Deployment (2025)
2025년부터는 robustness와 human alignment를 중요시하고 있음
- human alignment는 모델이 명령을 수행하는 것을 넘어서, 사람이 의도한 바와 안전 기준에 맞게 행동하도록 조정되는 것
- Integrated Formal verification for risk-aware decisions
- Demostrate Whole-body control을 hierachical VLA로 구현
[42] Ding, P., Ma, J., Tong, X., Zou, B., Luo, X., Fan, Y., Wang, T., Lu, H., Mo, P., Liu, J., et al., 2025b. Humanoid-vla: Towards universal humanoid control with visual integration. arXiv preprint arXiv:2502.14795 .
Effect
- embedded 개발 환경에서 계산 효율성을 최적화하기도 함
- Affordance chaing과 sim-to-real transfer learning과 같은 paradigm이 제시되면서 cross-embodiment challenge를 해결함
- affordance는 어떤 물체가 제공하는 행동 가능성
- affordance chaining은 복잡한 행동을 “무엇을 어떻게 사용할 수 있는가”의 연쇄로 나누어 수행하는 방법
e.g. 문을 열고 방에 들어가라 : 문손잡이를 찾는다 → 손잡이를 잡는다 → 돌린다 → 문을 민다 → 열린 공간으로 이동한다
- sim-to-real transfer learning은 시뮬레이션에서 학습한 능력을 실제 로봇 환경으로 옮기는 학습 방식
- cross-embodiment challenge는 한 로봇에서 배운 능력을 다른 로봇에 옮기기 어렵다는 문제
- Natural Language Grounding을 통해 VLA와 Human-in-the-loop interfaces를 연결
- human-in-the-loop는 사람이 시스템의 판단이나 실행 과정에 중간에 개입하는 구조
2.2. 멀티모달은 어떻게 하나가 되었나
이전에 언급되었듯 Vision, Language, Action을 하나의 Achitecture로 만드려는 시도는 있어왔음
e.g. Traditional Robotics → Perception + Natural Language Process + Control = Discrete Modules linked with manual defined interfaces and data transofmation
이를 극복하기 위해 Large-scale Pretrained Encoders와 Transfromer Based Architectures를 통해 end-to-end module을 구현함
→ 이제 모델이 interpret visual observations and linguistic instructions within the same computational space, allowing flexible, context-aware reasoning할 수 있게됨 e.g. CLIPort, VIMA
최근에는 이를 더 발전시켜 temporal, spatial grounding을 활용해 더 발전해왔음 e.g. RT-2, Octo
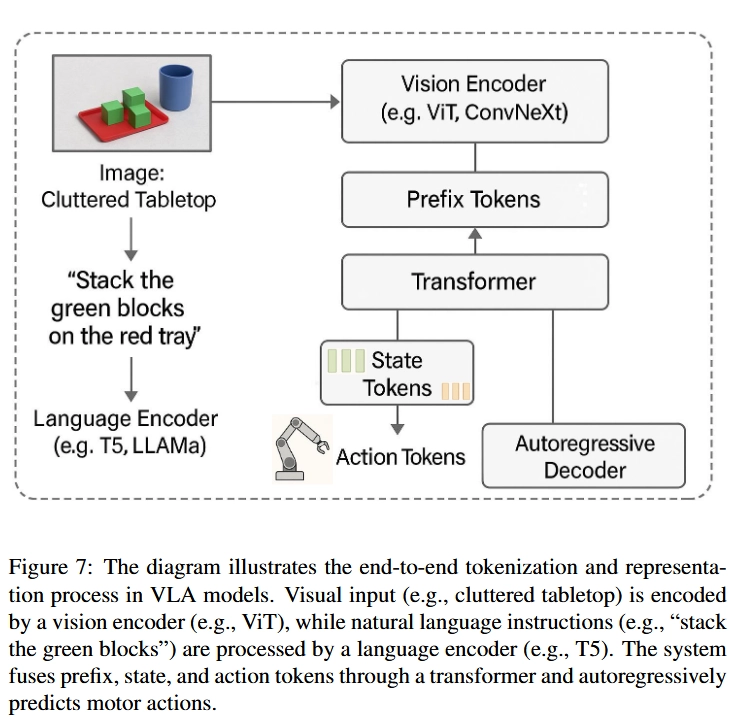
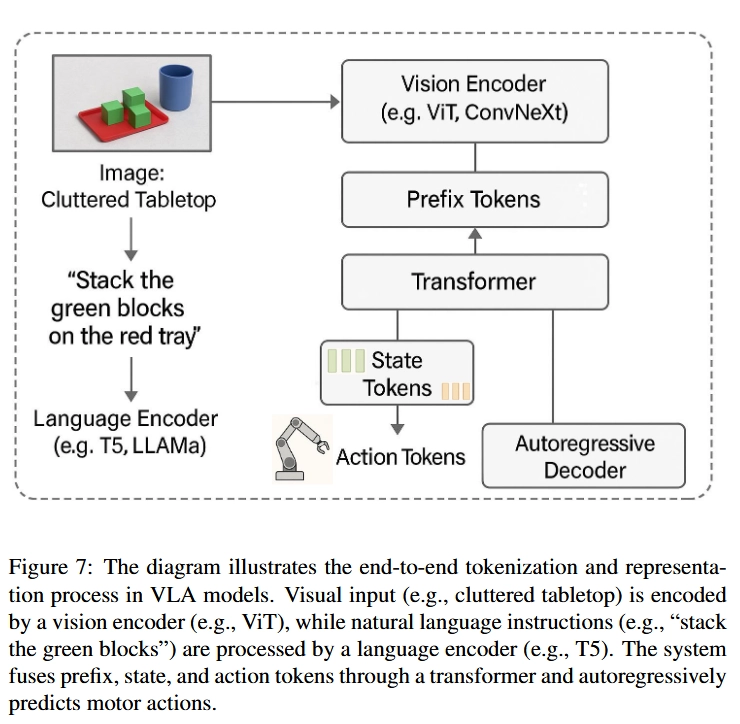
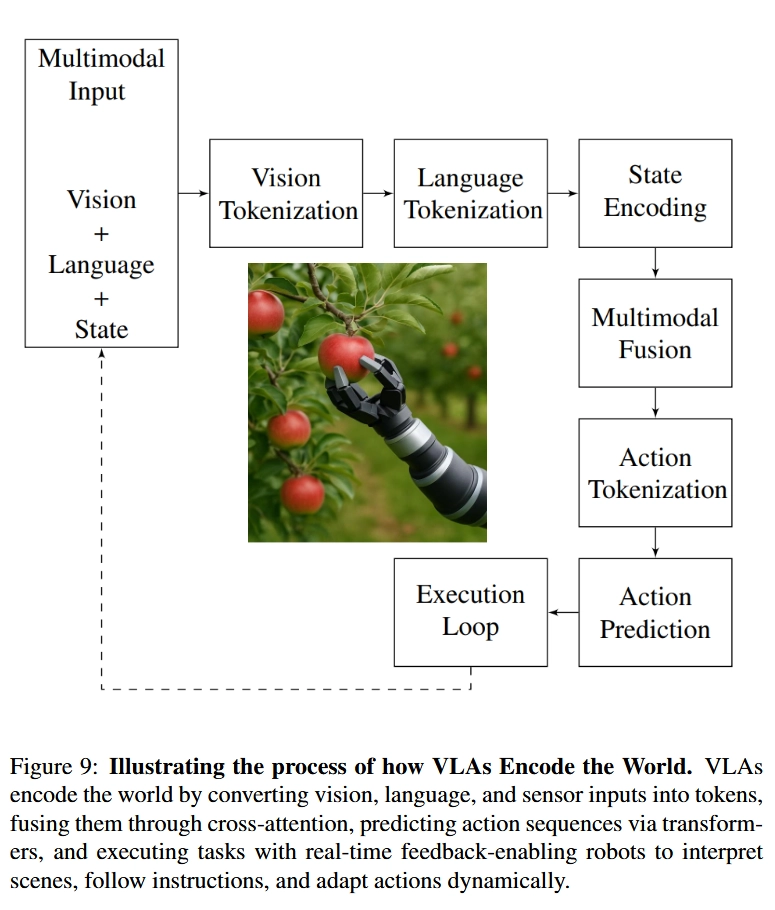
2.3. VLA는 어떻게 세상을 이해하는가 (Tokenization and Representation)
위와 같이 VLA가 발전할 수 있었던 이유는 token-based representation framework 덕분이었음
→ semantic reasoning (What needs to be done) 뿐만 아니라 Control policy execution (How to do it)을 learnable하며 compositional 한 방식으로 구현함
2.3.1. Prefix Tokens — Encoding Context and Instruction
Contextual Backbone of VLA Models
- These tokens encode the environmental scene (via images or video) and the accompanying natural language instruction into compact embeddings that prime the model’s internal representations
2.3.2. State Tokens — Embedding the Robot’s Configuration
be aware of their internal physical state
- State tokens, which encode real-time information about the agent’s configuration—joint positions, force-torque readings, gripper status, end-effector pose, and even the locations of nearby objects
- state tokens encapsulate spatial features
- The transformer model integrates this state representation with environmental and instructional context to generate navigation actions that dynamically adapt to changing surroundings.
2.3.3. Action Tokens — Autogressive Control Generation
autoregressively generated by the model to represent the next step in motor control
→ Each token corresponds to a low-level control signal, such as joint angle updates, torque values, wheel velocities, or high-level movement primitives

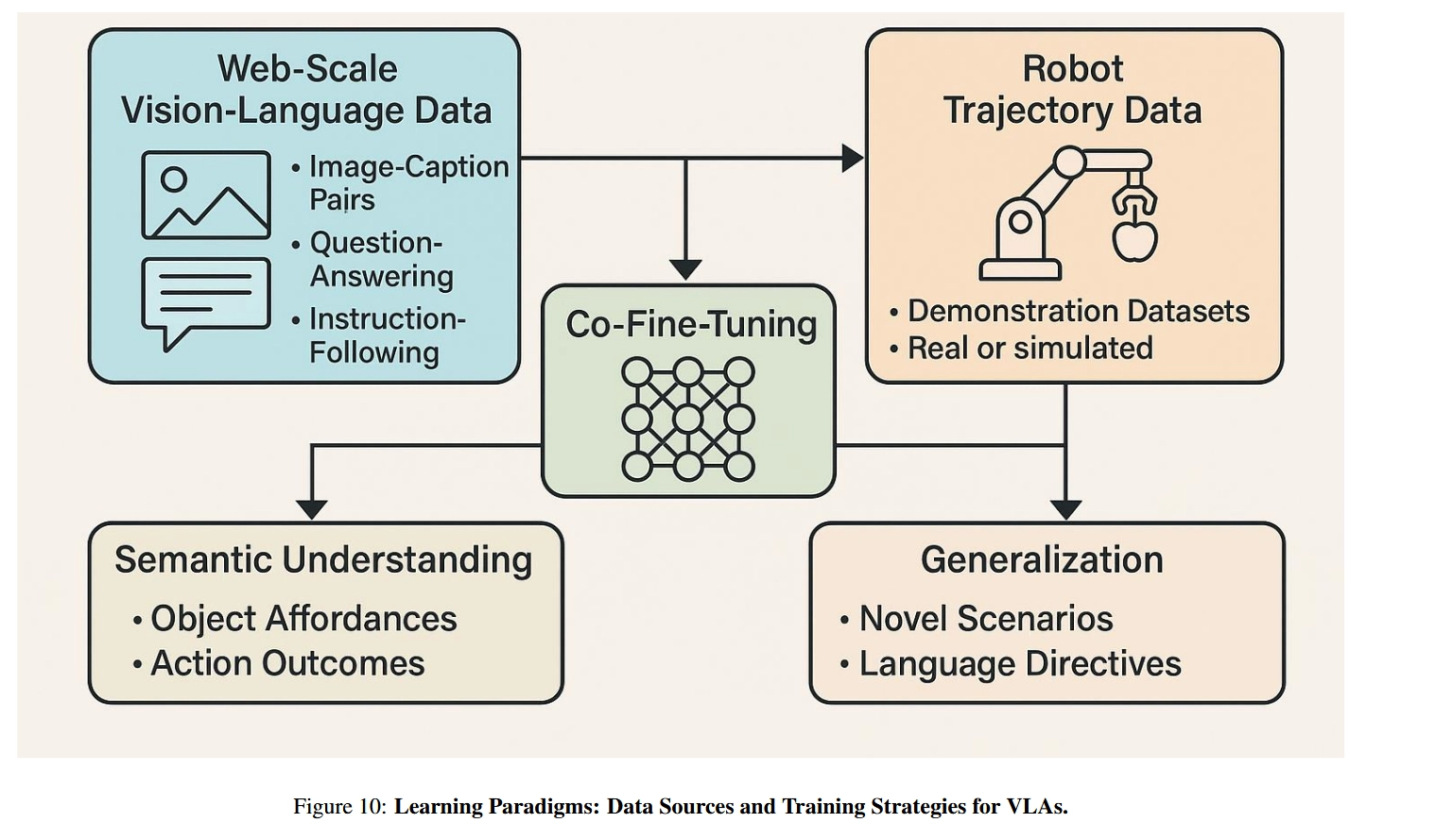
- Training VLA model을 위해서는 hybrid learning paradigm 이 요구됨
- Web-based semantic knowledge
- task-grounded information from robotics datasets
- 그래서 어떤 데이터 소스를 사용해야하는가?
-
Large-scale internet-derived corpora form the backbone of the model’s semantic prior.
e.g. Image-caption pairs, instruction-following datasets, visual questioning-answering corpora
- Vision encoder와 language encoder의 pretaining을 가능하게 한다
- contrastive나 masked modeling objectives를 사용하는데 (e.g. CLIP-style contrastive learning or language modeling losses) 이는 vision modalities와 language modalities를 shared embedding space에 놓기 위함이다.
- semantic understanding alone is insufficient for physical task execution
-
Grounding the model in embodied experience
- Robot trajectory datasets—collected either from realworld robots or high-fidelity simulators
- to teach the model how language and perception translate into action
- e.g. RoboNet [37], BridgeData [50], and RT-X
- Robot trajectory datasets—collected either from realworld robots or high-fidelity simulators
- 최근 동향에서는 multistage or multitask training strategies를 활용하고 있다고 한다
-
pretrained on vision-language datasets
1. using masked language modeling
- fine-tuned on ronot demostration data using token level autogressive loss
2. using curriculum learning
- simpler tasks (e.g. object pushing)→ more complex tasks (e.g.multistep manipulation)
3. Domain Adaptation으로 접근하기도 함
- Open-VLA or sim-to-real transfer to bridge gap between synthetic and real-work distributionsBy unifying semantic priors with task execution data, these learning paradigms allow VLA models to generalize across tasks, domains, and embodiments—forming the backbone of scalable, instructionfollowing agents capable of robust real-world operation.
-
-
2.5. Adaptive Control and Real-Time Execution
- This training paradigm not only helps
-
the model understand object affordances (e.g., apples can be grasped) and action outcomes (e.g., lifting requires force and trajectory)
-
promotes generalization to novel scenarios
e.g. Google DepMind’s RT-2 (Robot Transformer 2)
Action generation as a form of text generation where each action token corresponds to a discrete command in a robot’s control space
-
Another strength of VLAs lies in their ability to perform adaptive control, using real-time feedback from sensors to adjust behavior on the fly
[153] Serpiva, V., Lykov, A., Myshlyaev, A., Khan, M.H., Abdulkarim, A.A., Sautenkov, O., Tsetserukou, D., 2025. Racevla: Vla-based racing drone navigation with human-like behaviour. arXiv preprint arXiv:2503.02572
execution이 진행되는 동안 state token이 실시간으로 업데이트되며 (e.g. seonsor inputs, joint feedback) action plan을 수정할 수있게 된다
→ human-like adaptability and core advantage of VLA systems over pipeline-based robots
3. Notes
이번 논문을 읽고 정리한 VLA의 핵심은 다음과 같습니다.
VLA는 시각 정보와 언어 지시를 실제 행동으로 변환하는 embodied AI 모델
기존의 Vision-Language Model이 “무엇이 보이고, 그것이 무엇을 의미하는가”를 다뤘다면, VLA는 한 단계 더 나아가 “그렇다면 지금 무엇을 해야 하는가”를 다룹니다.
이 점에서 VLA는 로봇, 자율주행, embodied agent, physical AI와 강하게 연결됩니다.
특히 제가 관심 있는 animal behavior analysis나 embodied interaction 관점에서도 VLA는 단순히 행동을 분류하는 모델을 넘어 환경을 보고, 행동 맥락을 이해하고, 다음 행동을 예측하거나 상호작용하는 agent 구조로 확장될 가능성이 있다고 느꼈습니다.
오늘은 Vision-Language-Action Model의 Concept 파트를 중심으로 정리해보았습니다. 부정확한 내용이나 더 궁금한 점이 있다면 댓글로 남겨주시면 감사하겠습니다.
