아직 학생이기도하고 영어가 미숙하다보니 본 리뷰에 오류가 있을 수도 있습니다. 이 점 감안해주시고 혹시나 찾으신다면 피드백 감사히 받겠습니다.
Introduction
최근 몇 년간, real-time 기반의 markerless한 얼굴 표정 인식 기술에 대한 여러 발전이 있었습니다. 이 기술은 단순히 얼굴을 인식하는 것뿐만 아니라 CG, AR, VR 등 사용될 수 있는 용례가 다양해 많은 발전이 있었습니다.
해당 논문에서는 혁신적인 성능 발전을 제안하기 보다는 RGB data를 활용해 real-time으로 SOTA와 비슷한 성능의 모델을 생성했음을 제안하고 있습니다. 우선, 앞에서 언급한 얼굴 인식을 하는데 필요한 데이터는 크게 RGB와 RGB-D data를 사용하는데 깊이 데이터가 포함된 RGB-D의 경우는 잘 쓰이지 않는 Data이기도 하고 사용될 용례 자체가 적기도 합니다. 또한 본 가상의 인물의 얼굴에 표정을 이식하는 것이 아닌, 실제 재생중인 영상에 real-time으로 웹캠이 인식하는 사용자의 표정을 이식하는 기술을 제안하고 있습니다.
연구진의 방법에서는 우선 사전에 train 영상에서 non-rigid model을 기반으로 shape identity를 재현합니다. 이 과정이 training frame 전 과정에서 실행되기 때문에, geometric 쪽의 모호한 부분도 해결을 할 수 있었다고 합니다. 그리고 모델이 실행되는 동안에는 source와 target에서 expression을 tracking한 후, 새롭게 제안하는 expression transfer function을 통해 expression을 이식합니다. 그 후, 이렇게 조절된 expression coefficient를 기반으로 target의 얼굴을 다시 렌더링해줍니다. 이 과정에서 배경과 조명과 같은 요소들도 같이 고려됩니다. 마지막으로 입 부분에 대해서 이미지들을 기반으로 다시 합성을 해주어 좀 더 자연스럽게 사진을 연출해줍니다.
위와 같은 과정을 기반으로 감정이 전이된 이미지 합성을 해내고 있으며, 이 논문이 최초의 RGB 기반 real-time face reenactment라고 합니다.
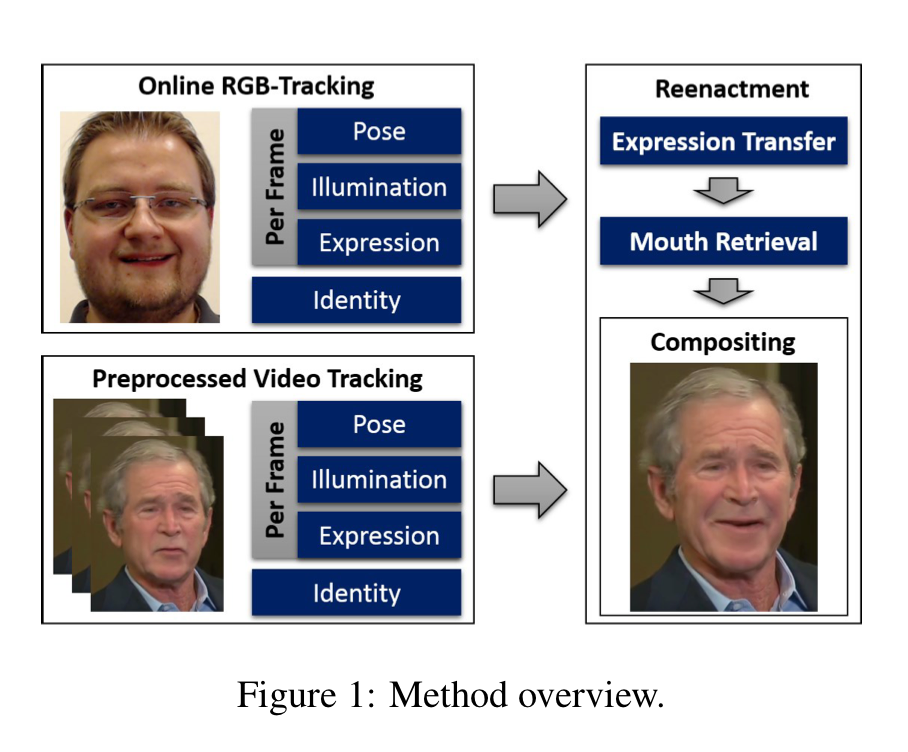
Synthesis of Facial Imagery
Face reenactment는 3DMM Model을 기반으로 진행됩니다.
shape과 texture(reflectance)의 평균을 나타내는 와 가 존재하고 그 뒤로 shape coefficient인 reflectance coefficient인 , Expression coefficient인 가 존재하고 관련된 표준편차 역시도 각 요소마다 존재합니다. 해당 모델은 53K개의 vertices와 106K개의 얼굴을 기반으로 구성되어 있으며 이렇게 합성된 얼굴 데이터는 rigid model transformation 와 full perspective transformation 기반의 모델로 rasterization되어 Image를 형성하고, 조명은 Labertian surface와 smooth distant illumination을 가정하고 self-shadowing을 무시한 SH basis function으로 예상한다고 합니다.
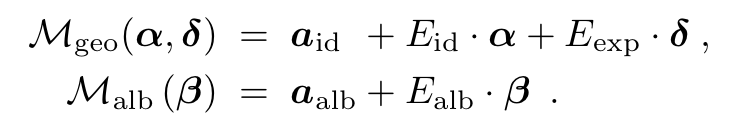
요약하자면 이미지 합성은 위 식에 있는 face model parameter인 illumination parameter인 , rigid transformation 와 camera parameter 총 7가지 종류의 파라미터들의 조합으로 이루어지고 앞으로는 이러한 파라미터들의 조합을 라고 표현하고 진행하겠습니다.
Energy Formulation
주어진 input에 대해서, 적당한 Parameter 조합 를 찾고 새로운 합성 이미지를 생성했을 때, objective function은 다음과 같습니다.
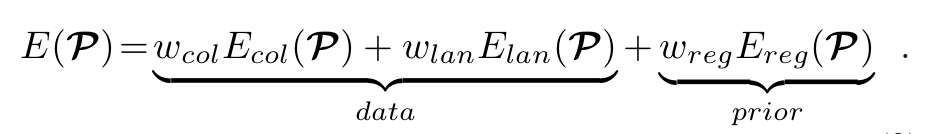
각 항에 존재하는 는 해당 파트에 대한 Energy Function으로 의 경우에는 photo-consistency를 의 경우에는 facial feature alignment를 의 경우에는 통계적 제약 요소를 의미합니다. 그리고 의 경우에는 가중치를 의미하는데 으로 설정했다고 합니다.
Photo consistency같은 경우는 아래 식을 통해 계산할 수 있다고 합니다.

간단하게 설명드리면 각 pixel position의 차이를 -norm으로 계산해주었다고 합니다. 이 방식은 least-square에 비해 outlier로부터 robust해서 사용했다고 합니다.
Feature Landmark의 경우에는 당시 sota facial landmark tracking algorithm을 차용해 각 feature point를 뽑아서 그 차이를 계산하는 형식을 띈다고 합니다. 자세한 과정은 아래식에 존재합니다.
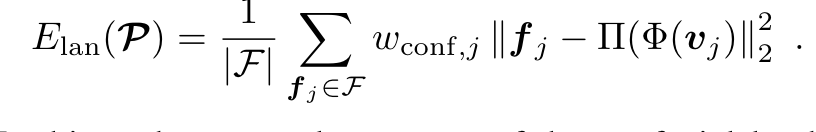
통계적인 제약 부분에 대한 내용은 계수가 너무 커지는 걸 방지한다는 정도로만 알고 있어서 아래 식으로 대체합니다.
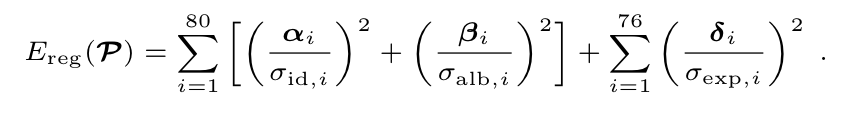
Expression Transfer
개개인의 얼굴의 특성은 살리면서 source의 감정을 target으로 이식하기 위해 연구진은 sub-space deformation technique을 활용했습니다. real-time 연산을 제공하기 위해 최적화 식의 차원은 줄이면서 사전 연산도 허용하는 형식으로 진행됐습니다. source identity를 , target identity를 로 설정하고 이를 고정합니다. 그 후, neutral한 source parameter 와 deformed된 , 그리고 neutral한 target parameter 와 deform된 을 transfer의 input으로 삼습니다. 그리고 를 output으로 삼고 최종 model 생성에 사용합니다. 기존 deformation에서 사용했던 것처럼 source deformation gradients 를 계산해냅니다. 그 후, deformed target 을 를 기반으로 선형 최소 자승법을 통해 찾아냅니다.
해당 부분은 R. W. Sumner의 Deformation transfer for triangle meshes 논문에 기대는 부분이 많아서 읽어보고 나중에 수정해야 될 것 같습니다. 지금으로서는 이해가 되지 않는 부분이 많네요.
Mouth Retrieval
이렇게 expression을 이식 한 후, 연구진은 mouth 부분을 좀 더 현실적으로 합성하였습니다. 해당 방법으로는 가장 잘 어울리는 mouth image를 찾아서 warping하는 방식을 택했습니다. 그리고 이 mouth image는 target으로 사용하는 video의 frame으로부터 얻었고 이러한 방식은 다른 source mouth 기반 이미지 합성이나 3D teeth 합성 방식보다 더 사실적인 결과를 내고 있다고 합니다. 그리고 real-time 기반으로 처리를 진행하기 위해 frame들을 clustering해서 찾는 방식을 사용했습니다.
가장 잘 매칭되는 이미지를 찾기 위해서 geometric, photometric feature들을 사용해 distance를 측정했습니다. rotation paramter , expression parameter , landmarks , Local Binary Pattern(LBP) 로 합쳐서 형태로 이러한 요소들을 조합하여 비교했다고 합니다. 그리고 그 식은 다음과 같습니다.
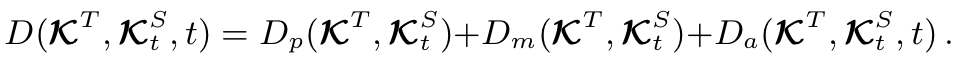
그리고 해당 Distance 계산 식의 세부 부분은 다음과 같습니다.
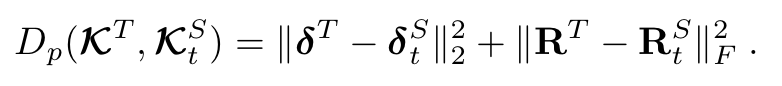

윗 부분들은 단순한 L2-distance 계산정도로 보면 될 것 같습니다. 다만 아래 부분은 좀 다르게 계산이 됨을 확인할 수 있습니다.

해당 식에서 은 카이제곱 분포에 의해 비교되는 LBP기반으로 유사도를 측정하는 식이라고 합니다. 는 이전 frame에서 reenactment에서 사용되었던 frame 정보입니다. 는 이 와 t 간의 similarity를 측정하는 식이라고 합니다. 또한 frame간의 입모양의 변화를 자연스럽게 하기위해 를 으로 설정하며 조절했다고 합니다.
그리고 이러한 과정을 frame to frame으로 진행을 할 경우에는 real-time service가 불가능하기때문에 k-means clustering algorithm을 통해 mouth frame을 clustering한 후, 각 cluster마다의 대푯값들과 function을 통해 비교하고 cluster 내부에서 가장 유사한 frame을 찾는 형식을 띈다고 합니다.
Result

Reference
Face2Face: Real-time Face Capture and Reenactment of RGB Videos
