CVPRW!
방학 때 나름 유의미한 실험과 결과를 만들어내서 이쪽 기반으로 뭔가 하나 해보자! 라는 느낌으로 학기 중 목표를 하나 잡았었다. CVPR에 Synthetic Data를 기반으로 머신러닝을 해보자라는 Workshop을 사수 형에게 소개를 받아서 죽이 되든 밥이 되든 요기 뭐 하나 내보자!를 1학기 목표로 해보려고 했습니다... Deadline은 6/19!

결론부터 말하면 올해에는 not accept paper라고 한다... 헤헤... 물론 이거 된다! 싶은 아이디어는 아직 없었지만 그래도 막상 잡았던 목표가 사라지니 가슴 한켠이 공허해진다. 그래도 그냥 두기는 아쉬우니 이번 포스팅으로 공부했던 내용을 정리해보려 한다.

Disentanglement in Classification
우선, 내가 가진 기술(?)에 대해서 차근차근 정리를 해보았다. 간단히 말하면 Latent Space 상에서 Disentanglement를 어떻게 활용할 수 있을까... 였는데 우선 Semantic Axis Disentanglement를 문제만 바꿔서 생각하면 Semantic하다라는 표현 자체가 Attibute Classification으로 그대로 옮겨갈 수 있겠다라는 생각을 했다. 그렇기 때문에 Disentangle Synthetic Data를 잘만 생성한하면 Attribute Classification에 유의미하게 활용할 수 있을 것 같아 이쪽 위주로 조사를 하기 시작했다.
그러다 자연스럽게 흘러간 생각인데 Disentanglement는 결국 Entangle 문제를 해결한 것인데, 이는 Classification 문제에서 bias로 볼 수 있을 것이다라고 생각을 했고(물론, 이 과정이 순수 내 뇌에서 진행된 게 아니라 다른 논문이 도움을 줬다라는 사실을 후에 깨닫는다.) 아무튼 Disentanglement -> Debiasing이라는 사고의 흐름에 도달할 수 있었다. 그래서 나는 Debiasing을 Synthetic Data로 해보고 말꺼야! 라는 목표를 갖고 이런 저런 논문을 조사해보았다. 꽤나 많은 논문을 조사했지만 아래는 그 중 메인으로 삼을 수 있는 두 논문에 대한 초간단 리뷰다.
How to debias?
Learning from Failure: Training Debiased Classifier from Biased Classifier
NIPS2020
우선 해당 논문에서 알게 된 사실은 크게 2가지다.
- Biased Dataset에 대해서 학습을 진행할 때 bias attribute와 target attribute가 둘 다 존재한다면 Classifier는 학습하기 쉬운 attribute부터 학습을 한다.
- Biased classifier를 학습시킨 후, classifier를 해당 biased classifier로부터 도망치도록 학습을 시키면 해당 classifier는 debiased classifier가 될 수 있다.
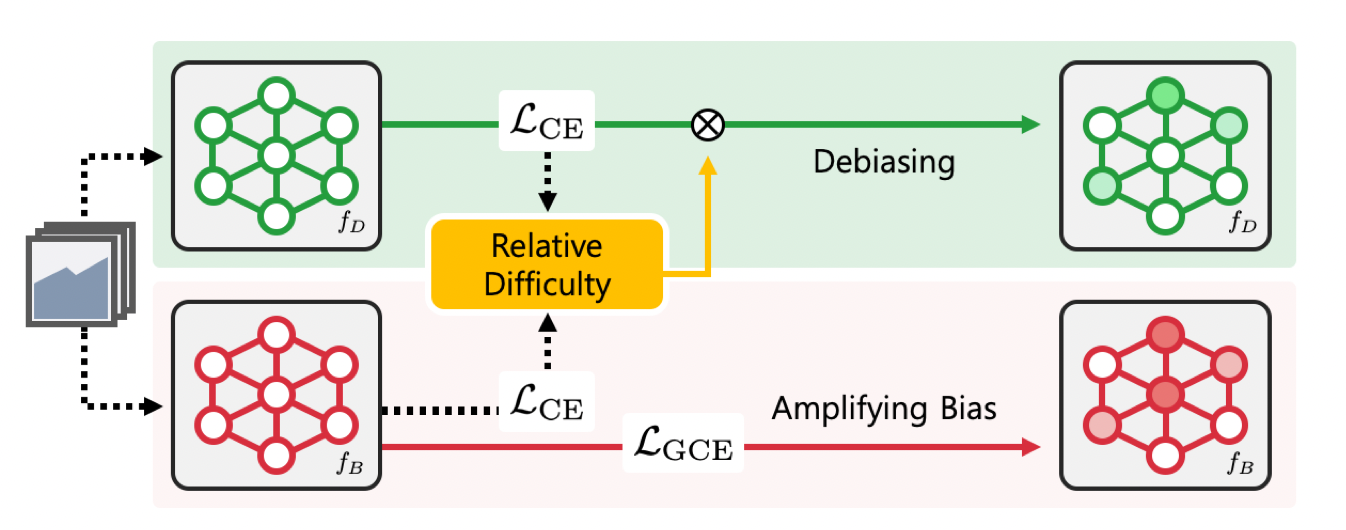
여기서 부연설명을 좀 더 하자면 biased classifier를 학습시키기 위해 등장하는 loss는 GCE라는 loss인데 수식적 내용은 빼고, 해당 loss는 bias를 먼저 학습한다고 한다.
다음은 도망친다라는 표현에 대한 설명인데 말 그대로 Bias에 대한 정보를 최대한 덜 학습시킨다라는 내용이고 이 과정은 Relative Difficulty라는 weight를 활용하는데, 식은 아래와 같다.
요 Weight를 Cross Entropy에 얹어서 biased data라고 판별되는 경우(Biased Classifier에 loss가 낮은 경우) 대해서는 적게 학습하도록 했다고 한다.
해당 논문에서 인상 깊었던 것은 bias에 대해서 정의를 하지 않고 문제를 풀었다는 점이다. 다른 논문들의 경우 bias가 무엇인지에 대한 정보를 준 경우가 많았는데 real dataset의 경우 bias가 무엇인지에 대해서는 알 수가 없는데 여기서는 단순히 bias-friendly loss를 사용하고 Relative difficulty를 활용함으로써 해당 문제를 풀었다는 점이 흥미로웠다.
Fair Attribute Classification through Latent Space De-biasing
CVPR2021
다음 논문은 되게 쉽고 내가 왜 생각을 못했지? 아니면 내가 공부를 1년만 더 빨리 생각했으면 아쉬웠던 그런 논문이었다.
방법론이 되게 간단하다.
- Target Attributes 들에 대해서 Hyperplane을 찾는다.
- Z를 Sampling한다.
- 각 Attribute를 뒤집은 Data를 만든다.
- 이미 존재하는 classifier로 labeling을 한다.
- 기존 Dataset에 얹어서 학습한다.
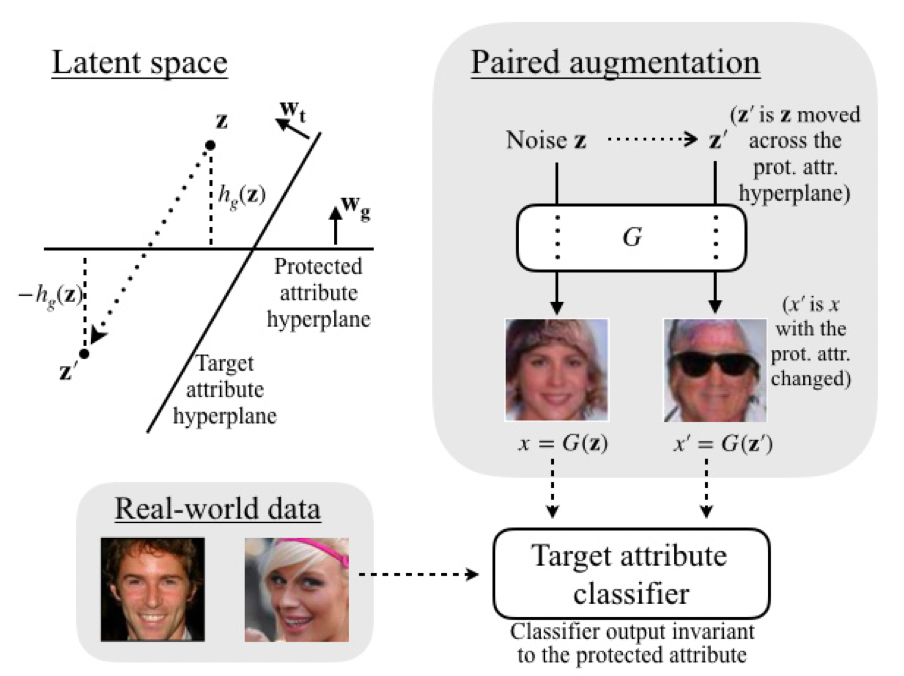
물론 labeling 과정에서 다른 classifier를 재활용한다는 점이 석연치 않았지만 성능은 얼추 나오는 듯하다.
또 근데 논문을 자세히 읽어보면 다양한 실험을 진행하고 다양한 지표를 활용해서 이러한 점은 배울만하다고 생각을 했다.
My Idea
아무튼 그래서 진행해보려 한 아이디어는 LfF에서 Bias Amplification을 Loss를 기반으로 진행하지만 나는 해당 부분을 Dataset 차원에서 Synthetic Data를 통해서 할 수 있지 않을까? 라는 아이디어였다.
하지만 근본적인 문제에 부딪혔는데, 위 논문은 우선 Bias에 대한 정의가 따로 되어있지 않고 알아서 찾아라 였지만, Dataset 차원에서 Bias를 합성하기 위해서는 Bias에 대한 정의가 필요했다. 이에 대한 해결책을 찾기가 좀 어려웠고 추가로 애초에 내가 가진 실험도구는 기반이 real-world dataset이지만 LfF 계열의 논문의 목표는 biased Dataset에서 학습시킨 classifier가 unbiased Dataset에서 test를 했을때 얼마나 성능을 보여주냐 였기에 결론적으로는 서로를 합치는 게 어려워 보였다. 또한 의미적으로도 굳이 얘네를 어거지로 합친 느낌을 지울수 없었는데 이는 줌에서 한번에 관통당해버렸다.(따흑)
Why? Why? Why?
그렇다, 문제는 정의조차 되어있지 않은데 무차별적으로 해결방안만 생각을 했다. 이걸 해보고 싶어요! 이걸 써보고 싶어요! 같은 생각들 위주로 논문 조사를 진행을 했지만 세상은 넓고 연구자는 많았다. 내가 해보고 싶은 것은 누군가가 이미 했고, 내가 써보고 싶은 거는 안 쓰는 이유가 다 존재했다. 그러다보니 결국에는 내가 뭘 하고 싶었지? 라는 생각까지 오게되었고 돌고돌아 처음부터 차근차근 진행하기 시작했다. 근데 이제 방향성을 좀 다르게 해서 뭘 하고 싶은지 보다 왜 하고 싶은지 위주로 생각을 시작했고 해결하고 싶은 문제가 무엇인가에 대해 생각하며 조사를 하기 시작했다.
2편에 계속...
Reference
[1] Junhyun Nam et al. Learning from Failure:
Training Debiased Classifier from Biased Classifier. NIPS2020.
[2] Vikram V. Ramaswamy et al. Fair Attribute Classification through Latent Space De-biasing. CVPR2021.

2편 존버중입니다...