들어가며
이 글은 딥러닝 역사에서 전환점으로 평가받는 AlexNet 논문을 읽으며,
이 모델이 왜 “작동했는가”를 정리하기 위해 작성되었습니다.성능 비교가 아니라, 당시 기술적 제약 속에서 어떤 선택들이 문제를 해결했는지를 중심으로 살펴보고자 합니다. 또한 이 글은 Standford University의 CS231n의 일부를 참고로 하였습니다. 따라서 Computer Vision에 대해 더 궁금하신 독자께서는 링크를 참고해주세요. link
Paper Information
Title: ImageNet Classification with Deep Convolutional Neural Networks
Authors: Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton
Journal: Advances in Neural Information Processing Systems (NeurIPS 2012) link
arXiv ID: NFI
Ⅰ. Introduction
“To recognize the real world, how much capacity does a model really need?”
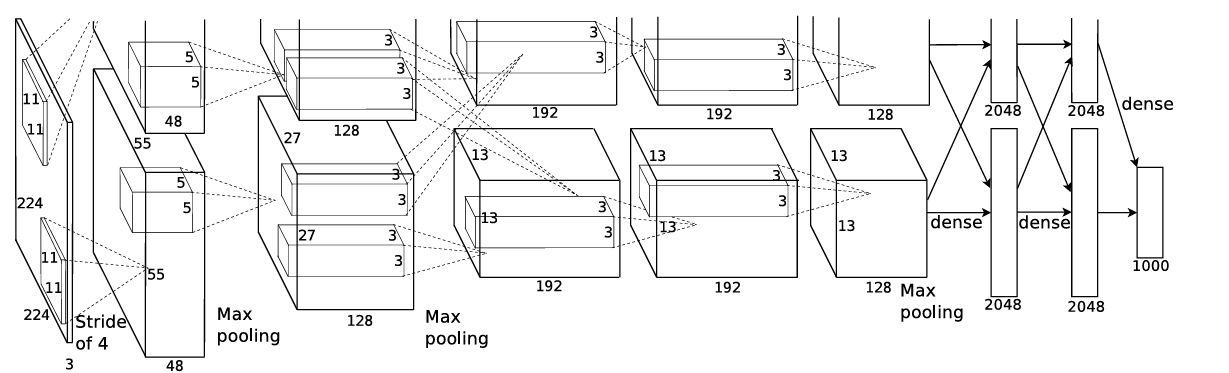
Ⅰ.1. 데이터 규모와 문제 복잡성
이 논문에 대한 이야기를 하기 전, 먼저 이러한 모델이 나올 수 있었고 효과가 있었던 배경에 대해 설명하려 합니다.
디지털 사진이 막 도입된 시점 (1960s), 객체 탐지 (Object Recognition)은 상당히 어려운 분야였습니다. 대상이 어디있는가? 어디까지 대상으로 할 것인가?에 대한 Vision Representation에 대한 고전적인 질문과 함께 (Stages of Visual Representation, David Marr, 1970s) 아직은 디지털 데이터에 대해 정리하고 확립하는 과정이었습니다.
그 과정에서 나온 데이터 셋은 NORB와 Caltech-101/256,
CIFAR-10/100 등이 있습니다. 이들은 당시 기준으로는 표준적이고 잘 만들어진 데이터셋이지만 데이터의 규모는 객체 인식 연구를 하기에는 충분하지 않은 규모 (수만 장)였습니다.
물론 간단한 인식은 labrl-preserving transformation릏 통한 데이터 증강을 활용하여 이 규모에서도 꽤나 잘 이루어졌지만 문제는 가려짐, 배경 변화, 시점 변화 같은 상황의 경우 단순한 증강으로는 한계점이 있어 더 많은 데이터가 필요해졌습니다.
이때 등장한 것이 바로 ImageNet이었습니다. ImageNet은 2009년 대규모 객체 인식을 위해 등장한 이미지 데이터셋으로. 한 객체 범주 (synset) 당 평균 1000개의 이미지라는 대규모의 데이터셋입니다. 이로써 객체 인식을 위한 데이터의 규모는 갖추어졌지만, 많은 데이터가 필요해짐에 따라 또한 모델의 용량도 이에 맞춰 더 커져야 했습니다.
Ⅰ.2. 모델 용량(Capacity)의 필요성
데이터의 규모가 커진 만큼 데이터의 복잡도 (e.g. 시점 변화, 조명 변화, 배경 변화...)도 느러 연구진은 CNN을 선택하게 됩니다. CNN의 특성은 바로 다음 섹션에서 설명합니다.
이러한 배경에서 연구진들은 다음과 같은 선택을 통해 모델의 용량을 키워 AlexNet의 성능을 끌어올립니다.
- 약 6천만개의 파라미터
- 5개의 Convolution Layer와 3개의 Fully Connected Layer
- 상대적으로 큰 Neural Network
Ⅱ. Key Design Choices
Architecture is not just structure; it is prior knowledge.
Ⅱ.1. Convolution Neural Network (CNN)
CNN은 기존의 Neural Network에 기반하였기에 학습 가능한 weights와 bias를 가진 neuron을 가지고 있습니다. 하지만 가장 큰 변화점은 입력값이 이미지라는 가정하에 다양한 이미지의 특성을 구조에 녹일 수 있다는 점입니다.
다시 말해 "이미지의 내부에는 인접한 픽셀 간의 강한 상관관계가 있다 (Locality)"라는 가정과 "이미지의 통계적 특성은 픽셀의 위치에 따라 크게 변하지 않는다 (Stationarity)"라는 가정을 전제하에 두고 있습니다.
그렇기에 기존의 Nerual Network와는 다르게 더 적은 connection와 parameter를 가지고 더 쉽게 학습 가능하게 됩니다. 물론 이때 약간의 성능하락은 존재하지만 여전히 매력적인 선택지입니다.
하지만 그럼 왜 진작 사용하지 않았는가? 라고 묻는다면 이 모델을 실행할 하드웨어 자원이 부족했기 때문입니다. 하지만 연구진은 당시에 개발된 GPU (GTX 580 3GB GPU)를 CNN에 맞게 적용하여 사용해서 큰 CNN 모델에 대한 학습을 가능하게 합니다. 이를 연구진은 아래와 같이 말합니다.
Luckily, current GPUs, paired with a highly-optimized implementation of 2D convolution, are powerful enough to facilitate the training of interestingly-large CNNs, and recent datasets such as ImageNet contain enough labeled examples to train such models without severe overfitting.
하지만 연구진은 Convolution layer만 사용하지 않고 기존의 Fully connected network 역시 사용합니다. (It contains eight learned layers — five convolutional and three fully-connected.)
Fully-connected layer란?
한 레이어의 모든 뉴런이 바로 이전 레이어의 모든 뉴런과 연결되어 있는 레이어를 말합니다.
1. convolutional layer
- 국소 영역 (local receptive field)만 봄
- 가중치 공유 (weight sharing)
- 공간 구조 (spatial structure)를 유지
- fully-connected layer
- 공간 구조를 더 이상 고려하지 않음
- 입력 전체를 하나의 벡터로 보고
- 모든 입력을 종합해서 판단
Ⅱ.2. Rectified Linear Units (ReLUs) Nonlinearity
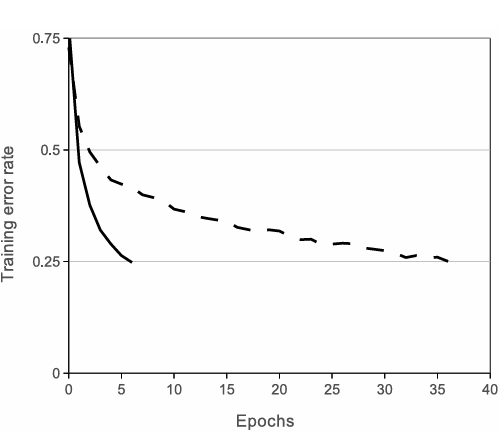
기존의 , sigmoid 계열의 활성화 함수는 깊은 네트워크 (입력값의 절댓값이 커질 수록) gradient saturation 문제를 유발하게 됩니다. (e.g. ) 이런 문제를 해결하고자 연구진은 ReLU를 활성화 함수로 지정하여 이러한 saturation 문제를 해결합니다.
Saturation은 왜 문제가 되는가?
Fig. 1에서 나타나듯이 Epoch에 따라 Training Error Rate를 보면 ReLU가 tanh에 비해 훨씬 빠른 학습 속도를 보여줍니다. 이 이유는 입력값의 절댓값이 커질 수록 출력이 거의 일정해지고 그렇기에 gradient가 매우 작아지며 학습이 느려지게 되기 때문입니다.
이 ReLU를 통해 학습 속도는 대폭 향상되고, 큰 모델에서도 non-saturating한 활성 함수를 사용하기에 실험을 반복적으로 수행 가능하며, 이러한 깊은 CNN 학습이 현실적인 시간 내에 완료되도록 합니다.
Ⅱ.3. GPU parallelization
연구진이 사용한 GTX 580 GPU는 3GB의 메모리 크기를 가지고 있기에 1,200,000개의 훈련 데이터를 학습하기에 적합한 Network를 돌리기에는 한 GPU 가지고는 모자랐습니다. 그렇기에 연구진의 선택은 두개의 GPU를 통해 병렬 연산을 진행하는 방식을 선택했습니다.
단순히 Kernel이나 Neuron을 절반으로 나누어 각각 넣는게 아니라 GPU간의 communication을 특정 레이어에서만 전체 연결을 허용합니다. 예를 들어 3번 레이어의 Kernel은 2번 레이어의 모든 Kernel로부터 정보를 받습니다. (이는 두 GPU에서의 값을 모두 받는다는 것을 의미합니다. Communication 발생)
하지만 4번 레이어의 Kernel의 경우 동일 GPU에 있는 3번 레이어의 데이터만 입력값으로 받게 됩니다. 이렇게 함으로써 개별 GPU가 소화할 수 있는 적정한 연산량 안에서의 communication 양을 세밀하게 조절할 수 있게 해줍니다.
이러한 구조는 Columnar CNN과 상당히 유사하지만 AlexNet은 column이 독립적이지 않다라는 차이점이 있습니다.
정리하자면 이러한 GPU 병렬화는 개별 GPU로는 수행하지 못하는 양의 연산을 수행하고, 단일 Convolution layer에서 개별 GPU로만 구현했을 때보다 약간 빠르게 수행합니다.
Ⅱ.4. Reducing Overfitting
물론 모델이 커짐에 따라 너무나도 학습 데이터를 잘 학습한 나머지 발생하는 과적합은 필연적이게 됩니다. 이러한 과적합을 연구진은 계속해서 언급했고, 아래의 두가지 전략을 통해 과적합을 줄입니다.
Ⅱ.4.1. Data Augmentation
AlexNet에서는 두가지 방법으로 데이터 증강을 진행합니다. 첫번째는 이미지를 임의로 224 by 224 patch로 잘라내고 좌우 반전을 하는 방식으로 증강을 이루는 것입니다. 이러한 데이터 증강은 훈련 데이터셋의 사이즈를 키우는 방식으로 과적합을 줄여줍니다.
두번째 방법으로는 학습 이미지의 RGB 채널의 강도를 PCA (Primary Component Analysis)를 통해 도출된 principal component를 곱하는 방식으로 조정을 해줍니다. 또한 RGB pixel 값들의 eigenvector와 eigenvalue를 활용해서 단순히 색을 무작위로 변화하는 방식으로 증강한 것이 아니라 현실적인 조명 변화를 흉내내며 증강하게 됩니다.
그래서 Generating image translations and horizontal reflec
tions와 Altering the intensities of the RGB channels in
training images 두가지 데이터 증강 전략을 통해 과적합을 방지할 수 있었다고 합니다.
Ⅱ.4.2. Dropout
당시 비교적 최근에 소개된 dropout 전략이 AlexNet에 적용된 두번째 과적합 방지 전략입니다. Dropout 전략은 각각의 히든 뉴런의 출력값에 대해서 일정한 확률 (AlexNet에서는 0.5)로 0이 되게끔 설정하는 전략입니다. 이러한 방식으로 누락된 ("Dropped out") 뉴런들은 다음 레이어에 영향을 미치지 않아 back propagation에도 참여하지 못하게 됩니다.
이렇게 함으로써 학습을 진행할 때마다 구조가 조금씩 다른 네트워크를 학습하는 동시에 weight 값은 공유를 하기에 샘플마다 다른 개별 특징에 초점이 맞춰지는게 아니라 더 일반적인 공통된 특징에 더 집중되어 학습을 진행하게 됩니다. 이렇게 진행함으로써 과적합을 방지할 수 있게 됩니다.
Ⅲ. Limitations & Conclusion
결론적으로 AlexNet은 당시의 GPU 발전과 함께 대규모의 깊은 CNN을 구현했고 그 해 2012년 Large Scale Visual Recognition Challenge (LSVRC)에서 top-5 test error rate로 15.3%로 두번째로 낮았던 26.2%보다 훨씬 뛰어난 성능을 보였습니다.
물론 실험을 단순하게 하기 위해 Unsupervised pre-traing을 사용하지 않았으므로 성능을 더 끌어올릴 수 있는 여지가 있다는 점, 인간의 시각 시스템에 비해서는 아직 너무나도 작은 모델이라는 연구진의 자기 평가가 있었지만 그럼에도 불구하고 깊은 CNN 하나만으로 순수 지도학습에서 당시 최고 성능을 달성했다는 점에서 의미있는 시도였습니다.
오늘은 Computer Vision에서 굵직한 마일 스톤 중 하나인 AlexNet에 대한 논문을 읽어보았습니다. 이번에도 긴 글 읽어주셔서 감사합니다.
의견이나 질문이 있다면 댓글로 남겨주시기 바랍니다.
