5월 되기 전에 쭉 정리를 해야지
(작성중...)
GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis(NIPS2020)
본 논문도 역시나 2D 기반 Generator들은 고해상도인 양질의 이미지를 만들어내긴 하지만 real world인 3D에 대한 이해는 부족하다고 하며 Pose와 Viewpoint에 대한 정보를 아직 2D가 잘 수행해내기는 어렵다고 한다. 그리고 이에 대한 대안으로 자연스레 Rendering 기반의 NeRF를 언급하며 본 모델을 소개한다.
방법론을 간단히 설명하면 NeRF로 Image를 생성한 후 얘를 Discriminator에 태우는 구조이다.
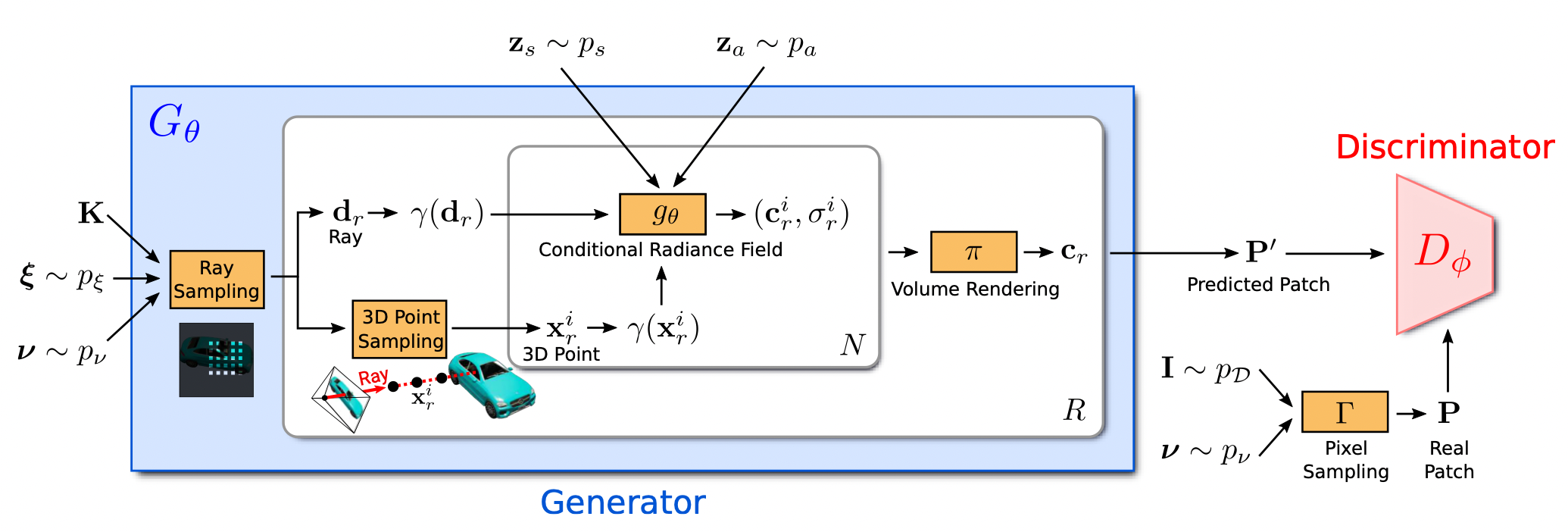
하지만 단순히 NeRF를 Unconditional Generator로 보기에는 여러가지 제약 조건들이 많다. 이를 하나씩 설명하면 아마 본 논문 요약이 끝날 것 같다.
- NeRF의 경우 Training이 Viewpoint와 관련 정보를 요구하는데 이 문제를 어떻게 해결했는가.
본 논문에서는 우선 가상의 공간을 가정한 후 Extrinsic Matrix의 경우에는 Random Sampling으로 진행했다고 한다. 그렇다면 Loss는???이라는 의문이 생기지만 위에서 말했듯이 이 모델은 GAN기반이다. 즉, pixel 단위 loss가 아니라 Discriminator 기반으로 loss를 주기 때문에 단순히 Render 기반의 학습을 진행하고 그 과정에서 모델이 3D에 대한 정보를 얻는다 정도로 이해하면 될 것같다. Intrinsic은 데이터셋에 따라 주어지는 것 같고, 이미지에 Center기반으로 간다고 하니 아마 이는 기본 세팅하는 것 같다.
- NeRF는 Inference에도 시간이 엄청 오래걸리는데 이 문제를 어떻게 해결했는가.
G -> D로 넘어가는 주기에 대해서 한 이미지의 모든 픽셀로 진행하지 않고, 일정 크기의 패치를 기반으로 진행된다. 단 여기서 패치가 어떻게 생겼는가는 파라미터에 따라 달라지는데 중심에 대한 좌표와 패치를 구성하는 픽셀들 사이의 간격을 파라미터로 주고 이 역시도 uniform distribution 기반으로 sampling하였다고 한다.
- NeRF는 Object 단위로만 Render가 가능한데 이게 Generator인가.
Vanilla-NeRF를 보면 Object-Dependent한 Training 과정을 거친다. Generator가 한 Object만 줄창 뽑아내면 그것도 나름 문제가 있을 것이다. 여기서는 SRN에서 쓰고 NeRF-W에서 썼던 latent code(appearnce and shape)를 MLP에 conditional하게 삽입해서 해당 latent code에 따라 다른 object가 나오도록 학습을 시켰다고 한다
후기
아직 견식이 짧아서 그럴지는 모르겠지만 아마 이 논문부터 Generative Radiance Field를 제안하면서 NeRF 기반 모델들의 task를 Novel View Synthesis에서 Generator로 확장하지 않았나하는 생각이 든 논문이다.
Training Spec
Resolution: 512X512
GPU:
pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis(CVPR2021)
이 논문은 Periodic(SIREN)과 Implicit Function(NeRF)를 도입해서 Volume Rendering 형식의 Generator를 제안한 논문이다.
기존에 존재하는 GAN들도 이미 좋은 성능을 보여주고는 있지만 여전히 2D Domain에서 놀고 있기도 하고 3D consistency에 대한 데이터셋도 부족하기 때문에 3D에 대한 정보를 모델에게 학습시키는 것은 어려운 일이다. 그래서 본 논문은 기존에 확장되어가는 2D Generator가 아니라 View에 따른 Rendering 형식으로 Generator를 제안해 3D에 대한 정보를 GAN에게 익히려고 하고 있다. 그리고 여기서 Render 형식으로는 잘 나가는 Implicit Representation을 활용하고 또 Implicit Representation에 대해서 잘 먹히는 Activation Function인 SIREN을 활용하고 있다.
구조는 아래와 같다.
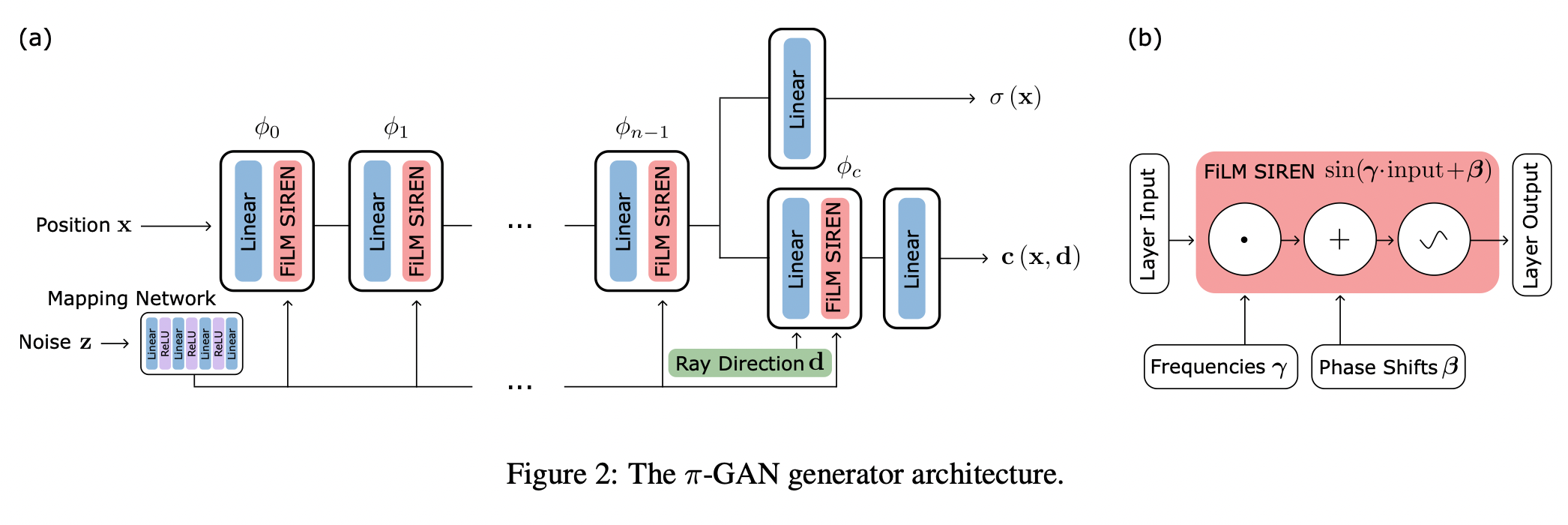
우선 Generator에 대해서는 기존의 StyleGAN에서 사용하는 Mapping Network와 NeRF 기반의 5D function이 조합된 그런 기묘한 모양이다. naive하게 해석하면 이미지 자체는 NeRF의 형식으로 Volume Rendering 기반으로 Ray Sampling을 진행한 후, 각 Sampling point에 대해서 위 Generator를 하나씩 태우는 꼴이고 그 과정에서 동일 이미지에 대해서는 noise 는 동일한 형식이다. 의 역할은 기존 StyleGAN에서 Adaptive Instance Normalization에 들어가는 것과 유사하지만 다만 좀 차이가 있다면 기존에는 mean and variance였다면 여기서는 frequency and bias형식으로 들어가게 된다.
학습하는 방식은 PGGAN과 유사하게 진행되었다고 하며, 기존에 PGGAN에서는 Generator의 경우에는 모델의 크기가 커졌지만 여기서는 Sampling resolution을 늘리는 형식으로 진행되었다고 한다.
실험 비교 결과는 아마 맨 마지막 논문인 VolumeGAN 할 때 다같이 할 것 같다.
후기
결국 이미지가 아니라 표현을 학습한다라는 느낌으로 이미지 생성 방식을 3D Implicit Representation -> Rendering 3D적인 정보가 잘 입혀지는 것 같긴 하다. 솔직히 이게 왜 됨? 이라는 의문점이 크긴 컸지만 잘 되니깐... 그래도 여기는 그나마 나름 네트워크를 복잡하게 구성하기도 했고 어쨌든 이미지 단위로 샘플링을 진행을 했다라는 점에서 사실 안 되는게 크게 이상하지는 않았다. 물론 이 논문이 어떻게 시작됐는지는 모르지만 나라면 당연히 실험을 해보는 과정에서 ReLU base로 시작을 해서 성능이 안나와서 실망했을 법한테 SIREN 끌고와서 좋은 결과 낸 건 되게 고무적인 것 같다. (근데 후속논문들 다 보니까 그냥 SIREN이 default네?)
Training Spec
Resolution: 128X128
GPU:RTX 8000, RTX 6000
GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields(CVPR2021)
StyleNeRF: A Style-based 3D-Aware Generator for High-resolution Image Synthesis(ICLR2022)
CIPS-3D: A 3D Aware Generator of GANs Based on Conditionally-Independent Pixel Syntehsis(arxiv 2021)
본 모델은 CIPS(CVPR 2021)에 후속작(저자는 안 겹친다)처럼 나온 논문으로, 간단히 요약하면 얘 역시도 NeRF 기반으로 Low-Resolution Feature Map 생성 후, CNN based Decoder 태워서 Image를 생성한다는 방식이다. 사실 CIPS 자체를 읽어보지 않아서 Pixel Synthesis의 개념은 이해하지는 못했지만 여기서 INR을 어떻게 사용했는지 정도는 충분히 이해할 수 있었다.
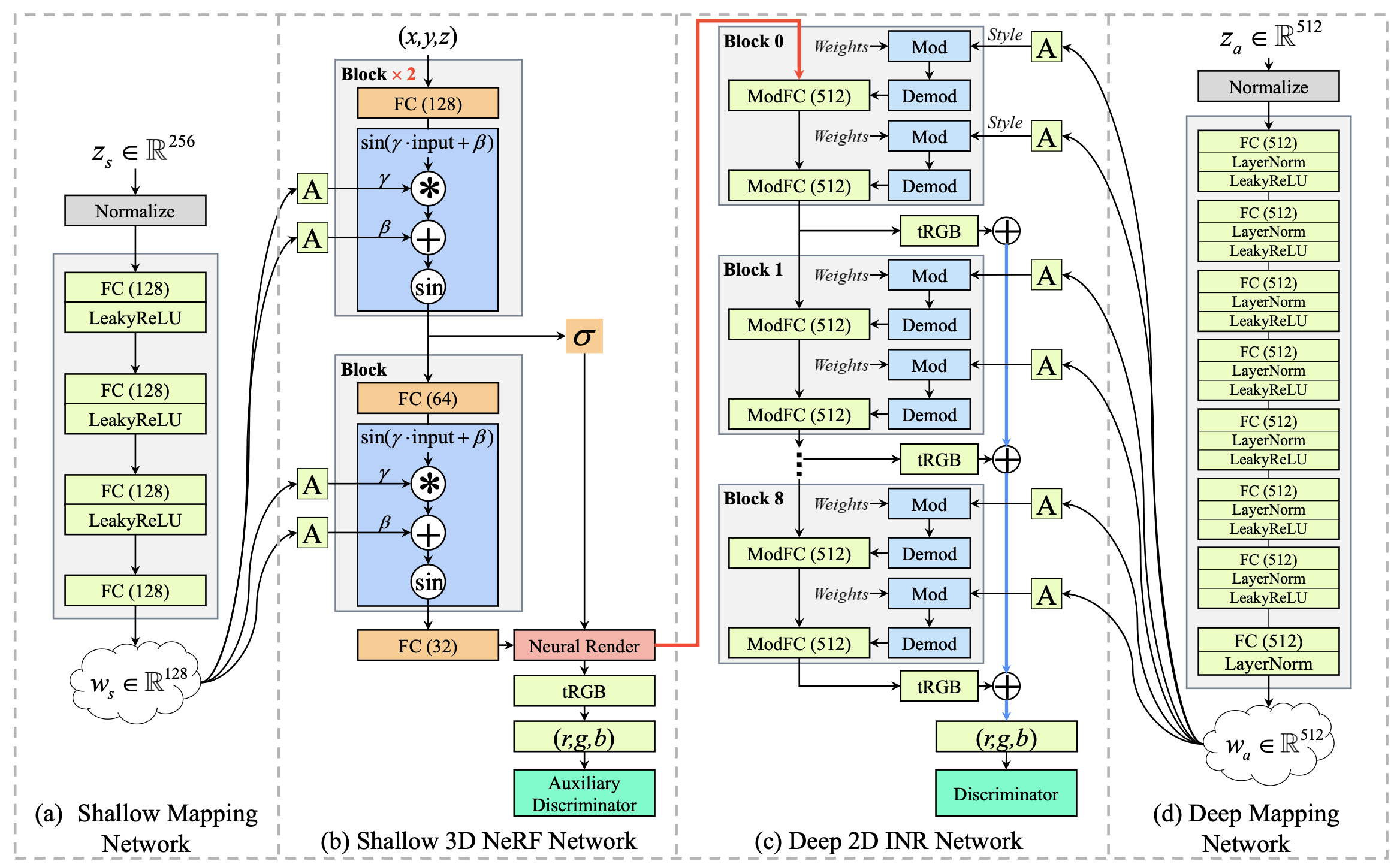
크게 모델은 Shallow / Deep으로 나뉘어지는데, Shallow 부분은 pi-GAN과 구조가 거의 유사하다. 다만 차이가 있다면 pi-GAN은 이 자체로 Image 자체를 생성했다면, 여기서는 해당 과정으로 Low-Resolution Feature map만 생성한다, 이후 해당 Feature Map을 우측 Deep INR Network를 태워서 Image를 생성한다고 한다. 이 과정에서 CIPS 자체에서 사용한 ModFC를 활용했고 여기서도 추가로 latent가 매 Layer에 들어간다. 그리고 최종적으로각 Block에서 나온 tRGB 결과값을 합쳐 최종 이미지를 생성한다.

다만 좀 특이한 점은, 여기서 Mirror Symmetry라는 문제점을 지적했는데 이 현상은 위 그림과 같이 사람 얼굴이 Mirror와 같이 대칭성을 띄고 있는 현상을 말한다. 또 특이한 점은 이 현상이 GIRAFFE나 본 모델에서만 관측되고 pi-GAN같은 모델에서는 관측되지 않는다는 점이다. 해당 논문은 이 문제가 3D 정보를 담고 있는 NeRF base Network와 Discriminator 사이에 2D network가 존재할 시 발생한다고 언급하였고 이를 위한 추가적인 Auxiliary Discriminator를 도입하였다. 그래서 위 그림 (b)를 보면 Shallow Network도 그 자체의 결과에 대해서 tRGB를 거쳐 loss를 받고 있는 것을 확인할 수 있다. 그리고 위 (c),(d)를 보면 이런 현상을 어느정도 해결했음을 알 수 있다.
또한 추가적으로 본 논문은 FC Layer기반이라 깡으로 돌리면 메모리가 박살이 나서 Scene의 일부분만 학습을 하는 형식의 Partial Gradient Backpropagation 방법론을 택했다고 한다.
후기
결국 이 논문도 3D information인 는 NeRF 기반으로 작동하고 2D information인 는 CNN based Decoder 기반으로 작동한다. 그 과정에서 StyleGAN의 구조를 굉장히 많이 따라간 걸 볼 수 있었다.
어제 다른 논문들 읽어보면서 3D(NeRF) + 2D
(CNN) 조합에 대해 사람들이 놓친 부분을 잘 캐치하면 괜찮지 않을까라고 생각했는데 그 중 하나다.
Training Spec
Resolution: 512X512(Partial로 400X400)
GPU:V100 8개
3D-aware Image Synthesis via Learning Structural and Textural Representations (arXiv 2021)
